

こちらは バイセルテクノロジーズ Advent Calendar 2022 の 16 日目の記事です。
前日の記事は 福田さんの「負荷対策(パフォーマンスチューニング)の運用を 0 から作って定例化する知見」でした。
はじめに
テクノロジー戦略本部データサイエンス部の田村です。
今年 5 月に入社して以来、データエンジニアとしてデータ基盤の構築を行なってきました。
その中で構築した仕組みの 1 つとして、リレーショナルデータベースのトランザクションログを使って BigQuery に変更履歴テーブルを作成した話をご紹介します。
変更履歴テーブルとは
突然ですが、1 度でもデータ分析の経験がある方ならこんな形をしたテーブルが欲しいと思ったことはありませんか?
例 1) アドベントカレンダー執筆状況の変更履歴テーブル
SELECT * FROM xxx_history
| id | writer | status | created_at | updated_at |
|---|---|---|---|---|
| 1 | tamura | 執筆内容検討中 | 2022-11-01 00:00:00 | 2022-11-01 00:00:00 |
| 1 | tamura | 執筆内容レビュー中 | 2022-11-01 00:00:00 | 2022-11-03 12:00:00 |
| 1 | tamura | 執筆中 | 2022-11-01 00:00:00 | 2022-11-05 12:00:00 |
| 1 | tamura | 1 次レビュー中 | 2022-11-01 00:00:00 | 2022-11-10 12:00:00 |
| 1 | tamura | 2 次レビュー中 | 2022-11-01 00:00:00 | 2022-11-28 12:00:00 |
| 1 | tamura | 公開予約済み | 2022-11-01 00:00:00 | 2022-11-30 12:00:00 |
| 1 | tamura | 公開完了 | 2022-11-01 00:00:00 | 2022-12-01 00:00:00 |
| 2 | adachi | 執筆内容検討中 | 2022-11-01 00:00:00 | 2022-11-01 00:00:00 |
| 2 | adachi | 執筆内容レビュー中 | 2022-11-01 00:00:00 | 2022-11-03 12:00:00 |
| 2 | adachi | 執筆中 | 2022-11-01 00:00:00 | 2022-11-05 12:00:00 |
| 2 | adachi | 1 次レビュー中 | 2022-11-01 00:00:00 | 2022-11-10 12:00:00 |
| 2 | adachi | 2 次レビュー中 | 2022-11-01 00:00:00 | 2022-11-28 12:00:00 |
| 2 | adachi | 公開予約済み | 2022-11-01 00:00:00 | 2022-11-30 12:00:00 |
| 2 | adachi | 公開完了 | 2022-11-01 00:00:00 | 2022-12-02 00:00:00 |
しかし、機能要件が「その時の執筆状況(status)が確認できる」だけで良いのであれば、大体下記のようなテーブルになるかと思います。
例 2) ありがちなアドベントカレンダー執筆状況テーブル
SELECT * FROM xxx_history
| id | writer | status | created_at | updated_at |
|---|---|---|---|---|
| 1 | tamura | 公開完了 | 2022-11-01 00:00:00 | 2022-12-01 00:00:00 |
| 2 | adachi | 公開完了 | 2022-11-01 00:00:00 | 2022-12-02 00:00:00 |
上記 2 つのテーブルの違いは、執筆状況(status) の変更履歴を保持しているか否かですが、「その時の執筆状況(status)が確認できる」という目的であれば例 2 に示したテーブルでも十分に満たせると思います。
しかし、「公開までの生産性を上げたい」となると例 1 のような変更履歴テーブルが欲しくなってきます。
変更履歴テーブルの何が嬉しいのか
変更履歴テーブルがあるとデータ分析の幅は格段に広がります。
日頃から「xxx を改善したい」と思って分析を行なっている方からすると、状態の遷移が追えてボトルネックを探せるデータがあるというのは非常に嬉しいことかと思います。
