

こちらはバイセルテクノロジーズ Advent Calendar 2024の1日目の記事です。
こんにちは、開発2部でテックリードをしている早瀬です。普段はリユースプラットフォームのEC出品管理システムの開発を行っています。
私のチームでは、EC出品管理システム(通称EXS)の開発を行なっており、3年間に及ぶ開発の末に今年の9月にローンチされました。
私はプロダクトの立ち上げ時から参画しており、開発初期の技術選定から関わってきました。
長期に及ぶ開発の末に、ついにローンチされたので、今回はそのプロダクトの技術選定についての振り返りを紹介したいと思います!
記事のボリュームもかなりあるので、興味のある箇所だけでも読んでいただけると嬉しいです。
プロダクトの概要
EXSは複数のECサイトへの出品・受注業務を一元管理するWebアプリケーションです。
利用者は商品の販売機会を最大化するために、複数のECサイトに同時に出品を行います。
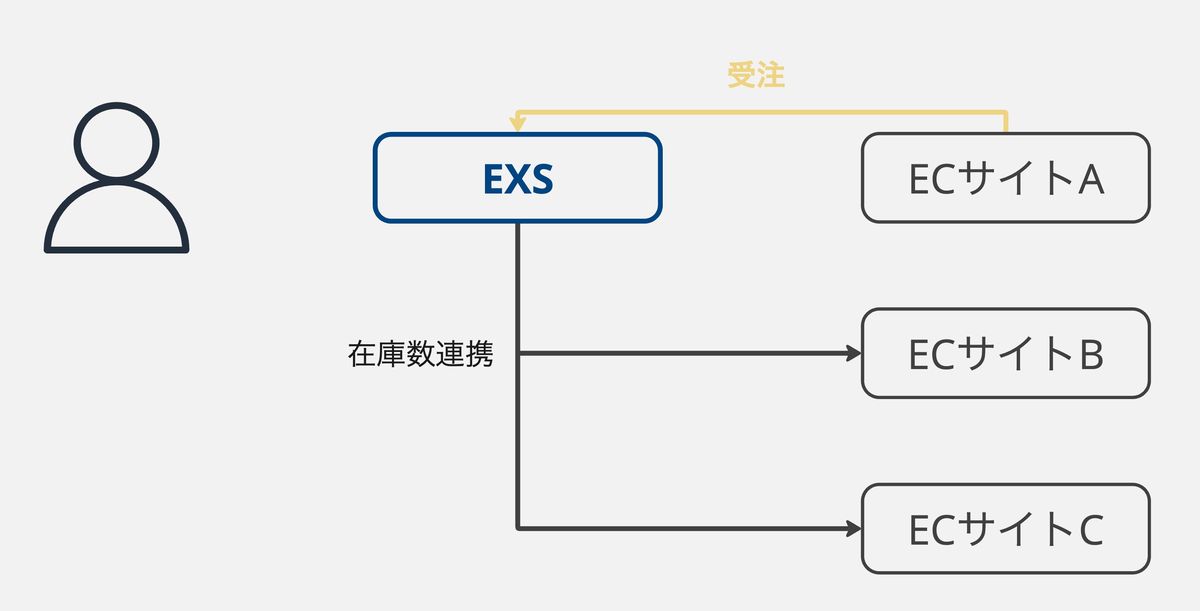
その際に、EXSが各ECサイトの仕様の違いを吸収し連携を行うことで、利用者はこれらの差異を意識することなく、商品の出品や受注業務を一元的に管理できます。

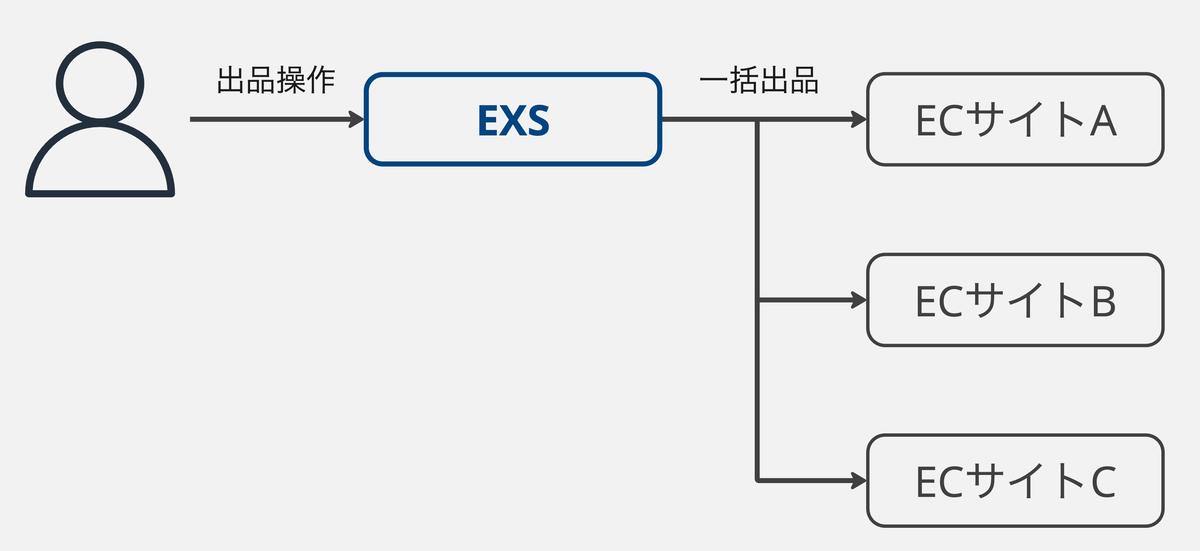
また、リユースの商品は全て1点ものため、複数のECサイトに同時に出品を行い、どこかで売れた場合は、残りのECサイトからは即時に出品を取り下げる必要があります。
これらの連携もEXSが各ECサイトでの受注を検知して、リアルタイムで連携を行なっています。
現時点では8つのECサイトに対応しており、連携先は今後も拡大予定です。
プロダクト特性
EXSは下記のような特性があります。
