

はじめに
テクノロジー戦略本部開発1部の伊与田です。
私はAXISという在庫・販売管理システムのチームでバックエンドエンジニアとして開発、運用を担当しています。
今回は私が実施したPostgreSQLのアップグレード対応について、書いていきたいと思います。 具体的なアップグレード方法というよりは、Productionアップグレードまでの「調査」や「検証」で気づいたこと、 アップグレード後に発生した「問題」について、どう試行錯誤したのかを記したものとして、 これからアップグレードを対応される方が、スムーズに進めるための参考としていただけると幸いです。
AXISについて
AXISは2018年10月にリリースされた、バイセルのリユース事業の柱である「在庫・販売管理」を支えるシステムです。 別の買取システムと連携して、買取した商品の在庫情報を保持しています。 それらをECサイトや催事などのチャネルで、販売するまでのフローをAXISでは管理しています。
環境名について
本記事では、AXISの各環境について言及するため各名称が何のための環境なのか、ここでまとめておきます。
- Production:いわゆる本番環境です。ここで実際の業務で使うアプリケーションが立ち上がっています。
- Staging:本番リリース前の検証用の環境です。プルリクエストでApproveがでた内容について、ここで結合テストなどを行なっています。
- Development:開発環境です。主にプルリクエスト前の修正を確認するのに使用しています。
- 踏み台サーバー:上記の3環境にSSH接続するための中継用のサーバーです。直接アプリケーションサーバーにSSH接続できてしまうと不正アクセスのターゲットになる可能性が高いため、セキュリティのために使用しています。また踏み台サーバーを経由してAXISの各環境のPostgreSQLにアクセスをしています。
使用技術
今回のご説明にあたり、AXISの技術スタックについて簡単にご紹介しておきます。
- フレームワーク
- Ruby on Rails
- データベース
- Amazon Aurora PostgreSQL
- アプリケーションサーバー
- EC2(AWS Elastic Beanstalk)
- CIツール
- GitHub Actions
- 負荷分析ツール
- New Relic
背景
本題に入っていきますが、今回アップグレードするきっかけになったのは、Amazon Aurora PostgreSQLのサポート終了メールでした。 AXISで使用していたRDSのPostgreSQLのバージョン10系の使用バージョンが、 2023年1月31日にEOSとなるため、11系へのアップグレードが必要という状況でした。
また上記の期間を過ぎてしまうと、AWS側でスケジューリングされたメンテナンス日時で、 サポートされているバージョンに自動でアップグレードされてしまうなどのリスクがあるので、期限前に適切な対応が必要でした。 以下はAWSのアナウンスページです。

調査フェーズ
まずは検証の前に、現状の確認と対応事項を洗い出すための「初期調査」を行いました。 対応としてはリリースノートの「差分調査」も実施していますが、ここでは前段の「初期調査」にスポットを当ててご説明します。 このタイミングで漏れが発生すると、スケジュールの変更や手戻りが発生する可能性があるため、できる限り丁寧に確認を行います。
初期調査
ここでは主に「アップグレード対象のDBサーバやその他ツールなどの洗い出し」や「各環境のインフラ構成、アップグレード方法の確認」など、 スケジュールや対応方針を決定するために必要な情報を調査しました。
アップグレード対象の環境洗い出し
まずアップグレードの際に気をつけるべき点としては、 「アップグレード対象はProductionやStaging、Development環境のPostgreSQLだけではない」ということです。 例えば、AXISではそれらに加えて以下のようなツールも、アップグレード対象に含まれることがわかりました。