上記で取り上げた例 2 のテーブルだと取得できるデータは最新の状態のみなので、例えば「時間がかかったフェーズはどこだろう?」と思っても打つ手なしです。
ですが、変更履歴を保持している例 1 のテーブルを使うと下記のようなことを発見できたりします。
| status_bf | status_af | duration_minute |
|---|---|---|
| 1 次レビュー中 | 2 次レビュー中 | 25920.0 |
| 執筆中 | 1 次レビュー中 | 7200.0 |
| 執筆内容検討中 | 執筆内容レビュー中 | 3600.0 |
| 執筆内容レビュー中 | 執筆中 | 2880.0 |
| 2 次レビュー中 | 公開予約済み | 2880.0 |
| 公開予約済み | 公開完了 | 1440.0 |
| 公開完了 | null | null |
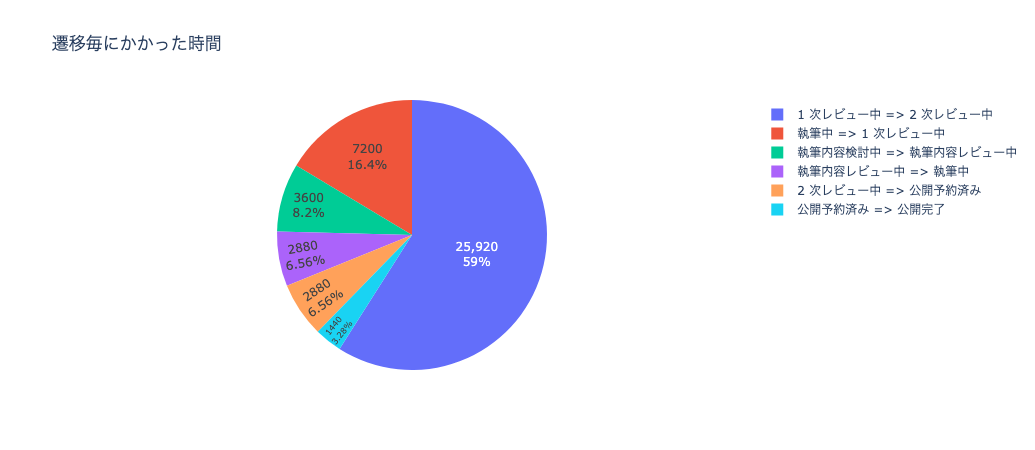
各状態間の遷移の離脱率や遷移にかかった時間を算出してみると、かなり改善ポイントが見えてくるのではないでしょうか。
実装例
実際に変更履歴テーブルを作ろうとすると方法は多々ありますし、開発工数の兼ね合いや利用しているデータベースやツールに含まれる機能の有無などによって最善の策は変わるかと思います。
プログラムで対応するのであれば、RDB 側で変更履歴を保持するようなロジックを実装しても良いです。
もしくは、RDB のトリガーを設定して元のテーブルに変更が発生するたびに変更履歴テーブルにデータを積んでいくでも良いです。
また、基になるデータベースにあまり手を加えずにこっそり実装したい場合には、データベースのトランザクションログを使いデータ更新がある度に変更データを取得する ChangeDataCapture(以後 CDC と記載)の仕組みを構築することでも実現可能です。
これは、GCP の DataStream や DatabaseMigrationService、AWS の DatabaseMigrationService などでも同様の仕組みが使われています。
本記事で取り上げる技術スタックは下記になります。
- データ発生元 RDB
- Cloud SQL for PostgreSQL
- CDC
- PostgreSQL LogicalReplication
- Replication Slot → wal2json
Replication Slot の作成とサブスクライブ方法
今回対象とする RDB は Cloud SQL for PostgreSQL になります。
Logical Replication を行うためには PostgreSQL インスタンスの設定とレプリケーションの機能を使用できる権限を持ったユーザーを作成する必要があります。
詳しくは CloudSQL の公式ドキュメントをご参照ください。
CloudSQL の準備が整ったら Replication Slot(以後 Slot と記載) の作成とサブスクライブを行います。
Slot の論理デコードの制御や Slot からデータの取り出しを行うために pg_recvlogical を使用します。
詳しくは公式ドキュメントをご参照ください。
pg_recvlogical ドキュメント(PostgreSQL 14.5)
Slot 作成 [--create_slot]
$ pg_recvlogical -h localhost -U dms -d slot_test --slot test_slot --create-slot -P wal2json
--create-slot で Slot の作成を行います(論理デコードの出力プラグインには wal2json を使用)。
slot_test=> select * from pg_replication_slots; slot_name | plugin | slot_type | datoid | database | temporary | active | active_pid | xmin | catalog_xmin | restart_lsn | confirmed_flush_lsn | wal_status | safe_wal_size | two_phase -----------+----------+-----------+--------+-----------+-----------+--------+------------+------+--------------+-------------+---------------------+------------+---------------+----------- test_slot | wal2json | logical | 34845 | slot_test | f | f | | | 5237148 | 2/261E9A68 | 2/261E9B00 | reserved | | f (1 row)
