

こちらは バイセルテクノロジーズ Advent Calendar 2022 の10日目の記事です。 前日の記事は 稲川さんの「Railsでscopeとeager_loadを組み合わせて関連テーブルのデータを一括取得した話」でした。
テクノロジー戦略本部データサイエンス部の近藤です。2022年7月にバイセルに入社しました。
バイセルではSSOT(Single Source Of Truth)を実現するためにDatabricksを導入しましたが、 サーバーやフロントの開発と同じく、チーム開発を行う場合に個人が好き勝手に実装をするとコードがカオスになってしまうため、何らかの実装ルールが必要です。 そこでバイセルではメダリオンアーキテクチャというデータ設計をもとに実装ルールを定めました。今回はそちらのお話をいたします。
なお、以前GCPでDatabricksを導入した経緯をブログ記事にしてますので、是非あわせてご覧ください。
Databricks + BigQueryでSSOTを実現しようとしている話
Delta Lakeとは
データパイプラインを作るときはデータを保管する方法を考える必要があります。 ビッグデータの保存先と言えばBigQueryやTreasure Dataといったデータウェアハウス製品がまず思い浮かびますが、 Databricksでは基本的にDelta Lakeを利用します。
Delta LakeとはDatabricks社が公開したオープンソースのストレージレイヤーです。 Delta LakeはGCSやS3といったオブジェクトストレージにデータをApache Parquetで保存すると共に、 AuditログやコミットログなどのメタデータもJSONで保持します。 このメタデータの管理も一緒に行うことでACIDトランザクションのサポートや、 スキーマ定義に合致しないデータの書き込みを拒否してデータを保護する機能も実現しています。 似たようなものとしてUbers社が公開したApache HudiやNetflix社が公開したApache Icebergがあります。
バイセルではSSOT(Single Source Of Truth)を実現するデータプラットフォームとしてBigQueryにデータを集約しようとしていますが、 処理の途中で生成される中間データをDelta Lakeに保存しています。 メタデータや計算過程で生成しておくと見通しが良くなるデータなどのBigQueryに連携するレベルではないデータも気軽に保存することで、 エラーでバッチ処理が失敗した時のリカバーを容易にしたり、データの訂正が必要になった場合に再度データを生成して過去データを入れ替えることが可能になります。
Delta Lakeはオブジェクトストレージにデータを保存するため、 データウェアハウス製品よりもデータの保存コストが比較的安く抑えられます。 そのため発生するデータを捨てずに気軽に保存できます。 また、パーティションキーを自由に設定できることもメリットです。 パーティションキーで区切った領域にデータを上書き保存できるため、 バッチがこけてリトライしても中間データの冪等性を保つ実装が容易にできます。
メダリオンアーキテクチャとは
Databricks社はメダリオンアーキテクチャというものも提唱しています。 メダリオンアーキテクチャではデータをBronze、Silver、Goldの3つのレイヤーで分類します。
- Bronze
- 未加工データ。データの重複などを含む。
- Silver
