
こちらは バイセルテクノロジーズ Advent Calendar 2022 の15日目の記事です。
昨日は高谷さんによる全社員がSQLを書けるようBQの権限やデータソースを整理して運用している話(前編)という記事でした。
はじめに
福田です。Webサービスを良い感じにするため、フルスタックに色々やっています。
今日は負荷対策(パフォーマンスチューニング)の運用を0から作って定例化する知見について紹介します。
サービスの成長や改修を続けているといつかは発生するけど、対応になかなかパワーが必要な負荷問題。必要性はわかるけど、限られたリソースの中でどこからどのように取り組むべきか、悩む機会が多いのでは無いでしょうか。
今回、単純にチューニングをするだけではなくて、チームとして継続的に取り組む体制を構築するところまで上手くできたので、その進め方や気を付けた事を紹介します。個々の技術の深堀りはせずに、汎用的に様々なサービス・プロジェクトで参考になるようにまとめました。運用の手助けになれば幸いです。
背景
BtoBのオンラインオークションサービスであるTimelessオークションが今回の対象です。
オークションサービスなので、入札があって、入札には締め切りがあります。
- 月に1回、予め決められた1週間程度の期間だけ入札ができる
- 締め切りは、商品の種類等によってある程度の固まりで同じ時間が設定されている
という特徴があります。オークションという特性上、締切直前に入札が集中しやすいため、システムの負荷的には厳しい予感がしますね…。
アーキテクチャ(主要なもの)
- Rails
- React(Next.js)
- TypeScript
- AWS
- Fargate
- RDS for PostgreSQL
- CloudWatch
チーム体制
- ディレクター 数名
- デザイナー 1名
- エンジニア10名程度
- フロントエンドとバックエンドごちゃまぜ
- インフラ専任はいない
- 筆者はここ
- 全体として、社員と業務委託(参画時間が限られる)ごちゃまぜ
やった事
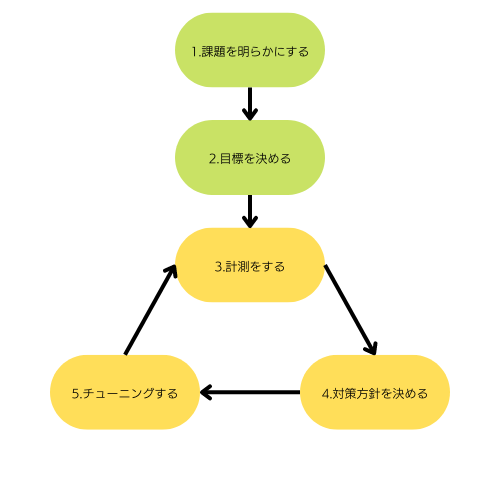
1.課題を明らかにする
まずは起きている課題を明確にします。各所にヒアリングをしたところ、以下の事がわかりました。
- 大きめの改修を入れたタイミングで遅くなった
- 遅いとのユーザーからの問い合わせがあった
- 特に入札終了間際が遅い
- 具体的にどの程度遅い等はまだわかっていない
- 遅いとのユーザーからの問い合わせがあった
- CloudWatchからRDSのCPU負荷についてアラートが来ていた
つまり、ユーザー体感として感じられる程度まで遅くなっており、サービスを快適に使えない
=> 快適に使える状態へする必要がある という課題がわかりました。既にユーザーへ影響が出てしまっており、早めの対策が必要な状態です。
その後、チーム(ディレクターとエンジニア両方)でミーティングを開催し、わかった事と相応の対策を取る必要性を共有しました。
ポイント
- 現状手に入る情報から可能な限り情報を集める
- システムによる定量的な情報(CloudWatch等の監視ツール等)だけではなく、ユーザーからの意見、直接サービスを触った時の感覚やキャプチャ等の定性的な情報も対象とする
- 課題感、対応の緊急度、影響の大きさはチーム全体で共有する
- 負荷対策は様々な方面から攻める必要がある
- 一定の工数を割く(つまり他の開発と優先度を調整する必要がある)ことの必要性を共有するため、PM/ディレクター必須
- 負荷対策の内容によってはアプリケーション側の改修が必要になるため、エンジニア必須
- UI/UXによって改善できる場合もあるので、デザイナーもいた方が良い
- パフォーマンス・チューニングは継続的にやる必要がある
- チーム体制の変更があっても続けられるようにする