- BtoBシステムで、認証されたユーザーのみが利用する
- 現在はバイセルグループ内でのみで利用
- 外部サービスとの連携が非常に多い
- 連携するAPIの種類は、GraphQL・REST・XML・SOAPなど、多種多様
- 現時点で100以上の外部APIと連携している
- 提供元も違うので、それぞれの仕様に準拠し、追従し続ける必要がある
- 一括出品や一括受注処理が主な機能で、検索して一括処理という流れのフローが多い
- 商品情報が可変属性のデータを持つ
- テナントが商品に対して、項目や選択肢を自由に定義できる
- 定義した項目を検索したり、CSVで出力したりすることも可能
- 主にPCで利用される
- 将来的にはモバイルにも対応予定
技術構成
技術構成は下記の通りです。
- API
- GraphQL
- REST
- バックエンド
- Hasura
- Go
- gqlgen
- GORM
- フロントエンド
- Next.js
- TypeScript
- Apollo Client
- インフラ
- Google Cloud
- Cloud Run
- PostgreSQL(Cloud SQL)
- Elasticsearch
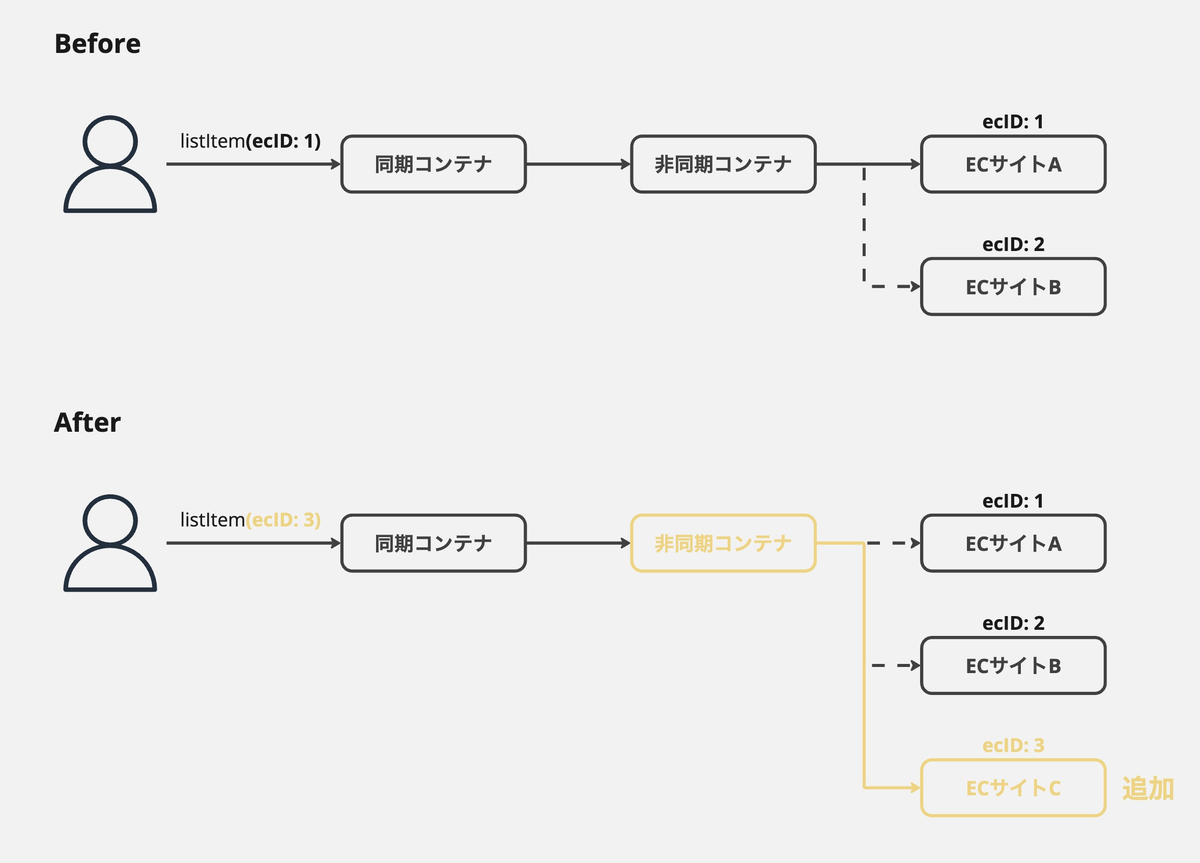
同期処理用のコンテナ(以降同期コンテナ)と、非同期処理用のコンテナ(以降非同期コンテナ)があり、同期処理用のコンテナはGraphQL、バッチ処理用のコンテナはRESTを使用しています。
各モールとの連携処理は、主に非同期コンテナで行っています。

技術選定の振り返り
ここからは技術選定について、マッチしたもの・マッチしなかったものに分けて、それぞれ紹介していきたいと思います!
