

はじめに
テクノロジー戦略本部データサイエンス部データアナリストの森山です。
バイセルでは事業部組織(以下、Biz メンバー)が自立してデータに基づいた意思決定を行うことを目的に、データ基盤を整備しグループの全社員に公開しています。
Biz メンバーは自分自身で SQL を書きデータ基盤から必要なデータを抽出しますが、そのためには基盤に蓄積したデータを必要な形式に変換・加工(以下、データ変換パイプライン)する必要があります。
今回は、データ変換パイプラインの構築のために導入した Google Cloud が提供する Dataform の利用事例をご紹介します。
Dataform をこれから活用しようと思っている方、実例が見つからず悩んでいる方の参考になれば幸いです。
※なぜ Biz メンバーが SQL を書く環境を整備しているかは、以下の記事をご確認ください。
- はじめに
- Dataform とは?
- Dataform 導入の背景と抱えていた課題
- Dataform を使った開発の準備
- Dataform 導入の結果
- Dataform 導入の過程でつまずいたところ
- 残る課題
- まとめ
Dataform とは?
Dataform はデータ変換パイプラインを開発・運用するためのサービスです。Google が 2020 年に買収し、2023 年 4 月に Google Cloud で GA になりました。 詳細は公式ドキュメントをご確認ください。
Dataform 導入の背景と抱えていた課題
背景
バイセルでは、Google Cloud が提供する BigQuery でデータ基盤を構築しています。
データ基盤の構築はデータエンジニア・データアナリストが役割分担をして行っており、大まかな管理範囲は以下です。
- 各プロダクトからデータ基盤にデータを流し込む部分(下図データレイク)はデータエンジニア
- データ基盤に流し込まれたデータを Biz メンバーに提供する部分(下図データマート)をデータアナリスト
執筆者はデータアナリストなので管理の対象は Biz メンバーに提供する部分(データマート)です。下図が管理範囲のイメージです。

幅広いデータを Biz メンバーに活用いただくため、データの種類も複数用意しています。
例えば、SQL を実行した瞬間の最新のデータや、ユーザーが指定した特定の時刻・日付時点のデータです。
また、一部のプロダクトはテーブル構造が複雑でハードルが高いので、Biz メンバーが集計分析しやすいよう加工を施したデータも提供しています。
提供するデータの種類に合わせて提供形式も複数用意しています。主に使用しているのは、BigQuery の View テーブルやテーブル関数です。
前述した管理範囲のイメージのデータマート部分をより詳細にすると下図になります。
(厳密にはデータエンジニアが用意するデータレイクの時点で様々な種類・形式のデータが存在しますが、下図では割愛します。)
なお、グループ全社(執筆時点では 3 社)にこれらのデータを提供するため、6000 を超えるテーブル・テーブル関数がデータアナリストの管理対象で、今後もデータ活用のニーズに合わせて増える予定です。

※この記事の内容とは異なりますが、データ基盤にはプロダクト以外のデータも集約しています。これは Dataform ではなく、Databricks というツールを利用して自動化しているので、よろしければ以下記事をご確認ください。
課題
前述のとおり管理すべきものが多い一方、それに見合った管理をする仕組みがありませんでした。具体的には以下です。
- コード(SQL)管理
- GitHub でコード管理しているものの、BigQuery にデプロイする仕組みがなくコンソール上で手動対応しており改修時の工数が最低でも 5 人日でした。
- 加えて管理すべきデータが増加したことで、開発が追い付かない状況でした。
- スケジュール管理
- BigQuery のスケジュールクエリを使用していましたが、こちらもコンソール上で手動対応しておりコード同様全く管理ができていませんでした。
- データの依存関係と改修時・障害発生時の影響範囲把握
- 変換したデータの依存関係を確認するためには、SQL を一つずつ確認するしかありませんでした。
- コードを修正した場合にどこにどんな影響がでるか把握しづらく、改修時・障害発生時に影響範囲の把握と対応完了に膨大な時間がかかっていました。
なぜ Dataform にしたか
課題を解決するにあたり、求める機能を整理しました。
- GitHub でコード管理できること
- コードを BigQuery にデプロイできること
- スケジューリングができること
- エラー検知ができること
- テーブル同士の依存関係を可視化できること
- コードの再利用ができること
上記が解決できるツールがないか調べると Dataform とdbtが検討対象に挙がりました。
バイセルでは、
- データ基盤が BigQuery で構築されていること
- Dataform 自体は無料で導入できること
- 学習コストが低いこと
- Dataform は SQLX という SQL のオープンソース拡張機能を主要なツールとして使用するため、SQL の知識があれば比較的容易に導入可能です。
これらを加味して Dataform を導入することにしました。
SQLXに関しては以下公式ドキュメントをご確認ください。 cloud.google.com
Dataform を使った開発の準備
手順
簡単に事前準備の手順を記します。
- Dataform リポジトリの作成
- Dataform API を有効化