Slot が作成できたので、Slot のサブスクライブを開始します。
サブスクライブ開始 [--start]
$ pg_recvlogical -h localhost -U dms -d slot_test --slot test_slot --start -o include-lsn=on -o include-timestamp=on -o include-xids=on -f -
--start で Slot のサブスクライブを開始します。
データ確認
下記のテストテーブルに対してデータ更新クエリを投げてみます。
slot_test=> \d test_table
Table "public.test_table"
Column | Type | Collation | Nullable | Default
------------+--------------------------+-----------+----------+---------
id | bigint | | not null |
status | character varying(255) | | not null |
created_at | timestamp with time zone | | not null | now()
updated_at | timestamp with time zone | | not null | now()
Indexes:
"test_table_pkey" PRIMARY KEY, btree (id)
slot_test=> select * from test_table; id | status | created_at | updated_at ----+--------+------------+------------ (0 rows)
INSERT
slot_test=> insert into test_table values (1, '執筆内容検討中'); INSERT 0 1
CDC データ
{ "xid": 5237279, "nextlsn": "2/2621E9F0", "timestamp": "2022-12-05 01:50:42.778351+00", "change": [ { "kind": "insert", "schema": "public", "table": "test_table", "columnnames": ["id", "status", "created_at", "updated_at"], "columntypes": [ "bigint", "character varying(255)", "timestamp with time zone", "timestamp with time zone" ], "columnvalues": [ 1, "執筆内容検討中", "2022-12-05 01:50:42.777374+00", "2022-12-05 01:50:42.777374+00" ] } ] }
UPDATE
slot_test=> update test_table set status = '執筆内容レビュー中' where id = 1; UPDATE 1
CDC データ
{ "xid": 5237316, "nextlsn": "2/26223938", "timestamp": "2022-12-05 01:53:34.790547+00", "change": [ { "kind": "update", "schema": "public", "table": "test_table", "columnnames": ["id", "status", "created_at", "updated_at"], "columntypes": [ "bigint", "character varying(255)", "timestamp with time zone", "timestamp with time zone" ], "columnvalues": [ 1, "執筆内容レビュー中", "2022-12-05 01:50:42.777374+00", "2022-12-05 01:50:42.777374+00" ], "oldkeys": { "keynames": ["id"], "keytypes": ["bigint"], "keyvalues": [1] } } ] }
DELETE
slot_test=> delete from test_table where id = 1; DELETE 1