- クレンジング済みデータ。データの重複を除去し、使いやすいようにデータの分割や結合を施したデータ。
- Gold
- ビジネスレベルに特化されたデータ。BIツールから参照されるデータ。
Bronze→Silver→Goldにデータを蒸留していくことでデータ構造と品質を管理します。 これはいわゆるデータレイク層、データウェアハウス層、データマート層とほぼ同じ考え方になります。 サーバーサイドの実装ではレイヤードアーキテクチャを採用することで、依存関係をコントロールしながらロジックの再利用しやすくできますが、 同じようにデータもレイヤーに分けて管理することで、依存関係をコントロールしながらテーブルの再利用をやりやすくできます。
メダリオンアーキテクチャを構築するフロー
メダリオンアーキテクチャでDelta Lakeを形成し、 最終的にGoldテーブルをBigQueryに書き込むケースを考えます。 その場合以下のフローで処理が行われます。
- 外部データソースからデータを取得してBronzeテーブルにデータを格納する。
- Bronzeテーブルからデータを取り出して重複を排除し、Silverテーブルにデータを格納する。
- Silverテーブルからデータを取り出して加工し、Goldテーブルにデータを格納する。
- Goldテーブルからデータを取り出して、BigQueryにデータを書き込む。
DatabricksではJupyter Notebookのようなノートブック形式の対話型実行環境が用意されています。 ここで、1つノートブックに上記の四つの処理をまとめて書いてしまうと各処理の結合度が高くなり、デメリットが出てきます。 例えば、すでに存在するSilverテーブルからGoldテーブルを新しく追加しようとした時、 Silverテーブルの処理の後でGoldテーブルの処理を走らせる必要があるため、 必然的にノートブックが肥大化していきます。 また、テーブルの依存関係がノートブックにロックインされるので、テーブルの再利用が難しくなってしまいます。
チーム開発で自由気ままに実装を進めてしまうと、どのテーブルがどこで生成されているのかがわかりづらくなってしまいます。 メダリオンアーキテクチャを綺麗に実装していくにはディレクトリ構成の工夫や実装の方針を定めることが必要です。
バイセルでの2つの実装ルール
バイセルではメダリオンアーキテクチャを実装していくため、下の2つのルールを定めました。
- 1つのノートブックに単一の処理のみ行わせて、複数の処理を呼び出す別のノートブックを作る。
- Delta Lakeのテーブル定義を集約したノートブックを作る。
これらを実現するためにディレクトリ構成は以下のようにしました。
└── root
├── domain
│ ├── bronze ・・・・ bronzeテーブルを生成するロジック
│ ├── silver ・・・・ silverテーブルを生成するロジック
│ ├── gold ・・・・・・ goldテーブルを生成するロジック
│ └── export ・・・・ DeltaテーブルをBQなどの外部ソースに転送するロジック
├── exec ・・・・・・・ domainディレクトリの処理を並べてバッチ処理を実現する
└── delta ・・・・・・・ Delta Lakeの設定
1つずつ解説していきます。
一つのノートブックに単一の処理のみ行わせて、複数の処理を呼び出す別のノートブックを作る