- Local
- Dockerコンテナで起動しているDB
- 踏み台サーバー
- PostgreSQLのクライアント
- CIツール
- RSpecなどで使用しているDB
一口にアップグレードと言っても上記のように色々と対応が必要になってくるはずです。 ここで対象を全て洗い出しておかないと後々、作業の追加やそれに伴うスケジュール変更が発生してしまうのでよく確認をしました。 しかし今回の対応では、踏み台サーバー内のPostgreSQLクライアントの対応がスケジュールから漏れていた為、 その分スケジュールを変更する手間が発生してしまいました。
各環境のインフラ構成、アップグレード方法の確認
また運用の都合上、各環境のインフラ構成がそれぞれ異なる場合も多くあると思います。 その場合アップグレードの方法も変わってきますので、 先に把握しておくと工数の見積りが詳細にでき、スムーズな対応が可能になります。 以下今回のアップグレードで対応した環境と方法です。
- Production、Staging、Development
- AWSコンソールからアップグレードを実行する
- Local
- Dockerで構築しているのでDockerfileを修正する
- 踏み台サーバー
- PostgreSQLクライアントのバージョン更新
- CIツール
- GitHub Actionsのymlファイルを修正する
検証フェーズ
検証のフェーズでは、Productionでのアップグレードを、 手戻りなくスムーズに行うために、「複製したStagingのDBを用いた検証」と、 安全性を担保するための「各テストによる検証」を行いました。
複製したStagingのDBでの検証
こちらではStagingのDBのスナップショットから複製したDBを作成して使用します。 そちらでまず、現状のDBのままでアップグレードが完了できるかどうかを確認しました。 AWSのRDSでは基本的に、アップグレード時に何か不具合があった場合はロールバックされますし、 既存の環境への影響もない状態で確認ができるので、一旦複製したStagingのDBで確認するのは気軽にできておすすめです。
検証時に発生した問題
今回の検証では一度アップグレードが失敗しました。
The cluster could not be upgraded because one or more databases have logical replication slots. Please drop all logical replication slots and try again.
原因
原因としては「アップグレード時に論理レプリケーションの設定が入っていると、 アップグレードができないので一度削除する必要がある」というものでした。 バイセルではデータ分析基盤が構築されており、バイセルの様々なシステムのデータを分析基盤上に収集しています。 AXISのデータもニアリアルタイムで論理レプリケーションすることで、少ないタイムラグで在庫関連の情報をデータ分析することができています。 今回はそこの設定があったためにアップグレードが失敗しました。
解決方法
PostgreSQLのレプリケーション設定は、pg_replication_slotsというテーブルにあります。 今回はこちらに2件のレプリケーションスロットが存在したのでそれらを全て削除したのち、 再度アップグレードすることで問題なく対応できました。 この検証によりProductionでの実施前に問題を1件解消しておくことができました。

各テストによる検証
今回Stagingでのアップグレードテスト以外でどのように安全を担保しようか考えた時に、以下3点の方法で対応をしました。
- CIのPostgreSQLについてもアップグレードを行い、RSpecをアップグレード後の状態で実施
- Staging環境でのシナリオテストの実施
- Staging環境のPostgreSQLをアップグレードした状態でしばらくチームで運用