マッチしたもの
Go
以前、バイセルではRuby on Railsが採用されていましたが、2021年頃からGoへのリプレイスが始まり、EXSもそちらに合わせてGoを採用することになりました。
振り返ってみて、Goの採用は非常に良かったと感じています。
学習コストの低さ
その理由の一つが言語仕様のシンプルさによる、学習コストの低さです。
開発期間が長かったため、様々な理由でメンバーの入れ替わりも度々ありました。バイセルでは新卒採用も積極的に行っているので、毎年4月には新卒のメンバーもチームに加わります。
そんな中で、新たに加入するメンバー全員にGoの開発経験があるわけではなかったですが、学習コストが低く、キャッチアップがしやすいため、新たに参加したメンバーでも比較的早く開発に参加できました。
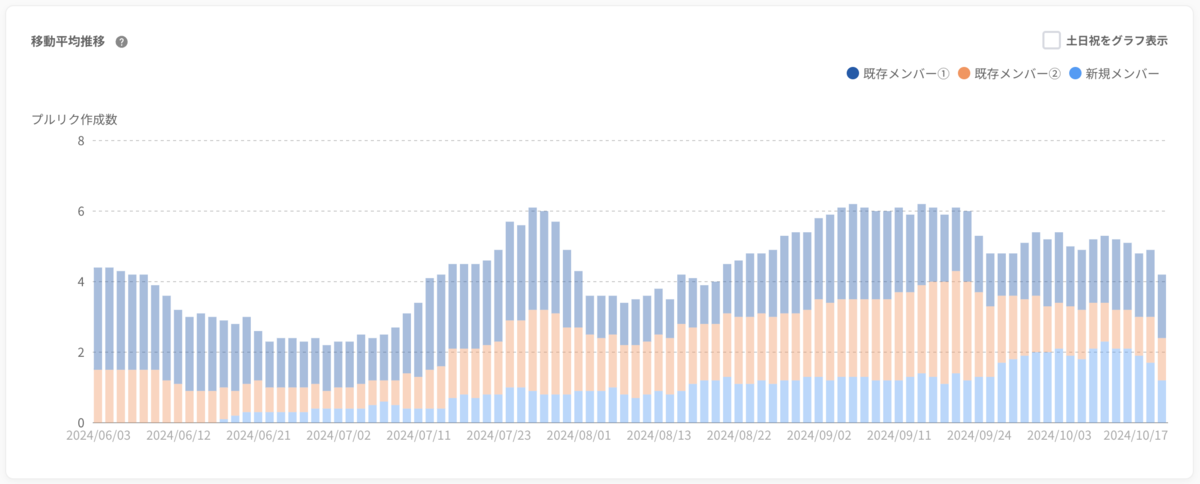
以下は今年入社した新卒メンバーのPR作成数の遷移です。
新卒の全体研修を終えて6月からチームに加わりましたが、その時点ではGoの経験はもちろん、サーバーサイドの開発経験もありませんでした。
そこからキャッチアップを開始し、順調にPR作成数が増加しており、加入から約3か月で既存メンバーと同程度に達していることがグラフから確認できます。
比較的簡単なタスクをアサインして、チームメンバーが手厚くサポートしたことも要因として挙げられますが、それでもキャッチアップが順調だったことがわかると思います。
開発速度の向上
言語仕様のシンプルさは、学習コストの低さに加えて、可読性や実装のしやすさにも繋がります。
言語仕様がシンプルな故に、書き方が冗長になることも多々ありますが、誰が書いても同じような書き方になるため、コードを追いやすくレビューもしやすいです。
使用しているパッケージのコードも、抵抗なく読めるので、内部実装を理解した上で使用でき、黒魔術的なことが少なくなります。
フロントエンドの実装をする際は、TypeScriptを使用していますが、三項演算子を使うのが良いのか、if-elseを使うのが良いのか、若干悩む場面があります。
Goの場合は三項演算子がない*1ため、書き方に迷うことが少なく、レビューで指摘を行うことも少ないです。
CLIとの親和性
また、CLIを作成しやすい点もGoを採用してよかった点です。
私のチームでは、cobraを使って、開発を効率化するためのCLIツールを作成しています。
cobraを使うことで、手軽にCLIを作成できるため、開発過程で困ったことがあれば、CLIを作成して解決するという文化が生まれました。
特に、開発時の連携先が多く、属人化しやすい状況で、この文化が開発生産性を向上させる一因となっていると感じています。
作成したツールの一例は、こちらの記事で紹介しているので、興味のある方はご覧ください。
GraphQL
フロントエンド・バックエンド間のAPIにはGraphQLを採用しました。
Fragment Colocationのパワー
私は比較的フロントエンドの実装を行うことが多いのですが、GraphQLを採用して一番良かった点は、Fragment Colocationによるデータフェッチの最適化と開発効率の向上だと感じています。
Fragment ColocationとはGraphQLにおける設計思想で、コンポーネントのデータ要件をFragmentで定義し、コンポーネントとセットで管理するというものです。
コンポーネントで使用するデータをFragmentで定義し、それらのコンポーネントをまとめ上げた親コンポーネントでQueryとして実行します。
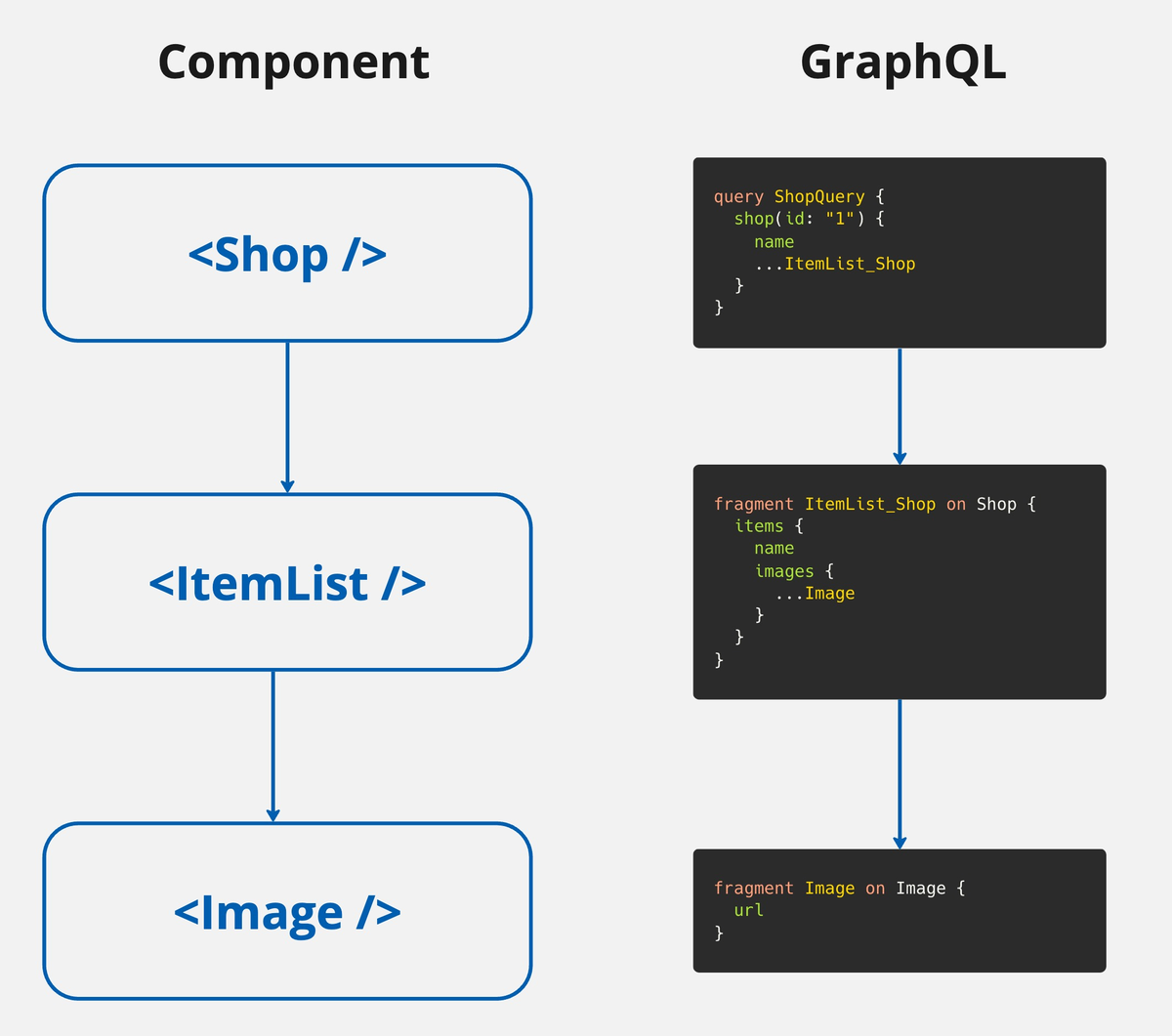
データの宣言とコンポーネントがコロケーションされているので、オーバーフェッチに気づきやすくなります。
実際に実装やレビューをする際にも、UIから要素を削除しているが、Fragment内のフィールドの削除漏れに気づく場面が何度かあり、オーバーフェッチを防ぐのに役立ちました。
また、Fragment Colocationは開発効率の向上にも繋がります。 下記はコード一例です。
import { graphql } from '~/gql'; import { useSuspenseQuery } from '@apollo/client'; import { OrderCustomerInfo } from './OrderCustomerInfo'; const OrderDetailQuery = graphql(/* GraphQL */ ` query OrderDetailQuery { order { ...OrderCustomerInfo_Order } } `); export const OrderDetail: React.FC = () => { const { data } = useSuspenseQuery(OrderDetailQuery); return ( <div> <h1>注文詳細</h1> <OrderCustomerInfo orderRef={data.order} /> </div> ); };
