

はじめに
こちらは バイセルテクノロジーズ Advent Calendar 2022 の 12 日目の記事です。前日の記事は小松山さんの「GitHub Actions から Cloud Run ジョブで Google Cloud のプライベートネットワーク内へアクセスした」でした。
こんにちは。
2022/07月から参画している畑です。
私が参画しているプロジェクトではフレームワークにRuby on Railsを採用しています。
Ruby on Railsは直感的に開発できる反面、N+1が発生しやすいフレームワークです。
パフォーマンスに気をつけてコードを記述しないとDBに高負荷をかけてしまうことがあります。
「bullet」というN+1を発見できるgemがありますが、今回は使わずにN+1を特定し、パフォーマンスを改善した方法を紹介します。
Railsエンジニアの方でパフォーマンスを改善したいと思われている方に参考になれば幸いです。
※記載しているコードはサンプル用のため、商品をItemとして、商品のカテゴリ別に商品数を集計するケースで説明させていただきます。
- はじめに
- パフォーマンスチューニングを行おうとした動機
- 取り組んだこと
パフォーマンスチューニングを行おうとした動機
ある機能のリリース後にNew Relicを確認すると、カテゴリ別に商品数を取得する機能を追加したAPI上でパフォーマンスに問題があることがわかりました。
負荷監視ツールで確認するとリリースを境にCPU100%になってしまうことが多く発生するようになってしまいました。
負荷が上がっていた原因
ログを見ていると似たようなクエリが大量に発行されていることが確認できました。
商品数を表示する機能を追加する以前から、一覧検索ということもあり関連テーブルを多くjoinしていて、クエリ単体としてもnestしているため重い状態になっていました。
負荷が上がっていた原因は、N+1が発生しているところに、さらに商品数を表示する機能を追加したため相乗的にパフォーマンスが悪化してしまったということになります。
そのため、一覧検索機能を全体的にチューニングする運びとなりました。
取り組んだこと
- RailsのBenchmarkを使用し、コード修正前後で計測を行う
- N+1が発生している箇所を確認および解消対応
- index追加
環境
- Ruby version: 2.5.1
- Ruby on Rails version: 5.2.0
- チューニング時のレコード件数: 数万件(ローカル環境で検証)
RailsのBenchmarkを使用し、コード修正前後で計測を行う
Benchmarkを使用すると、計測したい箇所をブロックで囲むことによって処理が終わるまでにどのくらいの時間がかかったかを調べることができます。
class Item::V1::ItemsController < ApplicationApiController def index # benchmark変数に処理完了にかかった時間が格納される benchmark = Benchmark.realtime do ...計測したい処理... end pp "benchmark: #{benchmark}" end end
メソッドを実行すると、下記のような出力をターミナルで確認することができます。
"benchmark: 7.183901752985548"
N+1が発生している箇所を確認および解消対応
確認方法としてはログを見ながら似たようなクエリが発行されている箇所を探していました。
今回は以下の3箇所で似たようなログが発生していることが確認できました。
・カテゴリ別に商品数を表示する値1つ1つにクエリが発行されている
・関連テーブルを一括取得していないためクエリが発行されている
・ループ内やSerializerでクエリを発行するメソッドを使用している
N+1を解消するためにやったこと
カテゴリ別に商品数を表示する値1つ1つにクエリが発行されている
こちらはカラムごとにitemsテーブルからsumメソッドをしていたことが原因でした。
そのため、修正方法はitemsテーブルから必要な値を1クエリで取得し、一時変数に格納してからRuby側で計算することで対応しました。
関連テーブルを一括取得していないためクエリが発行されている
修正前
Item.where('quantity > ?', 0)
preload、eager_load、includesメソッドの使用方法
preloadメソッド
・指定した関連テーブル毎に別クエリを作成し、データ配列を取得し、キャッシュする
・whereなどで関連先の絞り込みを行うとエラーとなる
eager_loadメソッド
・LEFT OUTER JOINで指定した関連テーブルと結合し、データ配列を取得し、キャッシュする
・関連先の絞り込みが可能
includesメソッド
・デフォルトではpreloadと同じ挙動
・関連先の絞り込みを行った場合などはeager_loadと同じ挙動をする
これらのメソッドを使用して関連テーブルを一括取得することでN+1を回避
修正後
nestしているテーブルも取得し、キャッシュすることでN+1を回避するように修正しました。
Item.where('quantity > ?', 0).includes(:master_item_category, :master_item_status)
ループ内やSerializerでクエリを発行するメソッドを使用している
ループ内の場合
修正前
def item_quantity_by(&block) items.select(&block).sum(&:quantity) end def get_quantity item_quantity_by do |item| Item.where(master_item_category_id: item.master_item_category_id).quantity.positive? end # これ以降の処理を省略しています end