- 一番最初は、担当者個人に依存してしまうのはある程度しょうがないが、可能な限りスキルトランスファーの機会を設ける
- チーム体制の変更があっても続けられるようにする
- 負荷対策は様々な方面から攻める必要がある
2.目標を決める
課題に対して、目標を決めます。こちらもチームにヒアリングしながら決めました。
- 遅い場合、お客さんの入札が間に合わず、サービスの価値を損ねる可能性がある
- なので、入札終了まで快適に操作可能である事が必要
- 快適の範囲は厳密に数字では決めない
- 入札機能、検索機能が最重要
- 他の機能については優先度は下げて大丈夫
- なので、入札終了まで快適に操作可能である事が必要
としました。
ポイント
- 何を目標とするかは最初は厳密に決めすぎない
- 目標を決めるコストとの綱引き
- 参考:GoogleがSREの基本として提唱していますがこの通りに実践するのはかなり大変です
- 目標を決めるコストとの綱引き
- 機能の開発と同じように、最初は大事なポイントに絞る
- いきなり完璧に対応するのは難しい
- 優先度の決め方は、普段の機能開発と同じ観点が流用できる
- 可能であれば定量的な目標の方が良い(計測しやすいので)
- とは言え、始める段階では現状の数字を取れない事がほとんどなので可能な範囲で十分
3.計測をする
目標が決まったので早速チューニングをしたいところですが、その前に大事な手順があります。
推測するな、計測せよ という言葉があるように、チューニングする前に、計測は必須です。計測が無いと、負荷対策の結果で良くなったのか、悪くなったのかわかりません。また、継続的に対応していくには、定点観測が常に必要です。 定性的な判断も役には立ちますが、定量的な判断の代わりにはなりません。
計測するための準備が足りていなければ、計測できるように諸々の改修をします。
元々CloudWatchは動いていたのですが、追加で以下を対応しました(個々の対応についての詳細は本記事では割愛します)。
- CloudWatchの精査
- metrics、dashboard、保存期間のカスタマイズ
- New RelicをRailsに導入
便利なツール・サービスがあるのはありがたい反面、高機能なために使いこなすためには学習コストがかかったり、設定の追い込みも必要です。どこまでここに工数をかけるかの判断は難しいですが、まずはオークションの開催スケジュールに間に合う範囲で対応しました。
上記準備を整えた上で、月に1回開催のオークションを迎え、実際に計測をしました。
なお、1.課題を明らかにする の中で既に計測できているものもありましたので、関わる内容についてはこの手順を飛ばしています。
ポイント
- いきなり全部計測しようとしない
- あくまで下準備なので、時間をかけ過ぎない
- デフォルトで用意されている各種モニタリングツール、導入が用意なSaaSを有効活用する
- 検討にも時間はかかるため、最初はチーム・社内で知見を持っているものがおすすめ
- デフォルトで用意されている各種モニタリングツール、導入が用意なSaaSを有効活用する
- 準備が間に合わない部分は、手動での監視も活用する
- Chromeの開発者ツールを使いつつ、本番のサービスを実際に触ったりもしました
- あくまで下準備なので、時間をかけ過ぎない
4.対策方針を決める
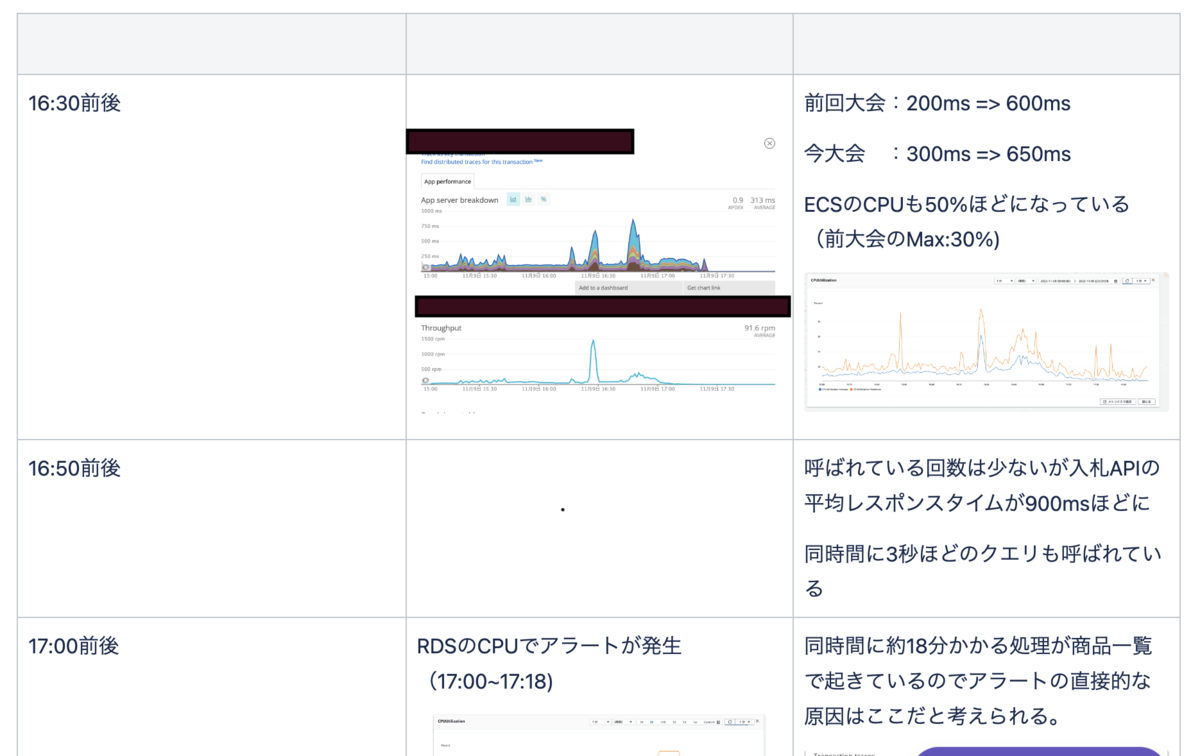
続いて、計測した結果をまとめます。ドキュメント管理に使用しているConfluenceに専用ページを作成しました。オークションの期間が1ヶ月スパンなのと、ツールで閲覧できるメトリクスには時間制限があるため、キャプチャとして残す方針としました。
また、補足として計測方法や結果の見方についての知見をまとめたページも作成しました。
上記準備を整えてミーティングを開催し、計測結果からわかる現状と課題を改めて共有し、対策の方針(どこを優先的に対策するか)を決めました。