import { FragmentType, graphql, useFragment } from '~/gql'; const OrderCustomerInfoFragment = graphql(/* GraphQL */ ` fragment OrderCustomerInfo_Order on Order { id orderedAt purchaser { id name address } } `); type OrderCustomerInfoProps = { orderRef: FragmentType<typeof OrderCustomerInfoFragment>; }; export const OrderCustomerInfo: React.FC<OrderCustomerInfoProps> = ({ orderRef, }) => { const order = useFragment(OrderCustomerInfoFragment, orderRef); return ( <div> <p>注文日時: {order.orderedAt}</p> <p>購入者: {order.purchaser.name}</p> <p>住所: {order.purchaser.address}</p> </div> ); };
OrderCustomerInfo.txsでFragmentを定義して、その型情報をそのままPropsに指定しています。
RESTやFragment Colocationを使わないGraphQLの場合は、OrderCustomerInfoで必要な情報をPropsで定義し、OrderDetailで取得したデータとPropsのマッピングを行うことになると思います。
それと比べて、Fragment Colocationを使った場合は、そのようなマッピング処理が不要になります。
また、OrderCustomerInfoに変更を加える場合も、OrderDetailに変更は不要でOrderCustomerInfoのみ変更すれば良く、影響範囲も限定されるので、実装工数が非常に少なく済みました。
▶︎ 修正例
--- a/OrderCustomerInfo.tsx +++ b/OrderCustomerInfo.tsx @@ -174,7 +174,6 @@ const OrderCustomerInfoFragment = graphql(/* GraphQL */ ` purchaser { id name - address } } `); @@ -192,7 +191,6 @@ export const OrderCustomerInfo: React.FC<OrderCustomerInfoProps> = ({ <div> <p>注文日時: {order.orderedAt}</p> <p>購入者: {order.purchaser.name}</p> - <p>住所: {order.purchaser.address}</p> </div> ); };
契約としてのスキーマファースト
フロントエンド・バックエンドでそれぞれ、graphql-code-generatorとgqlgenを使用して、スキーマファーストで開発を行っています。
スキーマファーストで開発することで、API設計の議論が行いやすく、フロントエンドとバックエンドで並行して開発を進められるの点が良かったです。
さらに、GraphQLでは定義したスキーマと異なるレスポンスが返ってくることはありません。これにより、スキーマはフロントエンドとバックエンドの間で「契約(Contract)」として機能するため、スキーマと実際のレスポンスが乖離することがないです。
RESTでOpenAPIを採用した場合でも、スキーマファーストでの開発自体は可能です。
しかし、OoenAPIの定義はあくまで仕様書であり、APIの実態を保証するものではないため、「契約(Contract)」としては機能しません。
OpenAPI Generatorでoneofを使用する場合を例に挙げます。
OpenAPIでは、oneofという、複数の型のうちどれか一つを表す記法があります。
