

テクノロジー戦略本部データサイエンス部の近藤です。 バイセルはリユース事業を営む会社で急激な成長を遂げていますが、どちらかというと今まではテクノロジーにあまり頼ることなく成長してきました。 そんな中、テクノロジーをちゃんと導入していけばどこまで成長するのか試してみたく、2022年7月にバイセルに入社しました。
バイセルではSSOTの実現のために、RDBのデータをBigQueryにニアリアルタイムで同期する実装を進めていますが、 新たにDatabricksの導入を決めました。 バイセルにどういう課題があり、なぜDatabricksを導入するのかをお話しします。
SSOTとは
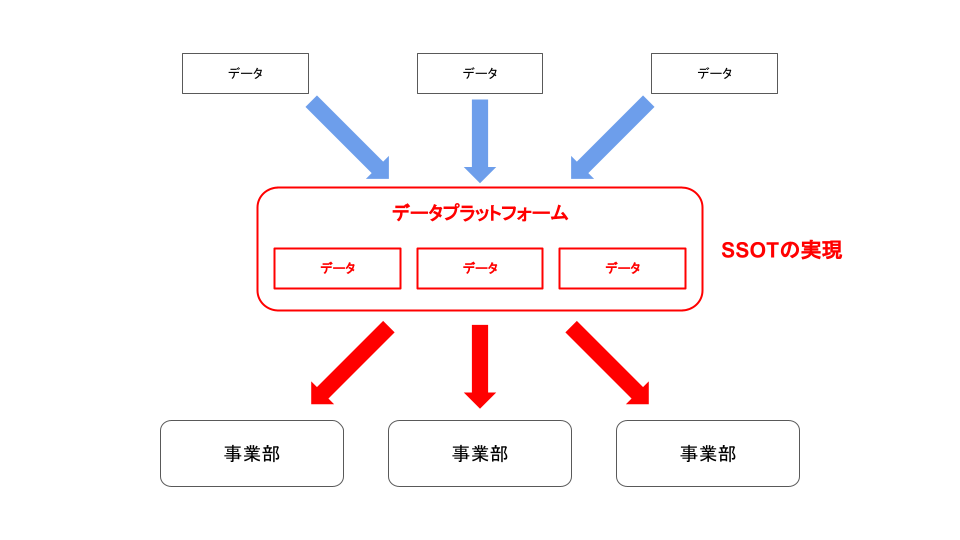
バイセルの今の課題と未来
バイセルはリユース事業でお客様との取引データをRDB上に大量に保持しており、それらが主なデータソースになります。 従来のデータパイプラインは、まずバッチ処理でRDBからデータを取り出して個人情報を含まないデータマート層を構築してCSVを作成し、 CSVベースでデータを管理するBIツールでデータを投入します。 そのBIツール上でダッシュボードを作成したり、データマート層のCSVを直接ダウンロードしてスプレッドシートなどでデータを加工・可視化しています。
しかし、この仕組みは二つの大きな問題を抱えています。
一つ目は利用しているCSVベースのBIツールはSQLが使えないため、データを加工する際にはCSVで落としてから手元で加工する必要があることです。 これによりデータが事業部側でダウンロード後に加工されて保持されることで、更なるデータの発散を促すことになってしまいました。 二つ目はRDB以外のデータソースの収集が難しいことです。 事業部側で管理されたデータがBIツール上で収集・統合することが難しく、データが発散してしまっていました。
このようにSSOTとはほど遠い姿ではあるものの、無理やりマンパワーで乗り切れてしまっていました。 しかし、会社の急激な成長や企業買収による新しいビジネスドメインの合流により、今後データ活用が難しくなっていくことは明らかでした。 データマネジメントの王道に沿ってSSOTを実現することはデータサイエンス部にとって重要なミッションです。
どうやって課題を解決するのか
SSOTを実現するにあたって問題の解消のために以下のことをやる必要がありました。
まずはデータウェアハウスをデータプラットフォームの中心に据えることです。 ビッグデータをSQLのような表現力の高いインターフェースを使って加工できれば手元にデータをダウンロードして加工する必要はなくなります。 バイセルではGCPをメインで使っているため必然的にBigQueryを採用することになりました。 現在は主なデータソースであるRDBからトランザクションログベースのCDCで変更データを吐き出し、イベントストリーム処理でBigQueryにニアリアルタイムで連携する実装を進めています。