計測が足りない事もあり、原因を明らかにしきれない部分もありました。その場合は、必要な計測を増やしていく事で対応していきます。また、初回は過去データとの比較ができない事もあり、どの程度が正常なのかの判断が難しいです。やはり、継続的に見ていく必要があります。
ポイント
- 結果だけではなく、計測方法や計測結果の見方も共有する
- 負荷対策は1回で終わりではなく、継続的に行う必要がある
- 対策箇所を決めたら、開発案件と同様の管理をする
- 今回はJiraにチケット登録し、タスク割り振り
- 負荷が問題となる前に検知する仕組みの導入も検討する
- RailsのN+1であればBulletの導入等
5.チューニングする
割り振ったチケットに従って、個別に対策をしていきます。
具体的には以下のような対応を何ヶ月かかけて行いました。
- バックエンド
- RailsのN+1
- SQLチューニング
- 不要な処理が実行されないようにロジックの見直し
- フロントエンド
- Reactで不要な再レンダリングが実行されている箇所の見直し
- インフラ
- RDSのスペック調整
- Fargate台数調整
個々の詳細については割愛しますが、このあたりは公式のドキュメントや様々なブログ等が参考になります。 本アドベントカレンダーでも12日目にN+1について紹介しています。
ポイント
- チューニングを実施したら、ローカル環境やテスト環境で、整備した計測手順でbefore/afterを比較する
- 可能な限り、本番に環境を近づけて置けると良い
- インフラ系のスペック
- データ数、偏り
- 可能な限り、本番に環境を近づけて置けると良い
3〜5を毎月行う、たまに1に戻る
繰り返しになりますが、負荷対策は継続的に行う必要があります。
以下の運用を定例的に行う事にしました。
- 計測とそのまとめについて毎月Jiraでチケットを作成し、担当者をアサインし実施する
- 担当者はできるだけローテーションする
- まとめの報告会でレビューも兼ねる
- 担当者はできるだけローテーションする
チューニングが進む事で、あるいはサービスが発展するに従って、状況は随時変わりますので、適宜 1.課題を明らかにする へ戻るのも有効です。
ポイント
- 繰り返していく中で、計測ツールや方法についてのブラッシュアップを随時行っていく
- チーム体制が変わっても継続できるように、担当はローテーションする
成果
この運用を開始してから、以下のような状態にできました。
- 開発において、パフォーマンス上の課題を埋め込んでしまう可能性を減らした
- Bullet等による自動チェックの仕組み
- レビュー・QA時の観点として常にパフォーマンスを意識する
- 問題が発生した(パフォーマンスが劣化した)時の対応の速度が上がった
- 色々な人がローテーションで各種メトリクスを見ているので、気がついた人=初動できる人 の確率が高まった
- パフォーマンスの計測・チューニングを通じてインフラ、アーキテクチャについての技術力底上げ
- 計測結果を分析したり対策を考えるためには、仕組みを理解していないと難しい
- 新卒の方ももりもり調査してくれて、うれしい限り
まとめ
以上、負荷対策(パフォーマンスチューニング)の運用を0から作って定例化する知見について紹介しました。 運用の参考にしていただければ幸いです。
もちろん、今でも完璧な対策を取れているわけではなく、継続的に対策は実施中です。例えば、FEのパフォーマンス計測はまだ課題を抱えていて、絶賛取組中です。
BuySell Technologiesではエンジニアを募集しています。こういった取組に興味がある、私にまかせろ! という方はぜひご応募をお願いします!
明日のアドベントカレンダーは田村さんによる「こっそり作る変更履歴テーブル - CDC(Change Data Capture) を使って」です!