paths: /pets: patch: requestBody: content: application/json: schema: oneOf: - $ref: "#/components/schemas/Cat" - $ref: "#/components/schemas/Dog" responses: "200": description: Updated
しかし、OpenAPI Generatorは、oneofに対応していないため、oneOfを用いた仕様に基づくコードを自動生成することができません。
その結果、対応するコードを手動で実装する必要が生じます。手動実装では、スキーマと実装の間で相互に修正漏れが発生するリスクが高まり、結果としてスキーマと実際のレスポンスが乖離する可能性が発生してしまいます。
GraphQLを採用した場合は、上記のようなリスクがなく、スキーマファーストで開発を進められたため、効率的かつ安心して開発を進めることができました。
一般的なGraphQLのデメリットについて
GraphQLを採用するにあたり、デメリットとして、設計の難しさやフロントエンドのQueryの自由度によるパフォーマンスの問題などが挙げられます。
前述の通り、同期コンテナと非同期コンテナに分かれており、フロントエンドと同期コンテナの間でGraphQLを採用しています。
モールとの連携などのコアなロジックはほとんど非同期コンテナで行われているので、プロダクトの全体の規模と比べて、GraphQLのAPIの数はそこまで多くありません。
そのため、現状はGraphQLスキーマの複雑性は比較的低く、設計難易度も問題になっていません。
仮に連携先のモールが増える場合も、主に修正を加えるのは非同期コンテナになります。
フロントエンドからは、すでに利用しているQueryやMutationの引数に、追加されたモールの情報を引数で渡すだけで良いので、連携先が増えていく場合でも、GraphQLスキーマに変更は不要です。
また、Queryの自由度に関しても、レビュー体制とLinterの2つの側面から対策を行っています。
フロントエンド・バックエンドともに、チーム内のテックリード2人が必ずコードレビューを行う体制になっており、定義したQueryに問題があれば、コードレビューの段階で指摘しています。
併せてgraphql-eslintによるGraphQLのLintも行っています。
一例として、selection-set-depthというルールにより、Queryのネストの深さを制限することで、オブジェクトの循環参照による高負荷なQueryの実行を防いでいます。
GraphQLの採用はプロダクトの規模や状況によっては、メリットよりの運用コストが大きくなってしまうケースがあると思います。
定性的な意見にはなりますが、今回のプロダクトにおいては、現状そのように感じることはなく、全体的にみて採用したメリットの方が大きかったと感じています。
OpenAPI Generator/genqlient
外部APIの呼び出し処理に関しては、自動生成したコードを使用しています。
RESTの場合はOpenAPI Generatorを、GraphQLの場合はgenqlientを採用しています。
連携先によってAPIの種類が異なり、GraphQLの場合もあれば、RESTの場合もあります。RESTの中でもJOSN・XML・multipart/form-dataなど多種多様です。
そのような場合でも、自動生成されたコードを使用することで、APIの種類によらず実装フローを下記のように統一することができます。
- OpenAPI or Query/Mutationの定義
- クライアントコードの自動生成
- 自動生成されたコードを利用してドメインロジックの実装
また、外部APIは定期的に仕様変更が発生するため、それに追従する必要があります。
その際にも、上記と同じフローで対応することができ、自動生成し直して、コンパイルエラーが発生した箇所を修正すれば良いため、影響範囲も明確になります。
さらに、一部の連携先では、API仕様書として、OpenAPIを提供してもらえる場合があるので、1のステップが省略できることもあり、その場合は実装コストが大幅に削減されます。
管理コスト・実装コストのどちらの面でもメリットが大きく、これらは採用して非常によかったです。
Cloud Run
Goで実装したサーバーをCloud Runにデプロイしています。
Dockerイメージをpushするだけでデプロイできる手軽さに加え、リクエスト負荷に応じて、自動でスケールイン・アウトしてくれる点に魅力を感じて採用しました。
実際に採用してみて、デプロイの手軽さは開発速度の観点から、非常に良かったと感じています。
Cloud Runには、サービスという概念があり、サービスごとにスケーリングやスペックなどの設定を個別に設定することが可能です。