もう一つは、散らばってしまったデータをデータプラットフォームに集約させる仕組みを作ることです。 SSOTを実現するためにはあらゆるところに分散したデータをデータプラットフォームに格納するデータパイプラインを構築することがどうしても必要です。 データソースはスプレッドシートやAPIなど多岐に及ぶ上、それらのデータをデータプラットフォームとなるBigQueryに格納できるように加工する必要があります。 これを実現するためにDatabricksを導入してApache Sparkを使うことにしました。
なぜApache Sparkなのか

Apache Sparkはオープンソースのビッグデータ分散処理エンジンです。 データパイプラインを構築しようとすると、Cloud FunctionsやCloud PubSubなど、処理ごとにサービスを組み合わせてマイクロサービス化するのが一般的ですが、 Apache Sparkはスクリプト(Scala、Python)とSQL(SparkSQL)を混在させながら一連の処理を記述することが可能で、モノリシックにデータパイプラインを構築できます。 また、複数ノードからなるクラスターを管理してインメモリでデータを分散処理できることからビッグデータを高速に処理することが可能です。 最近ではBigQueryからApache Sparkが使えるようになるなどApache Sparkへの強いニーズがあることが伺えます。
Apache Sparkを採用した理由は汎用性の高さと開発効率の高さにあります。 Pythonが使えてデータ取得の自由度が高いのでデータ形式の制約を受けづらい上、 クラスターにデータを分散させて処理をするのでデータ量が多くても問題なくデータ処理が行えます。 データ形式やデータ量を問わない汎用性の高さがApache Sparkのメリットです。 また、複数サービスを組み合わせてデータパイプラインを作るとマイクロサービス化せざるをえないので開発効率が悪くなってしまうのですが、 Apache Sparkを使うとモノリシックにデータパイプラインを構築できるので、高い開発効率が得られることもメリットです。
Databricksの利点
DatabricksはApache Sparkの開発者らが創業したDatabricks社が提供するサービスです。 Apache Sparkを動かすにはクラスター管理が必要であり、専任でエンジニアをアサインすることが必要ですが、 Databricksを使うとAWS、GCP、Azure上で複雑な環境構築なしに、簡単にApache Sparkを動かすことができます。 バイセルではDatabricksを使ってGCPでApache Sparkを動かすことにしました。
Databricksを使うメリットはApache Sparkを簡単に動かせるだけではなく、他にも以下のような複数のメリットがあります。
- Databricks notebooksというSaaS環境で開発が可能で、本番同様のクラスターでデータパイプラインの開発が可能
- ジョブごとにクラスターが立ち上がるので、ワークロードの増加に伴うクラスター管理が不要
- Delta Lakeで比較的安価なオブジェクトストレージに気軽に中間データを保存できる