CDC データ
{ "xid": 5237333, "nextlsn": "2/26223D90", "timestamp": "2022-12-05 01:54:55.045636+00", "change": [ { "kind": "delete", "schema": "public", "table": "test_table", "oldkeys": { "keynames": ["id"], "keytypes": ["bigint"], "keyvalues": [1] } } ] }
CDC の変更データを JSON 形式で取得することができました。
後続の BigQuery への連携についてですが、例えば JSON のまま BigQuery に投入してクエリ側で値をパースするでも良いですし、または一度データ加工のフローを通してパース済みのデータで NativeTable を作るでも良いですし、方法は多々ありますので一概には言えませんが、バイセルではどのように構築しているのかを一例としてご紹介します。
バイセルのパイプラインアーキテクチャ
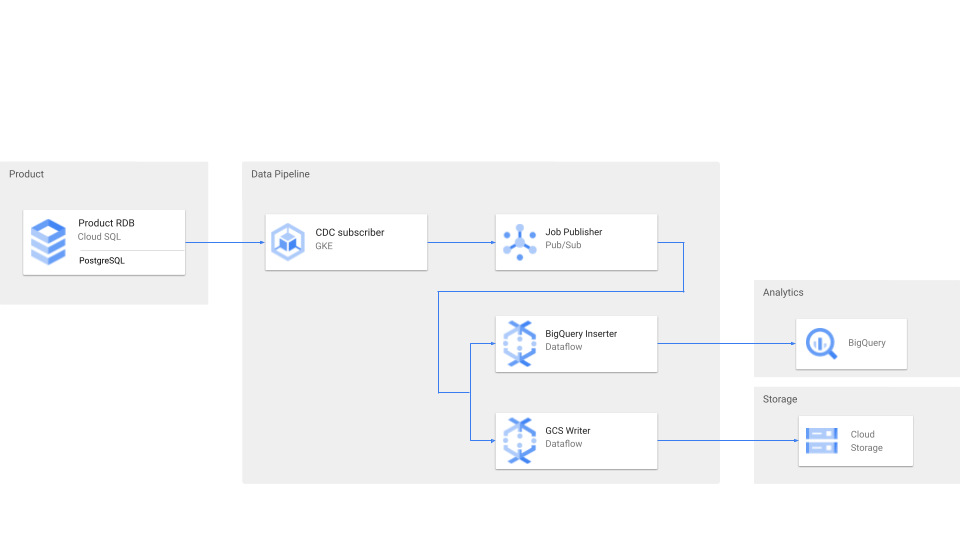
大まかな CDC 変更データの流れはこのようになっています。
各種サービスの役割は下記になります。
GKE の役割
- CDC 変更データの PULL と Pub/Sub への PUSH
2 種類の Dataflow の役割
- GCS へのバックアップ書き出し
- BigQuery へのストリーミングインサート
バイセルでは、アナリストが扱いやすいように CDC 変更データをパースして BigQuery の NativeTable を作成しています。
また、耐障害性を考慮して JSON ファイルをストレージに保存するフローも用意しています。
プロダクト側の変更やインフラ特性による影響から分析用 Query を避けるため、 View を間に挟んでアナリストなどへ提供しています。
BigQuery での変更履歴データ活用
これで変更履歴テーブルが使えるようになりましたね。
「公開までの生産性を上げたい」と思ったアナリストは例えばこんなクエリが書けるようになります。
WITH sample AS ( SELECT 1 AS id, 'tamura' AS writer, '執筆内容検討中' AS status, TIMESTAMP('2022-11-01 00:00:00') AS created_at, TIMESTAMP('2022-11-01 00:00:00') AS updated_at UNION ALL SELECT 1 AS id, 'tamura' AS writer, '執筆内容レビュー中' AS status, TIMESTAMP('2022-11-01 00:00:00') AS created_at, TIMESTAMP('2022-11-03 12:00:00') AS updated_at UNION ALL SELECT 1 AS id, 'tamura' AS writer, '執筆中' AS status, TIMESTAMP('2022-11-01 00:00:00') AS created_at, TIMESTAMP('2022-11-05 12:00:00') AS updated_at UNION ALL SELECT 1 AS id, 'tamura' AS writer, '1次レビュー中 ' AS status, TIMESTAMP('2022-11-01 00:00:00') AS created_at, TIMESTAMP('2022-11-10 12:00:00') AS updated_at UNION ALL SELECT 1 AS id, 'tamura' AS writer, '2次レビュー中' AS status, TIMESTAMP('2022-11-01 00:00:00') AS created_at, TIMESTAMP('2022-11-28 12:00:00') AS updated_at UNION ALL SELECT 1 AS id, 'tamura' AS writer, '公開予約済み' AS status, TIMESTAMP('2022-11-01 00:00:00') AS created_at, TIMESTAMP('2022-11-30 12:00:00') AS updated_at UNION ALL SELECT 1 AS id, 'tamura' AS writer, '公開完了' AS status, TIMESTAMP('2022-11-01 00:00:00') AS created_at, TIMESTAMP('2022-12-01 