まず、AXISではRSpecを書いて運用しているので、 テストが全て通ることが確認できれば、ある程度のデグレチェックなどは担保できると考えました。
そしてRSpecだけではカバーしきれない部分についてシナリオテストを実施し、RSpecと合わせて漏れなく全ての機能を確認しました。
さらにProductionのアップグレードまでの期間で、Staging環境をアップグレードした状態でそのまま運用し、 普段の改修作業の流れの中で、シナリオテストでは確認できない細かいテストパターンをチェックするようにしました。
これらの三段構えの対応により、安全にProductionでアップグレードするための準備ができました。
Productionアップグレード後に発生した問題
上記の調査、検証の甲斐もあり、Productionアップグレード自体はデグレなどの問題もなく正常に完了したのですが、 運用再開直後から処理パフォーマンスの問題が発生しました。その際の対応についても共有できればと思います。
発生した問題
アップグレード前までは正常に終了出来ていた処理で、タイムアウトエラーが発生しました。 これにより機能としても一時的に使うことができなくなり、改修やデータ修正などが発生しました。
原因
発生した原因は、アップグレードに伴うテーブルキャッシュの消失や、 現状のアプリケーションロジック内のSQL発行処理が低パフォーマンスであったことなど、複合的なものでした。 今回は、それらへの対応の中で私が特に注力したパフォーマンスチューニングについて、紹介したいと思います。
対応
パフォーマンスチューニング
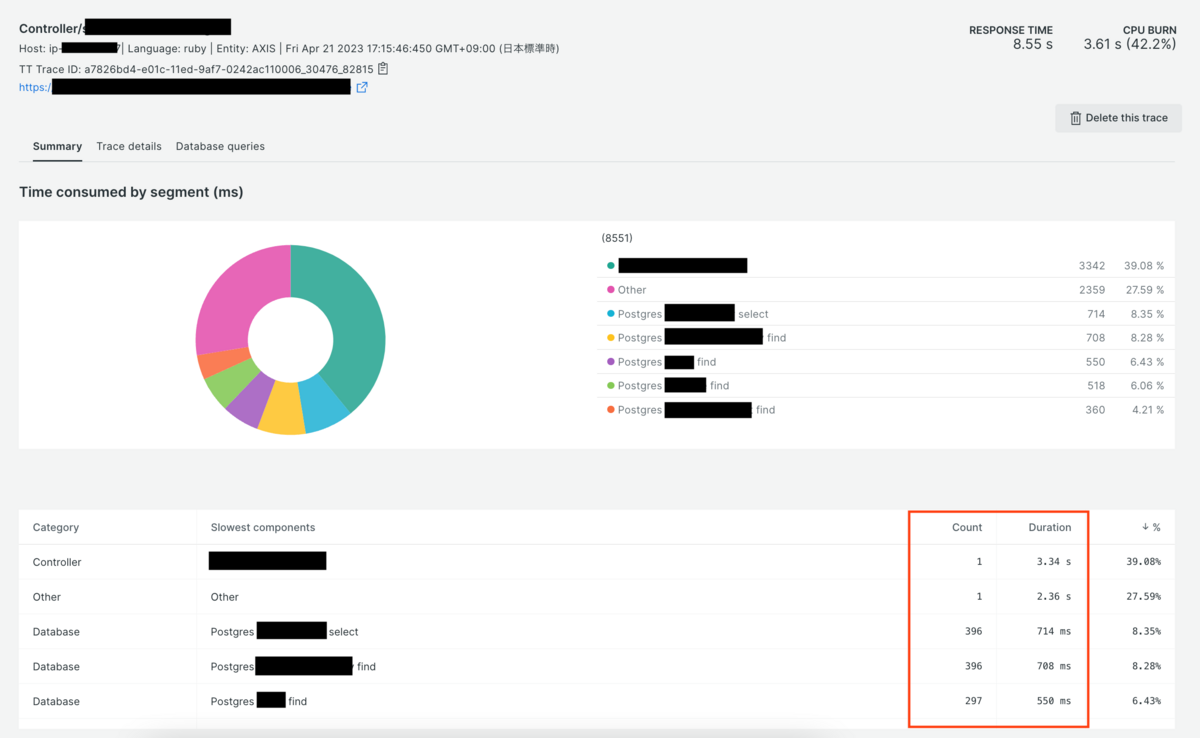
処理パフォーマンス改善に向けて、まず対象の特定をするため以下2点の方法で確認を進めていきました。
ツールを用いたボトルネックの検出
- New Relicで処理速度の遅いAPIを特定
- ボトルネックになっている部分を特定
- DB側の処理
- Ruby側の処理
- 上記についてCount数が多くないか? Durationがかかっている部分はどこか?などを確認
- 実際のコードで該当箇所を見つけ出し、修正
- ボトルネックになっている部分を特定
Count数:そのAPIの呼び出し回数 Duration:実行所要時間
Joinの削減と検索の分割
事象
今回対応した具体的なチューニング事例を1つご紹介させていただきます。 New Relicで検出したスロークエリの中で、1つのクエリで多数のテーブルへのJOINを行なっているものがありました。 多対多のテーブルが含まれていた為に、掛け算的に検索対象のレコードが増えてしまい、 レコード件数が多いテーブルに対して、検索速度が低下するというものでした。
前提
以下修正対象となったクエリの簡単なイメージです。
処理としては多数の関連テーブルから在庫情報を取得しCSVに出力するための2次元配列を作成するというものです。
多数のJOIN、他にもサブクエリを含む複雑な条件指定のためにActiveRecord::Base.connectionのselect_rowsを使って生のSQLを実行している処理でした。
table_aは在庫情報の大元になる各関連テーブルへの親テーブルという前提で説明をさせていただきます。
ActiveRecord::Base.connection.select_rows("
SELECT table_a.aaa
,table_b.bbb
,table_b.ccc
,table_b.ddd
.
.
FROM table_a
INNER JOIN table_b on table_b.table_a_id = table_a.id
INNER JOIN table_c on table_c.table_b_id = table_b.id
INNER JOIN table_d on table_d.table_b_id = table_b.id
.
