

はじめに
テクノロジー戦略本部データサイエンス部データアナリストの西川です。普段はPythonやRを使って、事業部の方と一緒にデータ分析を行なっています。
データアナリストというポジションはデータ分析やBIツールを使ったダッシュボード構築をイメージすることが多いと思いますが、バイセルのデータアナリストはデータ分析だけではなく、アナリティクスエンジニアリング業務も行なっています。
アナリティクスエンジニアリング業務の1つにDatabricksを使って社内外のデータをBigQuery(以下、BQ)に集約する業務があります。
今回はバイセルがDatabricksを使って行なっているアナリティクスエンジニアリング業務についてご紹介したいと思います。
Databricksを使った実例が見つからず悩んでいる方やアナリティクスエンジニアリングに興味があるデータアナリストの方の参考になれば嬉しいです。
背景・課題
各プロダクトのRDBはデータエンジニアがBQに同期しているのですが、ExcelやCSV、Googleスプレッドシート(以下、GSS)のデータや外部ツールのデータはRDB、BQに格納されていないため事業部がデータ分析に活用しにくい状況でした。
バイセルのデータサイエンス部はSSOT(Single Source of Truth:信頼できる唯一の情報源)を目指していて、このアナリティクスエンジニアリング業務はSS部分を実現するための業務になります。
SSOTについて詳しく知りたい方は以下の記事をご確認ください。
そもそもDatabricksって何?
本題に入る前に、Databricksって何?という方もいらっしゃると思うので、データアナリスト観点で簡単にDatabricksについて触れておきたいと思います。
Databricksは、Databricks社が提供している分析プラットフォームになります。バイセルがメインで使用しているETLの他、分析や可視化などをDatabricks上で行うことができます。
Databricks Notebookと呼ばれる開発環境でコマンドを実行していくのですが、UIはJupyter Notebookと似ているため非常にシンプルで使いやすいです。

NotebookはPython、R、SQL、Scalaに対応しているのですが、複数の言語をNotebook上で使い分けできる点が非常に便利だと感じています。例えば、PythonでAPIを実行し、取得したデータをデータフレーム化した後、SQLで整形して、Rで分析するなんてことも可能です。
最終的にはBQにデータを集約するのですが、BQに入れるほどではないデータや、BQに入れる前段階のデータなどはDelta Lakeに保存することが出来ます。
Delta LakeとはDatabricks社が公開しているオープンソースのストレージレイヤーです。データアナリスト観点だと、ACIDトランザクションをサポートしているため、データの整合性と信頼性を確保してくれる点が1番の利点だと思います。その他にも、スキーマの柔軟性やバッチ処理とストリーミング処理を総合的に扱える点など、様々な利点があります。
バイセルのDelta Lakeは、Databricks社が提唱するメダリオンアーキテクチャの考え方に沿ってGold(ゴールド)・Silver(シルバー)・Bronze(ブロンズ)の3つのレイヤーに分けられていて、データの性質によってどの層に保存するのか決めています。