負荷試験を行いながら、CPUや同時実行数などの調整や、サービスの分割などを行いましたが、その設定も比較的簡単に行うことができ、そこの実装コストも抑えることができました。
コールドスタートの問題もありますが、同期コンテナはUXに影響するため、最小インスタンスを1以上に設定することで、コールドスタートを回避しています。
一方、非同期コンテナでは、長時間のバッチ処理が主な役割で、UXに影響はないです。そのため、コールドスタートが許容範囲内と判断し、最小インスタンスを0に設定して、ランニングコストを抑えています。
ただ、タイムアウトに関しては課題があります。
Cloud Runのタイムアウトは60分なのですが、非同期コンテナへのリクエストは、Cloud Tasksを経由しており、Cloud Tasksのタイムアウトは30分です。
そのため、バッチ処理の上限時間が、Cloud Tasksのタイムアウトの30分になってしまい、それを超える処理を行う場合は、途中でタイムアウトしてしまいます。
これを回避するために、DBでバッチ処理の状態を保持して、途中でタイムアウトしても、再開できるようにしているのですが、この辺りはCloud Run Jobsを使うなりして、DBでの状態管理をなくしたいと考えています。
マッチしなかったもの
Hasura
Hasuraとは、DBのスキーマからからGraphQL APIを自動生成してくれるOSSです。
採用に至った理由は、下記の通りです。
- DBのテーブルさえあればAPIを自動生成できるので、開発効率の向上が期待できる
- GUIで簡単に認可制御できる
- 高機能なコンソール画面が組み込まれており、マイグレーションやDB操作がGUIで簡単に行える
しかし、下記の点からHasuraの採用はマッチしなかったと感じています。
テーブル構造がそのままGraphQLスキーマになってしまう
Hasuraでは、テーブル構造がそのままGraphQL APIのスキーマになります。
そのため、フロントエンドで欲しい形でデータを取得することができず、取得してからデータを加工する必要があるので、フロントエンドでの処理が肥大化することが多かったです。
フロントエンドで扱いやすいようにデータモデリングができるのが、GraphQLのメリットの1つですが、Hasuraを使うことでそのメリットが薄れてしまいました。
Hasuraから返却されるエラーメッセージも、ユーザーフレンドリーではないので、ユーザーに表示するメッセージを毎回フロントエンドで制御する必要がありました。
また、フロントエンドでQueryを定義する際には、テーブル構造が必要になります。
表示したいデータが、どのテーブルのどのカラムなのかを把握してないと、Queryが定義できないです。
テーブル構造を把握できているエンジニアであれば問題ないですが、フロントエンド専任のエンジニアにとっては、そのキャッチアップが大きな負担になり、実装に苦戦する場面が多かったです。
想定よりもHasuraの利用機会が少なかった
Hasuraでは、外部のGraphQL APIを統合するための、Remote Schemasという機能が提供されています。
簡単なバリデーションであればHasuraで対応できますが、複雑なロジックが含まれる場合は、Remote Schemasとして統合しているGraphQLサーバーの方で実装していました。
 引用: Remote Schemas Overview | Hasura GraphQL Docs
引用: Remote Schemas Overview | Hasura GraphQL Docs
プロダクトの特性上、Remote Schemasで対応が必要なケースが多くなることはある程度予測していましたが、それは主にMutationであり、Query全般はHasuraで対応ができると考えていました。
しかし、実際にはQueryでも、Remote Schemasで実装することが多かったです。
上記で触れたように、フロントエンドの処理が肥大化したり、実装コストが高い問題が発生していました。
そのため、QueryもRemote Schemasで実装した方が、実装も管理もしやすいと判断し、QueryもRemote Schemasで実装することが増えました。
また、パフォーマンス起因で、HasuraからRemote SchemasにQueryを移行するケースもありました。 Hasuraは、GraphQLのQueryをSQLに変換してデータの取得や加工を行なっており、発行されるSQLは複雑になりがちです。

そのため、発行されるSQLがパフォーマンス的に問題になるケースがありました。
特に、Aggregation Queriesと言う集計用のQueryが非常に重く、インデックスの作成などでは解決できなかったため、この場合も最終的には、Remote SchemasでQueryを実装することで解決しました。