- 柔軟にワークフローが設定できて、APIを使ってワークフローが起動できる
- ワークフローのエラー時はSlackに通知ができて、エラー発生箇所をスタックトレースで追える
- GitHubでコード管理が可能
GCPにもApache SparkのホスティングサービスとしてDataproc Serverless for Sparkがありますが、 本番同様のSaaS環境での開発やGitHub連携などの点でDatabricksの方が使い勝手では勝ると思っています。
なお、SSOTの実現にあたってRDBのデータをニアリアルタイムで連携するBigQueryをデータプラットフォームとするため、 Delta Lakeはあくまで補助的な利用になります。 これはデータが分散してしまうことになりSSOTの精神に反してしまうのですが、必要であればDelta LakeからBigQueryにすぐにデータを連携することは可能なので、あまり問題にはならないと考えています。
Databricks導入後の世界
Databricksの導入により多彩なインプットをもつデータパイプラインを効率よく開発することができます。これによりデータの流れを大きく変えることができます。
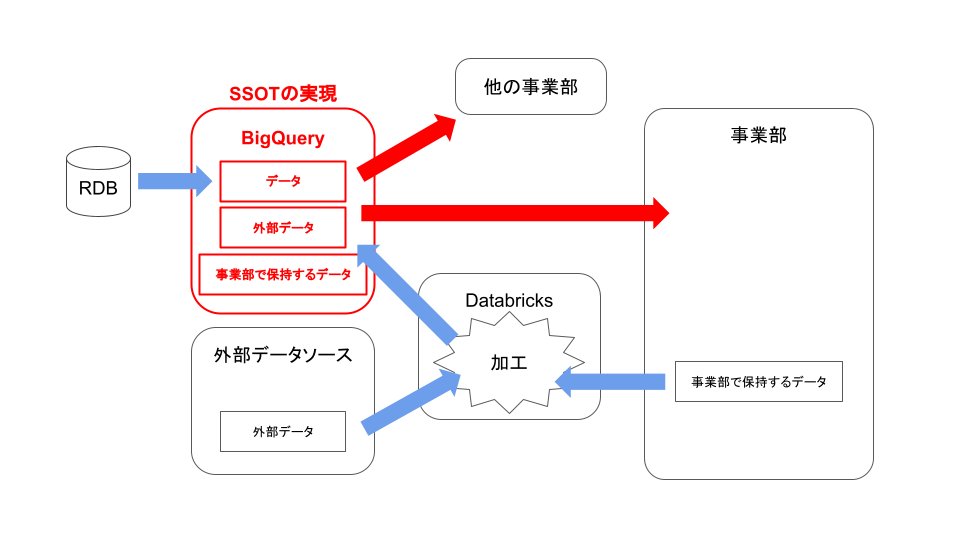
様々なデータ形式のデータを一度Databricksを使って収集・加工し、BigQueryに連携します。 さらにこれをワークフロー化して事業部の業務オペレーションに落とし込みます。 こうしてデータがデータプラットフォームであるBigQueryに向かう流れを仕組み化し、SSOTを実現します。 SSOT実現後は個人情報を除くデータであれば誰でもBigQueryから参照することができるようになります。 バイセルでは案件ごとにマーケティング、コールセンター、営業、倉庫、販売という順でデータが流れていきますが、 事業部間でデータの共通認識を持ってデータ活用が進められるようになります。
データサイエンス部の野望
バイセルではデータドリブン経営を掲げています。しかしデータはそれ単体では意味をなしません。
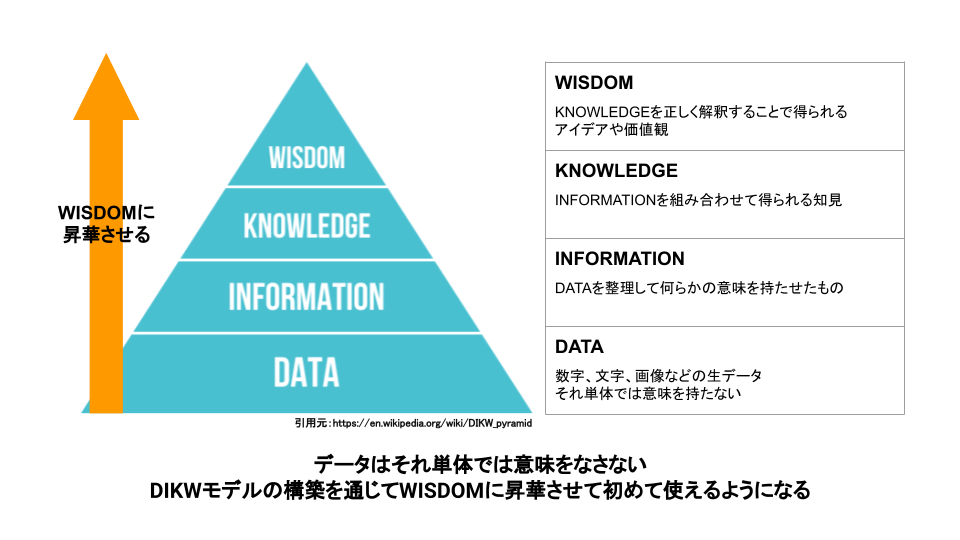
DIKWモデルという概念があり、最下層のDATAからWISDOMに昇華させてようやくデータは使えるものになります。 このDIKWモデルの構築を全社で推進しようとしています。 データサイエンス部のメンバーをデータスチュワードとして事業部に派遣し、一緒にWISDOMを生み出せる体制を構築しようとしています。 また、社内向けのSQLレクチャーをするなど、事業部だけでもWISDOMを生み出すことができるような体制も整えつつあります。 さらに全社で共通認識をもつKPIを策定中であり、WISDOMが事業部間で連携されるような仕組みを作っていこうとしています。 社内のあちらこちらでWISDOMが生まれ、それが全社に共有されるようになる仕組みを作ることがデータサイエンス部の野望です。
現在、エンジニアリングの力でSSOTの実現およびDIKWモデルの構築を一緒に進めてくれる仲間を絶賛募集しています!! 気になる方はぜひご検討ください!!