データが分散してしまうことを懸念される方もいますが、Delta Lakeを補助的に使用することで懸念点を解消しています。
詳しくは、Databricksとメダリオンアーキテクチャについて説明している以下の記事をご確認ください。
では、次項より具体的な活用事例をご紹介します。
具体的な活用事例
例1.Google Search Console APIを利用した各サイトデータの自動取得
課題
バイセルのマーケティング事業本部ではGoogle Search Console(以下、Search Console)を使って各ウェブサイトのパフォーマンス分析を行なっています。
Search ConsoleのデータがRDBやBQに格納されていなかったため、分析に必要なデータをSearch ConsoleからCSVでエクスポートし、ExcelやGSS上でBQから取得したその他のデータと突合していました。
スポット的な分析や管理するサイト数が数個であれば上記の対応でも問題ありませんが、バイセルの場合は数多くのサイトのパフォーマンス分析を日々行なっているため、データ処理が煩雑化していました。
解決方法
そこでDatabricks上でGoogle Search Console APIを使って、分析に必要なデータを取得、整形を行った上でBQに格納する仕組みを構築しました。
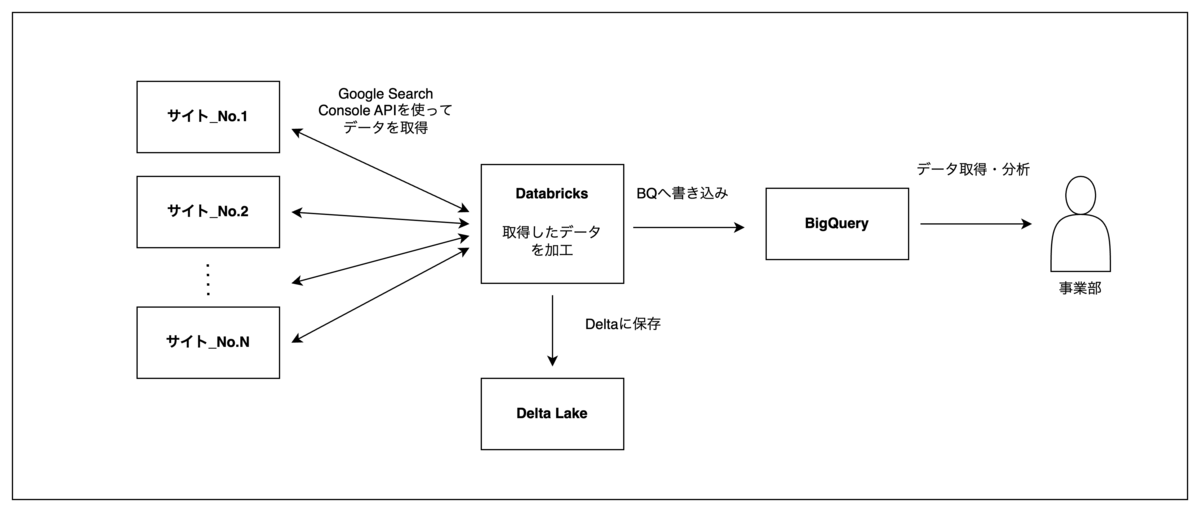
APIを利用して取得したデータとSearch Console上で確認できるデータの整合性を確認しながらリクエスト時に渡すパラメータ等をマーケティング事業部の方と一緒に決めていきました。
Databricks上で上記ジョブの実行をスケジュール管理しています。毎日指定した時間に前日1日分のデータが取得され、BQに格納される仕組みになっています。データ量が大きい場合でも、安定して毎日データをBQに取り込むことが出来ています。そのため、マーケティング事業本部は常に最新のSearch ConsoleデータをBQから取得できるようになっています。
例2.RDBやBQに連携できないツールからエクスポートしたCSVの自動取込
課題
バイセルではCTIツールを活用して、お客様からいただいたお問合せを対応しています。CTIツールを活用することで、応対者や応対時間などオペレーション向上のためのデータを取得できます。しかし、現在使用しているCTIツールとデータ基盤が連携していなかったため、BQを使ってデータ分析をすることが難しい状況でした。
これまではCTIツールからCSVをエクスポートし、GSS上でデータを加工した上でデータ集計や分析を行なっていました。
解決方法
使用しているツールの仕様上、CTIツールからCSVをエクスポートする部分の自動化ができなかったため、今回はCSVを加工しBQへ格納する部分を自動化させることになりました。
仕組みとしては、エクスポートしたCSVを指定のGoogleドライブのフォルダに格納してもらい、Databricks上でGoogle Drive APIを利用してCSVデータを取得、加工を行った後、BQに格納するというフローになります。
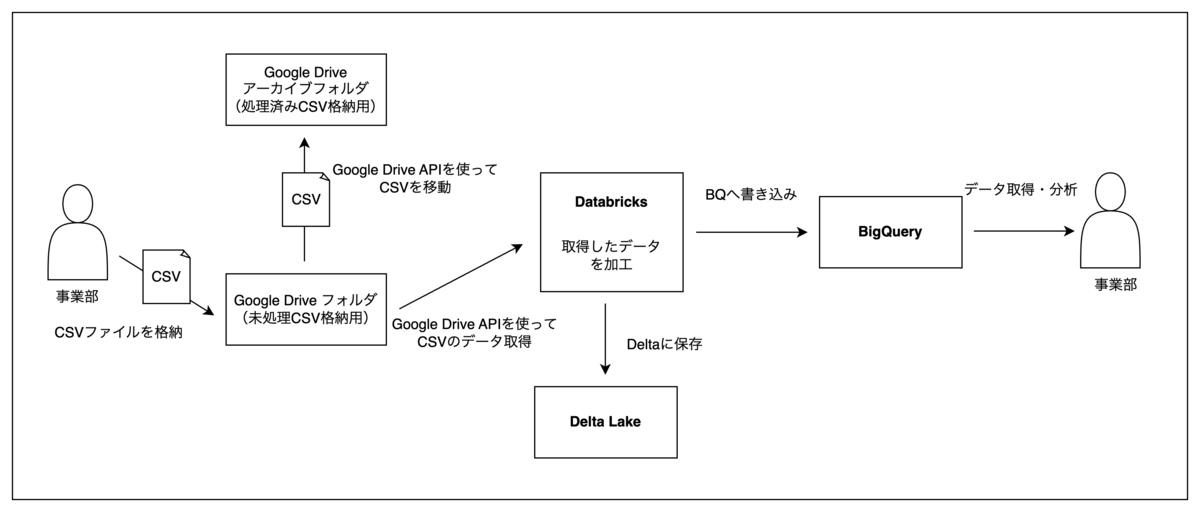
BQに格納されたCSVデータは処理の中で別のアーカイブフォルダに移動させるため、どのCSVがBQに格納されているのか、格納されていないのかが視覚的に分かる仕様にしました。