これらの理由から、当初の想定に比べてHasuraの利用機会が限られてしまい、採用によるメリットを十分に活かしきれなかったと感じています。
テーブル設計がブロッカーになる
Hasuraを使用する場合は、テーブルがないとGraphQLスキーマも生成されません。
そのため、開発最初期では、フロントエンドの実装がテーブル設計待ちになってしまうことがありました。
フルスタックに開発を進める場合は問題ないと思いますが、フロントエンドとバックエンドを分けて開発を進める場合は、テーブル設計のスケジュールがフロントエンドの開発スケジュールにダイレクトに影響を与えてしまうため、分業して開発を進める際には注意が必要です。
恩恵を感じている点
当初の想定通りにHasuraを活用できないことが多かったですが、採用してよかった点もあります。
コンソール画面が非常に多機能で、マイグレーションやDB操作、APIの実行など、開発の過程で必要なものはほぼ全てコンソール上で完結するのは、非常によかったです。
また、認可制御に関しては、Remote Schemasへのリクエストも含めてGUIで簡単に設定できます。そのため、認可周りの実装が全く不要になり、実装コストを大幅に削減できました。


全体として、プロダクトの特性と合っていなかったのと、使用場面の想定が甘かったのが原因で、Hasuraの採用はマッチしなかったと感じています。
実際に採用してみて、APIの自動生成による開発スピードの向上は非常にパワーを感じました。PoCやスタートアップなどでスピードが求められる場面では、Hasuraの採用は有用だと思います。
ただ、フロントエンドエンジニアに対して、ある程度のDBやテーブル構造の知識が求められるので、開発体制やメンバーのスキルも考慮する必要がありそうです。
GORM
開発当時は、Go自体の知見も少なかったため、シンプルで使いやすく、日本語のドキュメントも充実しているGORMを採用しました。
GORMには、マイグレーション機能も備わっていますが、マイグレーションはHasuraで行なっているため、こちらは使用していません。
実装を進めていく中で、GORM特有の挙動や運用に課題を感じる場面が増えてきました。
具体的にはGORMのメソッドを使う際に、引数や引数に渡した構造体のフィールドがゼロ値の場合に、意図しない挙動になることがありました。下記はその一例です。
Findで第2引数に空配列を渡すと全件取得になる
var ids []int db.Find(&users, ids) // SELECT * FROM users;
Updatesで構造体のフィールドがゼロ値だと更新されない
db.Model(&user).Updates(User{Name: "hello", Age: 0, Active: false})
// UPDATE users SET name='hello' WHERE id = 111;
これらは、それぞれIssueで言及されていたり、公式ドキュメントにも記載されている挙動ですが、正しい実装ができるかどうかは実装者の知識量に依存してしまいます。
動作確認やレビューで検知することも可能ですが、100%防げるわけではないですし、場合によってはバグを含んだままデプロイされてしまう可能性があります。
そのため、実際に発行されるSQLを確認しながら実装したり、暗黙的な挙動に注意しながら実装やレビューを行なっています。
たた、それであれば、最初にSQLを書いて、そこからコードを生成するようなsqlcなどの方が、挙動が明瞭で暗黙的な挙動による問題は発生しづらいのではと思いました。
Next.js
フロントエンドは、Next.jsのStatic Exportsを使って、SPAを構築しています。
SSR (Server Side Rendering)や画像最適化など、Next.jsが提供している機能の多くは、サーバーを必要とします。
採用当時の要件的に、それらの機能は必要なかったので、サーバーを用意してNext.jsを使うのは、運用コストの観点からtoo matchだと感じました。
ただ、ファイルベースルーティングやゼロコンフィグでの開発など、サーバーを用意しない場合でも、採用するメリットはあります。
また、公式ドキュメントのStatic Exportsのページには下記のような記載があります。
Next.js enables starting as a static site or Single-Page Application (SPA), then later optionally upgrading to use features that require a server.