- Dataform リポジトリを作成

- 任意のリポジトリ ID・リージョンを選択

- Google 管理サービスアカウントが発行される
- 後ほど利用するので、どこかに控えます

- 後ほど利用するので、どこかに控えます
- 完了ボタンを押下
- 任意のリポジトリ ID・リージョンでリポジトリが作成されたことが確認できます

- 任意のリポジトリ ID・リージョンでリポジトリが作成されたことが確認できます
- Dataform API を有効化
- Dataform 開発ワークスペース(ブランチ)の作成
- リポジトリ ID を押下

- CREATE DEVELOPMENT WORKSPACE を押下

- 任意のワークスペース ID(ブランチ名)を記入

- 作成されたワークスペース ID(ブランチ名)を押下

- ワークスペースを初期化を押下

- 完了
- definitions
- SQL ワークフローの要素を作成するコードを格納
- 初期はサンプルコード(SQLX ファイル)が 2 つ作成される
- includes
- リポジトリ全体で再利用できるグローバル定数または関数を格納
- 直下
- デフォルトで作成された Dataform の構成ファイル

- デフォルトで作成された Dataform の構成ファイル
- definitions
- リポジトリ ID を押下
- GitHub の準備
- リポジトリを作成
- Personal access tokenを発行
- Secret Manager の準備
- Secret Manager API を有効化

- シークレットを作成を押下

- 任意のシークレット名・GitHub で発行した token を記入

- Secret Manager API を有効化
- GitHub リポジトリを Dataform に連携
- Dataform リポジトリを開き SETTING を押下

- GIT と接続を押下

- GitHub リポジトリの URL・デフォルトブランチ名・作成したシークレットを選択
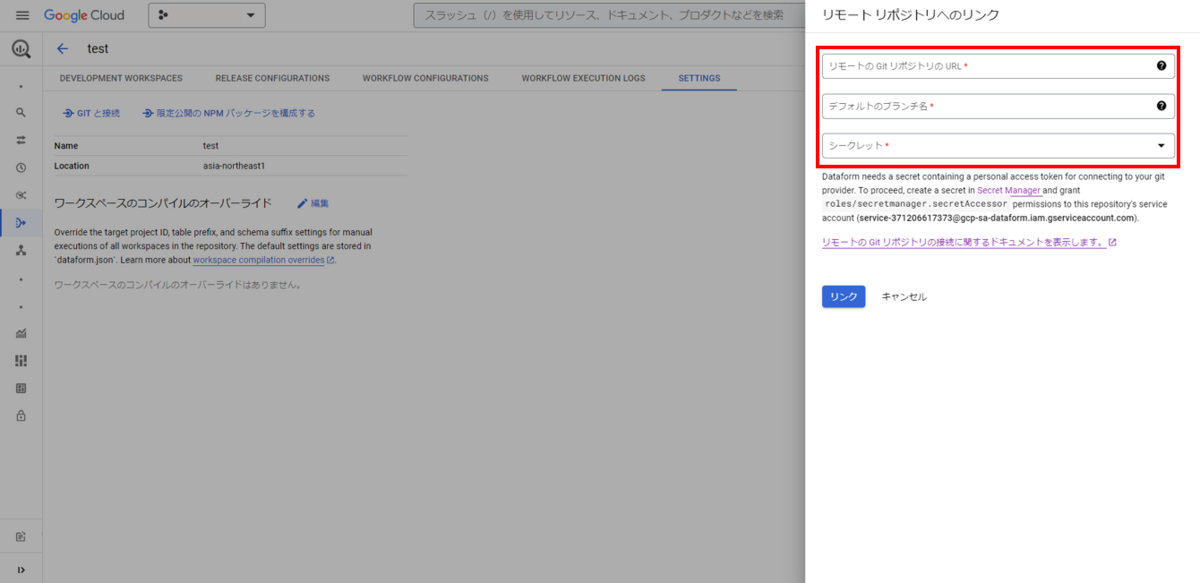
- リンクを押下して接続内容を確認

- Dataform リポジトリを開き SETTING を押下
- Dataform サービスアカウントに BigQuery の権限を付与
補足
- 既存の GitHub リポジトリと Dataform を連携することも可能です。
- Dataform のワークフロー実行は全て作成された Google 管理サービスアカウントで行われます。ユーザーアカウント、ユーザー管理サービスアカウントで実行することは執筆時点ではできません。
- 執筆時点の手順です。最新の情報は公式ドキュメントを参照してください。
Dataform 導入の結果
結果として Dataform 導入前に挙がっていた課題はほぼすべて解決し、改修時の工数を最低 5 人日から 1 人日程度に削減することができました。
ここでは実装内容をそれぞれ記します。
アーキテクチャ
Dataform を使った開発の準備の後、Dataform の公式ドキュメントを読み進めながら、以下構成にしました。