00:00:00') AS updated_at UNION ALL SELECT 2 AS id, 'adachi' AS writer, '執筆内容検討中' AS status, TIMESTAMP('2022-11-01 00:00:00') AS created_at, TIMESTAMP('2022-11-01 00:00:00') AS updated_at UNION ALL SELECT 2 AS id, 'adachi' AS writer, '執筆内容レビュー中' AS status, TIMESTAMP('2022-11-01 00:00:00') AS created_at, TIMESTAMP('2022-11-03 12:00:00') AS updated_at UNION ALL SELECT 2 AS id, 'adachi' AS writer, '執筆中' AS status, TIMESTAMP('2022-11-01 00:00:00') AS created_at, TIMESTAMP('2022-11-05 12:00:00') AS updated_at UNION ALL SELECT 2 AS id, 'adachi' AS writer, '1次レビュー中 ' AS status, TIMESTAMP('2022-11-01 00:00:00') AS created_at, TIMESTAMP('2022-11-10 12:00:00') AS updated_at UNION ALL SELECT 2 AS id, 'adachi' AS writer, '2次レビュー中' AS status, TIMESTAMP('2022-11-01 00:00:00') AS created_at, TIMESTAMP('2022-11-28 12:00:00') AS updated_at UNION ALL SELECT 2 AS id, 'adachi' AS writer, '公開予約済み' AS status, TIMESTAMP('2022-11-01 00:00:00') AS created_at, TIMESTAMP('2022-11-30 12:00:00') AS updated_at UNION ALL SELECT 2 AS id, 'adachi' AS writer, '公開完了' AS status, TIMESTAMP('2022-11-01 00:00:00') AS created_at, TIMESTAMP('2022-12-02 00:00:00') AS updated_at ), history AS ( SELECT * , ROW_NUMBER() OVER (PARTITION BY id ORDER BY updated_at) AS __id FROM sample ) SELECT history.status AS status_bf , next.status AS status_af , AVG(TIMESTAMP_DIFF(next.updated_at, history.updated_at, minute)) AS duration_minute FROM history LEFT JOIN history AS next ON history.id = next.id AND history.__id + 1= next.__id GROUP BY 1,2 ORDER BY 3 DESC
| status_bf | status_af | duration_minute |
|---|---|---|
| 1 次レビュー中 | 2 次レビュー中 | 25920.0 |
| 執筆中 | 1 次レビュー中 | 7200.0 |
| 執筆内容検討中 | 執筆内容レビュー中 | 3600.0 |
| 執筆内容レビュー中 | 執筆中 | 2880.0 |
| 2 次レビュー中 | 公開予約済み | 2880.0 |
| 公開予約済み | 公開完了 | 1440.0 |
| 公開完了 | null | null |
(鬼の 1 次レビュワーでもいたのでしょうか。。)
おわりに
バイセルではより一層の事業成長を目指して、これまで以上にデータ活用を推進しています。
そのためにも、データエンジニアチームはデータ活用を行うアナリストや ML エンジニアが扱いやすいデータ基盤を構築して参ります。
現在、より一層の事業成長のためにデータ活用してくれる仲間を絶賛募集しています。
気になる方はぜひご検討ください!
明日の バイセルテクノロジーズ Advent Calendar 2022 は 飯島さんによる「typescript-eslintにcommitした話」です。