.
WHERE table_b.xxx = #{@xxx} AND table_c.yyy = #{@yyy} AND table_f.zzz between #{@start_date} AND #{@end_date} ... [その他複雑な条件など]
")
対策方法
対策として1つのクエリで全てJOIN、条件の設定をするのではなく、検索を何段階かに分ける方針を取りました。
①主要なテーブル以外のJOINを削除して、ベースとなるデータのみ取得
- JOINするテーブルを絞ることで検索範囲を狭め、対象の検索件数を減らしています。
②複雑な検索条件を多く指定すると検索負荷が高くなるため、対象データの検索を2回に分けて実行する
- 1回目:ActiveRecordでの表現が難しいので、複雑な検索条件を指定するために引き続き
select_rowsで生クエリで検索をします。 - 2回目:後続の関連テーブルの検索もあるので、ActiveRecordの
eager_loadを使って関連テーブルのデータをキャッシュしつつ検索をします。
results = ActiveRecord::Base.connection.select_rows("
SELECT *
FROM table_a
INNER JOIN table_b ON table_b.table_a_id = table_a.id
WHERE table_b.xxx = #{@xxx} AND [複雑な条件] ...
")
table_a_ids = results.map { |res| res[0] }
table_a = table_a.eager_load(:table_b)
.where(id: table_a_ids)
③eager_loadでデータを取得して、各関連テーブルの外部キーをRubyの配列処理で取得しておく
- ここでもSQLで検索するのではなく、mapやdetectなど、高速なRubyの配列処理で外部キーを取得するようにしました。
④取得した外部キーを使って、元々JOINで取得していた関連テーブル毎に検索
- 関連テーブルごとにクエリが走りますが、一度にすべてのテーブルをJOINして検索するより速度が改善しました。
⑤上記で取得したデータを加工してCSVデータにする
- 最終的にCSV出力できる形式にして完了です。
上記の方法は、テーブルのレコード数などの状況に応じて逆に速度が遅くなる可能性もありますので、 適宜実行速度などは確認が必要になります。
効果測定
上記などのチューニング対応で概ね改善され、以下の観点でも改善されていることを確認できました。
- New Relic上で各処理のDurationやCount数、APIとしてのレスポンスタイムが改善している
- 画面からの操作時にタイムアウトせず、実運用可能な実行時間に戻っている
今回の学びとして、件数が多いレコードをjoinする場合はクエリの速度低下が発生するので、 Ruby側に切り出せるものはそちらに処理を移したり、SQLが発生する処理も一つのクエリで実行するのではなく、 場合によっては複数のクエリに分割するなど、クエリ設計時にも注意する必要があると思いました。
まとめ
今回PostgreSQLのアップグレードに関して、安全にスムーズに対応していくために、 対応事例とともに以下についてご説明をさせていただきました。
- 調査
- アップグレード対象の環境洗い出し
- 各環境のインフラ構成、アップグレード方法の確認
- 検証
- Staging DBを複製してアップグレードを試す
- RSpec実行やシナリオテストなどでの安全性担保
- アップグレード後のパフォーマンス問題
- パフォーマンスチューニング
「調査」ではアップグレード対象の把握とそれらの対応方法について抜け漏れなく把握することが、 スケジュール通りにアップグレードを進めるために必要であること。 「検証」ではいくつかの確認方法を組み合わせて、安全性を担保するという方法。 Productionアップグレード後にパフォーマンス的な「問題」が出る可能性とその対応事例をご説明しました。
最後に
今回は具体的なアップグレード方法についてはお話しせず、 アップグレードの準備段階として「調査」、「検証」について気をつけるポイントを紹介させていただきました。 その後、「アップグレード後の事後対応」についてまとめさせていただきました。 アップグレードの具体的な方法については、インターネット上で数多く情報を見つけられますが、 そこに行き着くまでの「進め方」やアップグレード後の「問題解決」について、参考になるような情報は少なかったので、 自分の体験ベースでまとめさせていただきました。今回の記事がアップグレードを検討している方の参考になりますと幸いです。
BuySell Technologiesではエンジニアを募集しています。こういった取り組みに興味がある方はぜひご応募をお願いします!