この記載からも読み取れるように、まずはSPAとして開発を進め、必要に応じてサーバーに移行することも可能です。
将来的にSSRなどの機能が必要になった際に、Next.jsを採用していれば、その移行もスムーズに行えるのではと思い、Next.js+Static Exportsという案を採用しました。
しかし、実際に開発を進める中で課題もあり、この選択によるメリットは少なかったと感じています。
Dynamic Routesが使えない
Static Exportsを使った場合、ビルド時に決定できる場合をのぞいて、Dynamic Routesが使えません。
過去のテックブログでも、同様の問題について言及されています。
ドキュメントのSupported Featuresに「Dynamic Routes when using getStaticPaths」とある通り、ルーティング先が有限でビルド時に決定できるケースであれば有効ですが、そうでない場合はアセットがposts/[postId].htmlのようにビルドされてしまい、/posts/1にアクセスしてもファイルが存在しないことになってしまいます。
そのため、ファイルが存在しない扱いになり、404.htmlが返却されるため、その中でルーティング処理を行うことでなんとか解決していますが、環境によって挙動に差が生まれてしまいます。
一方で、ローカルではNext.jsのdevサーバーが通常通りルーティングを行うため、こうした動作が(特殊な開発環境を用意しない限り)再現できません。開発時には再現できない挙動が本番で発生することは大きな懸念点です。

この問題は開発初期に認識はしていましたが、問題になるケースは少ないのと、最悪QAで検知できるという理由で軽視していました。
しかし、ちょうど最近、上記のリスクが顕在化するケースがありました。
外部サイトからのリダイレクトが発生する機能の実装を行なった際に、外部サイトからのリダイレクト後にrouter.pathnameを使用した処理がありました。
その際に、その値が404になるため、正常に動作しないことが、QAのタイミングで発覚しました。
修正する際にも、ローカルでnext buildをするか、手動でstg環境にデプロイする必要があり、動作確認に時間がかかってしまっていました。
この問題は最終的にQAで検知できるものの、動作確認に時間がかかりますし、今後もこのようなリスクを抱え続けるのはやはり避けたいと感じました。
サーバーへの移行コスト
将来的にSSRが必要になった場合も加味して、Next.jsを採用しましたが、この考慮も不要だったと感じています。
仮にSSRが必要になった場合、サーバーを用意して、デプロイ先を変更する必要がありますが、移行コストは高いです。
サーバーの選定や負荷試験、全体的なデグレチェックなど、かなり大掛かりな作業が必要で、Next.jsを採用しているからと言って、簡単に移行できるものではありません。
ちょうどリリースの少し前に、大量データを表示したいかつ、ブラウザのCtrl+Fでページ内検索をしたいという要件がありました。
単純に仮想スクロールを導入するだけでは、ブラウザのCtrl+Fが機能しないため、サーバーに移行してSSRで対応する案も検討しましたが、開発工数との兼ね合いでその案は見送りました。
仮に、スケジュールに余裕があったとしても、1つの機能のためにデプロイ先を変更するという意思決定を行うのはなかなか難しいです。
アップデートへの追従
Static Exportsを使っているとはいえ、Next.js自体のアップデートへの追従は必要です。
現在は、特にApp Routerを必要とする機能がないため、Pages Routerを使い続けていますが、仮にPages Routerが廃止されることがあれば、App Routerへの移行は避けられません。
全体的に、使っていない機能も多いため、Next.jsを採用しているメリットに比べると、アップデートへの追従コストが高くなっていると感じています。
これらの理由から、Next.jsの採用はマッチしなかったと感じています。
結局のところ、サーバーが必要になったタイミングで、それなりの移行コストがかかり、気軽に移行ができないため、中途半端に先を見据えて採用してしまったなと感じています。
それであれば、上記のようなリスクを抱えてNext.jsでSPAを構築するよりも、最初からサーバーを用意して運用するか、必要になるタイミングまではフレームワークは採用せず、React+ViteなどでSPAを構築するのが良いと思います。
Apollo Client
GraphQLクライアントには、Apollo Clientを採用しました。
有名なライブラリであるため情報量も多く、Relayと比較して学習コストが低く導入しやすい点に魅力を感じ、採用に至りました。
途中でRelayへの移行も検討しましたが、Hasuraとの兼ね合いで採用を見送り*2、Apollo Clientを使い続けています。
当初はApollo Clientのキャッシュ機構を積極的に活用して、不要なリクエストを減らすことができると考えていました。
しかし、プロダクトの特性上、検索が多いほか、ユーザーが関与しないシステム連携でデータが作成されるケースも多く、最新のデータを表示することの重要度が高いです。そのため、キャッシュを使わずに、ネットワークリクエストを行う場面が想定よりも多くなりました。
最新のデータの表示が必要な場面で、キャッシュが使われてしまうこともあり、UXに影響が出ることもありました。
また、キャッシュ機構に関連する挙動の変更が度々ある点も課題に感じています。
こちらのIssueでは、バージョンアップによってonCompleteの挙動が変更されたのを、古い挙動をバグと認識している人もいれば、新しい挙動をバグと認識している人もいます。
これらは、ドキュメントには明記されていないため、挙動が変わったことに気づかず、バグを引き起こす可能性があります。
これらの背景から、途中から全体的にキャッシュを使わない方針に変更しました。
それにより、上記の問題は解消されましたが、キャッシュを使わない場合、Apollo Clientを使うメリットがほとんどなくなってしまいました。
途中で方針が変わったこともあり、Apollo Clientの機能を活用することができず、採用によるメリットを活かしきれなかったと感じています。
まとめ
今回は、技術選定に関する振り返りを紹介しました。
大は小を兼ねるので、必要としている機能以上の技術を採用しても、要件を満たすことはできます。
しかし、その場合は、運用コストや学習コストが高くなるため、総合的に判断した時に、それらのコストが採用によるメリットを上回る場合もあります。
特に今回紹介した技術は、変更が容易ではないものが多く、振り返った結果、マッチしなかったと判断しても、すぐに変更することはできないです。
そのため、技術選定の際は、要件を正確に見極めた上で、できるだけ要件にジャストフィットする技術を選定することが改めて重要だと感じました。
今回の記事は、EXSの要件を前提としたものになるので、あくまで技術選定の一例として参考にしていただけると幸いです!
最後に、バイセルではエンジニアを募集しています。少しでも気になった方はぜひご応募お待ちしています。
https://herp.careers/v1/buyselltech/04-VP5QnJ0aM
明日のバイセルテクノロジーズ Advent Calendar 2024は藤澤さんの「少数精鋭でユーザーの信頼を勝ち取る!大規模リリースを乗り越えるためのシステム監視とユーザーサポート」です、そちらもぜひ併せて読んでみてください!