これらの処理は毎日指定した時間にジョブが実行されるようスケジュール管理しているため、事業部は最新のCTIの応対データとバイセルの顧客情報を結合してBQから取り出せるようになっています。
また、指定フォルダに格納されていないCSVファイルがあるかどうかを検知する処理も構築しました。CSVデータの格納漏れがあれば事業部へSlack上で通知を行い、通知を受けた事業部はCTIツールから対象の日付のCSVをエクスポートし、指定フォルダに格納する仕組みです。
事業部がCSVを格納し忘れることは少ないのですが、念の為に週に1回ジョブを実行するようにスケジュール管理しています。
例3.スプレッドシートで管理しているマスタデータや集計データの時点データ取込
課題
バイセルでは各事業部が独自のマスタや集計表をGSSを使って管理しています。それらのGSSには、更新頻度が高いマスタ、その時点での社員情報や関連データが載っているマスタ、走っているPJによってカラム数が異なる集計表など、管理が難しい性質のデータが含まれていました。
解決方法
そこでDatabricksを使ってGSSで管理されているマスタや集計表をデータ取得時点でのデータとしてBQに格納する仕組みを構築しました。
カラム数が取得時点で異なる性質のマスタに関しては、固定カラム以外のカラムをJSON形式でまとめてBQに格納することで、カラム数が増減した場合でも対応できるよう工夫しました。
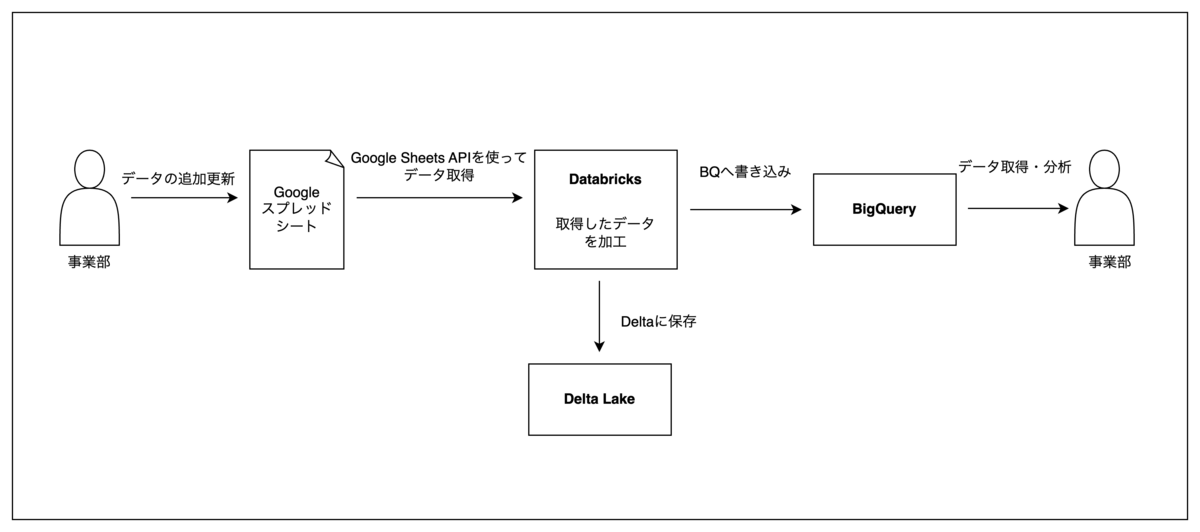
こちらの仕組みを活用することで、新規プロジェクトやトライアルを行うときにGSSをマスタや集計表として活用し、BQに蓄積された時点データを使ってデータ分析を行うことが可能になりました。
エラー時の対応について
もしDatabricksでスケジュール管理しているジョブがエラーとなった場合、Slackで通知される仕組みになっており、データアナリストが気づけるようにしています。 次の1.と2.のどちらのタイミングでエラーとなったかによって、対応方法が異なってきます。
Databricks上の処理でエラーが発生し、Delta Lakeに書き込みができなかった場合
エラーを解消した後、Databricks上でジョブを最初から手動で実行します
Delta LakeからBQへ書き込む処理でエラーが発生し、BQに書き込みができなかった場合
Delta Lakeにはデータが書き込みができているため、エラーを解消した後、Databricks上で「Delta LakeからBQに書き込む処理」を手動で実行します
冪乗性を担保できるよう実装しているので、エラーが起きた場合は上記の1.または2.の方法で対応しています。
まとめ
バイセルではDatabricksを活用することで柔軟に社内外のデータをBQに集約できるようになりました。BQにデータを集約することで、事業部側のデータ分析が活性化されると同時に、データアナリスト自身もいろいろな場所にデータを見にいく必要がなくなり、データ分析業務が捗るようになりました。
今回はDatabricksの「ETL」についてフォーカスを当てましたが、データ分析においてもDatabricksは非常に便利なので、機会があればまたDatabricksを使ったデータ分析業務についてご紹介したいと思います。
現在、データアナリストとしてデータ分析を行いつつ、Databricksを活用したアナリティクスエンジニアリングを一緒に進めてくれる仲間を絶賛募集しています!気になる方は是非ご検討ください!