修正後
item_quantity_byメソッドを使用すると、itemsの数分select文が発行されてしまいN+1が回避できない為、item_quantity_byメソッドを使用せずにN+1が発生しない書き方に修正しています。
def get_quantity match_item, not_match_item = items.partition { |item| item.master_item_category_id == 1 } match_item.flatten.compact.sum(&:quantity) # これ以降の処理を省略しています end
Serializerの場合
※objectはSerializer new などで渡されたオブジェクト(以下ではitemレコード)自身となります。
修正前
3行目、6行目でItem.find_byを使用しているため、毎回クエリが発行されます。
class ItemSerializer < ActiveModel::Serializer def maser_item_status_id item = Item.find_by(master_item_status_id: 1, master_item_category_id: object.master_item_category_id) return item&.master_item_status_id unless item&.quantity.to_i.zero? Item.find_by(master_item_status_id: 2, master_item_category_id: object.master_item_category_id)&.master_item_status_id end end
修正後
Item.find_byだとクエリが発行されるので、object(itemレコード)を軸に目的の処理を記述しクエリが発行されないように修正しました。
class ItemSerializer < ActiveModel::Serializer def maser_item_status_id return object&.maser_item_status_id if object.maser_item_status_id == 1 && object&.quantity.to_i.positive? object&.maser_item_status_id if object.maser_item_status_id == 2 end end
index追加
テーブル定義を確認したところ、データを取得しているあるテーブルで、必要なindexが存在していないことが確認できました。
上記のテーブルにindexを追加しました。
index追加前後でExplain Analyzeを確認すると、追加したindexが効いていることの確認ができます。
actual time
actual timeとは実際に実行してみてどれだけの時間がかかったかの指標となります。
単位は「ms」になります。
| actual time |
|---|
| 12.345..56.789 |
上記例の場合
前半の数値(12.345ms)は最初の1件目を取得するまでにかかった時間を表しています。
後半の数値(56.789ms)は結果全体を取得するのにかかった時間を表しています。
index追加前後でactual timeを比較
| 追加前 | 追加後 |
|---|---|
| 17.546..30.841 | 4.839..14.947 |
・前半の数値(最初の1件目を取得するまでにかかった時間)を13msほど短縮することができました。
・後半の数値(結果全体を取得するのにかかった時間)を16msほど短縮することができました。
追加前
-> Hash Left Join (cost=951.69..1730.76 rows=数万件 width=312) (actual time=17.546..30.841 rows=数万件 loops=1) Hash Cond: (items.master_item_category_id = master_item_categories.id)
追加後
-> Hash Left Join (cost=951.69..1730.76 rows=数万件 width=312) (actual time=4.839..14.947 rows=数万件 loops=1) Hash Cond: (items.master_item_category_id = master_item_categories.id)
最終的にどうなったか
チューニングした結果
ローカルでの計測になりますが、レコード数が数万件の場合 一覧検索にかかる時間を2000msほど短縮することができました。
また、チューニングをリリース後に本番環境のDB負荷を確認した所、以下の画像のように大幅に改善することができました。
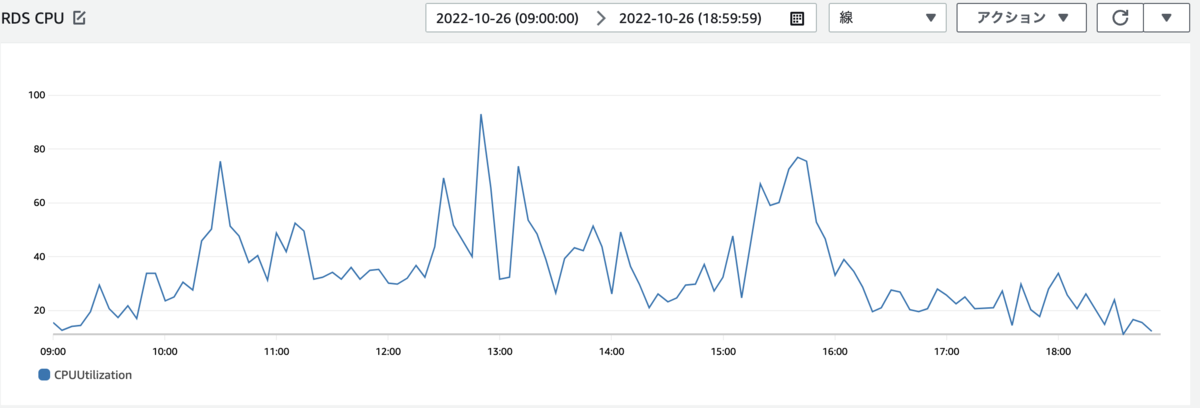
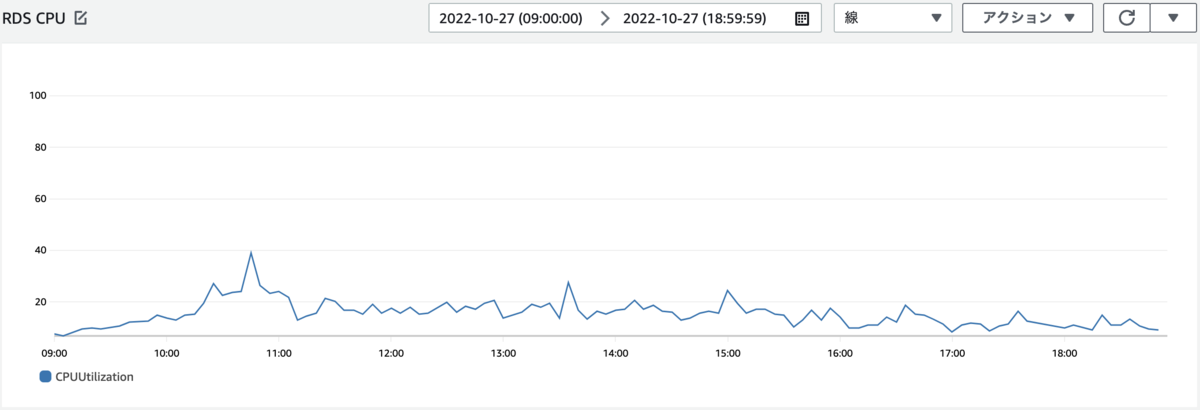
まとめ
今回の対応でパフォーマンスがかなり改善されたことが確認できますが、まだ処理的に重くなる箇所が残っていることも確認できています。
改善できそうな箇所はまだまだあるので、今後もパフォーマンス改善に取り組んでいきます。
バイセルテクノロジーズではエンジニアを募集しています。
herp.careers
明日の バイセルテクノロジーズ Advent Calendar 2022 は菅原さんによる「iOSアプリを誰でも簡単にビルドできるようにする」です。