domainディレクトリ配下にbronze、silver、gold、exportの4つのディレクトリを作ります。 bronzeディレクトリは「bronzeテーブルを作る処理」、 silverディレクトリは「silverテーブルを作る処理」、 goldディレクトリは「goldテーブルを作る処理」、 exportディレクトリは「データをBigQueryにexportする処理」という単一の責務を負うノートブックを配置します。
そしてexecディレクトリには下図のようなdomainディレクトリの処理を呼び出してまとめるノートブックを配置します。
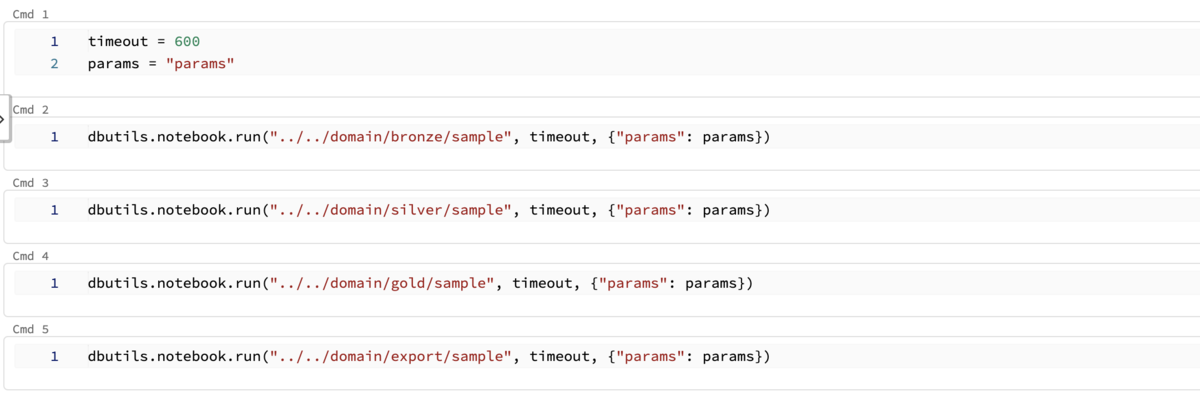 既存のsilverテーブルから別のgoldテーブルを作りたいとなった時には、goldディレクトリにノートブックを追加して、
execディレクトリのノートブックにそれを呼び出す処理を書くことになりますが、
適切な粒度でコードを分割できて、依存関係もexecディレクトリ内で比較的楽にコントロールすることが可能になります。
既存のsilverテーブルから別のgoldテーブルを作りたいとなった時には、goldディレクトリにノートブックを追加して、
execディレクトリのノートブックにそれを呼び出す処理を書くことになりますが、
適切な粒度でコードを分割できて、依存関係もexecディレクトリ内で比較的楽にコントロールすることが可能になります。
Delta Lakeのテーブル定義を集約したノートブックを作る
Databricks File System(DBFS)を使ってDelta LakeをGCS上に構築しており、テーブルの置き場はGCSのパスで表現されます。
ここでdeltaディレクトリ配下にこれらのパスを一元的に管理するノートブックを作り、テーブルの定義が一目でわかるようにしています。
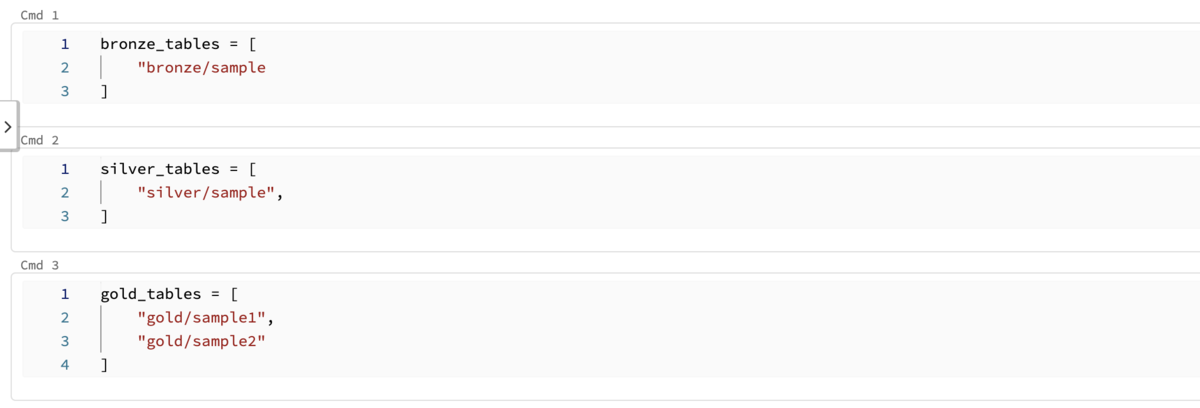
また、パスを取得する関数を用意して、定義されていないパスでテーブルを操作しようとしたときはエラーになるような実装をしています。 これによりどんなテーブルが存在するかが一目でわかるようにして、テーブルの再利用をやりやすくしています。
DatabricksでもUnity Catalogというデータ管理機能がありますが、2022年12月現在ではGCPは未対応です。 こちらが使えるようになるともっといい感じにテーブル管理ができるようになるかもしれません。
実際にやってみてどうだったか?
このルールを適用することでどういうデータをどこに置くかが明確になります。 そのため、実装前にメンバー間でデータの置き場の議論をせずにタスクに着手できるようになり、生産性が上がりました。 また、コードから実装意図がわかりやすくなったことでコードレビューが楽になりました。 若干コードが冗長になるデメリットはあるかもしれませんが、それを補って余りあるメリットがあると感じています。
まとめ
バイセルではメダリオンアーキテクチャに基づきDelta Lakeを構築していますが、 2つのルールを定めることで、どのようなテーブルが存在して、それらはどのように生成されるのかをわかりやすくして、 チーム開発を進める上での秩序を保つようにしています。
現在、メダリオンアーキテクチャの構築を一緒に進めてくれる仲間を絶賛募集しています!! 気になる方はぜひご検討ください!!
明日の バイセルテクノロジーズ Advent Calendar 2022 は 小松山さんによる「GitHub Actions から Cloud Run ジョブで Google Cloud のプライベートネットワーク内へアクセスした」です。