Dataform
コードの階層化

Dataform で開発したコードは、階層化して管理しています。
依存関係を ref 関数の引数として宣言するだけでなく、ディレクトリをワークフロー構造に沿って階層化することで整理がしやすくなりました。
JavaScriptを使った繰り返し処理
繰り返し処理を行う必要のある SQL ワークフローは SQLX ではなく JavaScript で開発しています。SQL の構文は同一だが参照するデータが異なる・出力する形式が異なる、というコードを個別に管理する手間を省くためです。
以下が実際のコードです。
// definitions/01_sources/hourly.js const info = product_a_info.values; //後述するproduct_a_info.jsファイル const company_array = ["company_a", "company_b", "company_c"]; const table_array = info.table_names; const table_type = "table"; const create_project = "テーブル・テーブル関数を作成するプロジェクト"; const create_dataset = info.create_dataset; const tag = "hourly"; const select_project = info.select_project; const select_dataset = info.select_dataset; company_array.forEach((company) => { table_array.forEach((table, i) => { publish(table) .type(table_type) .database(create_project) .schema(create_dataset[company]) .tags( tag + "_" + Math.floor(i / 50) .toString() .padStart(2, "0") ) //50テーブル毎に接尾辞を付与、'hourly_00', 'hourly_01'のイメージ。(理由は後述) .query( (ctx) => "SELECT * FROM `" + select_project + "." + select_dataset[company] + "." + table + "`" ); }); });
コードの再利用
複数のコードが共通して参照するコードは includes に格納しています。
参照するデータレイクの情報(プロジェクト・データセット・テーブル・プロダクト特有の引数、例えば会社コードなど)をプロダクトごとに JavaScript ファイルにまとめてあります。
// product_a_info.js const values = { system: 'Product_A' ,select_project: '***' ,select_dataset: {// テーブル・テーブル関数を構成するSQLで参照するデータセット company_a: 'companyA_dataset', company_b: 'companyB_dataset' } ,create_dataset: {//テーブル・テーブル関数を作成するデータセット company_a: 'companyA_dataset', company_b: 'companyB_dataset' } ,table_names: [ //プロダクトが持つテーブル名一覧 'table_a', 'table_b', 'table_c', 'table_d', 'table_e', 'table_f', 'table_g' // 実際には数百テーブルある ] }; module.exports = { values };
依存関係の宣言
コード上で依存関係を ref 関数の引数として宣言すると、
- コンパイルされたグラフが自動生成される
- 依存者・依存関係を考慮してワークフロー実行できる
ので、とても便利です。 コンパイルグラフは、2023/6/19 にフィルタリングも可能になりました。
SQL ワークフローのスケジューリング
スケジューリングについては、導入当時以下 2 つの選択肢がありました。
- Cloud Composer での実行をスケジュールする | Dataform | Google Cloud
- Workflows と Cloud Scheduler を使用して実行をスケジュールする | Dataform | Google Cloud
Cloud Composer は過去に処理が詰まって実行しきれず利用を停止した経緯があり、バイセルでは Workflows と Cloud Scheduler を使うことにしました。
Workflows のソースコードは以下です。
テーブル・テーブル関数によって実行日時が異なるので、コンパイルするリポジトリ・実行タグは Cloud Scheduler のランタイム引数に設定しています。
なお、Workflows がコンパイルするのは GitHub 上のコードなので、マージしていないコード(Dataform 開発ワークスペース上で編集中の内容など)は実行対象外です。
// Cloud Scheduler ランタイム引数 { "repository_name": "リポジトリ名", "tags": [ "タグ1", "タグ2", "タグ3", "タグ4", "タグ5" ] }
# Workflows.yaml main: params: [args] steps: - init: assign: - api: "https://dataform.googleapis.com/v1beta1/" - repository: ${"projects/***/locations/***/repositories/" + args.repository_name} - tags: ${args.tags} - sum: 0 - count_compilation_result: 0 - count_workflow_invocation: 0 - createCompilationResult: try: steps: - increment_count_compilation_result: assign: - count_compilation_result: ${count_compilation_result + 1} - log_before_call_compilation_result: call: sys.log args: text: ${"CompilationResult:" + string(count_compilation_result) + "回目"} severity: "NOTICE" - call_api_compilation_result: call: http.post args: url: ${api + repository + "/compilationResults"} auth: type: OAuth2 body: gitCommitish: main result: compilationResult retry: predicate: ${custom_predicate} max_retries: 5 backoff: initial_delay: 2 max_delay: 60 multiplier: 2 - roop: for: value: tag in: ${tags} steps: - createWorkflowInvocation: try: steps: - increment_count_workflow_invocation: assign: - count_workflow_invocation: ${count_workflow_invocation + 1} - log_before_call_workflow_invocation: call: sys.log args: text: ${"WorkflowInvocation(" + string(tag) + "):" + string(count_workflow_invocation) + "回目"} severity: "NOTICE" - call_api_workflow_invocation: call: http.post args: url: ${api + repository + "/workflowInvocations"} auth: type: OAuth2 body: compilationResult: ${compilationResult.body.name} invocationConfig: includedTags: - ${tag} result: workflowInvocation retry: predicate: ${custom_predicate} max_retries: 5 backoff: initial_delay: 2 max_delay: 60 multiplier: 2 - sleep: # この記述の理由は後述 call: sys.sleep args: seconds: 60 - getStep: assign: - sum: ${sum + 1} - complete: return: - ${sum} custom_predicate: params: [e] steps: - what_to_repeat: switch: - condition: ${e.message == "HTTP server responded with error code 400"} return: true - condition: ${e.message == "connection broken"} return: true - otherwise: return: false
エラー検知と Slack 通知
指定した条件に合致するログを検知し、Slack に通知しています。
(Workflows、Dataform でリソースが異なるので、それぞれ設定)
Dataform 導入の過程でつまずいたところ
基本的な設定は公式ドキュメントに沿って作業すればとても簡単だったのですが、実際に動かしてみると利用するサービスそれぞれの制限を考慮する必要がありました。
具体的につまずいたのは、
この 2 つの制限です。一度に更新するテーブル・テーブル関数の数が多いため、コードは問題なくともこれらの制限に当たってしまいました。
色々試しましたが、最終的に実行タグと Workflows のソースコードを工夫することで解消しました。 具体的には以下です。
実行タグに接尾辞をつける
Dataform のコード上で、テーブル・テーブル関数 50 個ごとに接尾辞(2 桁の番号)を自動付与しています。
definitions/01_sources/hourly.jsの以下記述が該当箇所です。
.tags(tag + "_" + Math.floor(i / 50).toString().padStart( 2, '0'))
ワークフロー呼出時スリープする
Workflows でワークフロー実行を呼び出す際、タグを 1 つ実行したら 60 秒停止してから次のタグを実行しています。
Workflows.yamlの以下記述が該当箇所です。
- sleep: call: sys.sleep args: seconds: 60
特定のエラーの場合は自動リトライする
処理が詰まると、コードに問題がなくともエラーが出る場合があります。
そこで、リトライすれば解消することが確認できたエラーの場合は、自動でリトライがかかるよう設定しています。
Workflows.yamlの以下記述が該当箇所です。
main: ~中略~ - createCompilationResult: try: steps: ~中略~ retry: predicate: ${custom_predicate} max_retries: 5 backoff: initial_delay: 2 max_delay: 60 multiplier: 2 - roop: ~中略~ - createWorkflowInvocation: try: steps: ~中略~ retry: predicate: ${custom_predicate} max_retries: 5 backoff: initial_delay: 2 max_delay: 60 multiplier: 2 ~中略~ custom_predicate: params: [e] steps: - what_to_repeat: switch: - condition: ${e.message == "HTTP server responded with error code 400"} return: true - condition: ${e.message == "connection broken"} return: true - otherwise: return: false
残る課題
事前に挙がっていた課題は解決しましたが、実装してみて出てきた課題があります。今後解消していきたい部分です。
- リポジトリの分割
- 管理するテーブル・テーブル関数の数が多くコンパイルに時間がかかることが多々あります。
- どこかでコンパイルの上限に当たる可能性が高いので、リポジトリの分割を検討しなければなりません。
- スケジュール管理
- Dataform 上でスケジュール管理が行えるようになったので、利用を検討しています。
まとめ
課題は残りますが、Dataform を使ってデータ処理の効率化を行うことができました。
執筆者はこういったツールの導入に初めてチャレンジさせて頂きましたが、ここまでできたのは Dataform が直感的で分かりやすいサービスだからだと思います。
また最後になりましたが、快くご協力くださったデータアナリストチームの皆さんにも大変感謝しています。
現在、データアナリストとしてデータ分析を行いつつ、Dataform を活用したアナリティクスエンジニアリングを一緒に進めてくれる仲間を絶賛募集しています。気になる方は是非ご検討ください。