

はじめに
こちらは バイセルテクノロジーズ Advent Calendar 2022 の 6 日目の記事です。
昨日は玉利さんによるReactのchildrenを使用してコンポーネントを拡張した話という記事でした。
こんにちは。テクノロジー戦略本部の柴田です。
現在自分が携わっているプロダクトでは DB の schema 変更に伴ってモデル側の修正が適切に行われていないという問題がありました。
そこで、検証ツールを作ることにより、schema 変更時に schema とモデルが対応しているか適宜検証することにしました。CI に組み込んだことで、schema とモデルが対応していることが保証され、問題を解決することができました。今回はその作成した検証ツールについて紹介していきます。
背景
最初に少し触れましたが、再度背景について説明します。
まず自分が携わっているプロダクトでは GORM という ORM を利用しているのですが、そこで利用しているモデルが schema 変更に伴って、適切に修正されていないという実態がありました。
そこでテーブルの schema からモデルを自動生成するツールがないか探すことになったのですが、いくつか候補はあったものの、以下のような要件をうまく満たすものが見当たらなかったため採用を見送りました。
- 現在プロダクトで利用している null パッケージに対応している必要がある
- これに対応していない場合、ソースコードの大部分を書き直す必要が出てくる
- 設定ファイルなどを都度修正するなどのメンテナンスコストがほとんどない
自動生成ツールを自作するという選択肢もありましたが、やや工数がかかりそうだったので断念しました。
ただ依然としてテーブル schema と Go のモデルに齟齬があるのはまずいのに変わりはありません。そのため次に schema とモデルに差異があることを検知できないかということになりました。
私は以前に自動生成コード の JSON タグを XML タグに差し替えるという対応で AST(抽象構文木) を利用したことがあったため、その技術を応用すれば作れるのではないかと思い立ちました。その後調査を行い、工数・メンテナンスコストも少なく作れそうだということで検証ツールを作ることにしました。また検証ツールを CI に組み込むことで schema とモデルの一致を強制することにしました。
今回はその際に利用した技術や考え方をコードも交えながらお伝えできればと思います。
AST について
今回利用した AST(Abstract Syntax Tree: 抽象構文木) というものについて説明したいと思います。
まず、プログラムを字句解析をすることで token 化し、token の間の関係性を整理したものの一つが構文木です。token 化はイメージで言えば文章を単語ごとに分けていく作業だと思ってもらえばいいです。
AST はプログラムから生成した構文木から意味的に不要なものを除いて、構文木として表したものになります。
この AST を利用することで解析対象が関数なのか、変数なのか、はたまたコメントなのかといったことがわかるようになります。またそれぞれのノードの関連性もわかります。
AST はコンパイラの中でプログラムの構造解析に利用されたりしています。
Go には標準パッケージとして ast パッケージがあり、こちらを用いて今回の実装を行いました。
実装について
準備
今回は例として以下のような架空のモデルがあるとします。
// item.go type Item struct { ID int Description null.String CreatedAt time.Time } // user.go type User struct { Name string Test *datatypes.JSON }
schema はそれぞれ以下のような状態になっています。
Table "public.items"
| Column | Type | Nullable |
|---|---|---|
| id | integer | not null |
| description | text | |
| created_at | timestamp with time zone | not null |
Table "public.users"
| Column | Type | Nullable |
|---|---|---|
| name | text | not null |
| test | jsonb |
PostgreSQL から必要な情報の抽出
今回必要な情報は INFORMATION_SCHEMA の中の、特に columns という現在の DB にあるテーブルのカラム情報がまとめられた view から取得することにしました(参考)。
SELECT table_name, column_name, is_nullable, data_type FROM INFORMATION_SCHEMA."columns" WHERE "table_schema" = 'public';
必要な情報としては対応するテーブル名、カラム名、型の情報、nullable かどうかだけでよさそうだったので今回の場合は上の SQL 文の形で情報を取得しています。
実際に上の SQL 文を投げてみると次のようなデータが返ってきます。この情報を用いてモデルの整合性チェックを行なっていこうと思います。
| table_name | column_name | is_nullable | data_type |
|---|---|---|---|
| items | id | NO | integer |
| items | description | YES | text |
| items | created_at | NO | timestamp with time zone |
| users | name | NO | text |
| users | test | YES | jsonb |
PostgreSQL から Go を利用して columns の情報を取得する
実際に書いたコードを以下に示します。
import ( "database/sql" _ "github.com/lib/pq" ) type Column struct { Name string IsNullable string DataType string } stmt := `SELECT table_name, column_name, is_nullable, data_type FROM INFORMATION_SCHEMA."columns" WHERE "table_schema" = 'public'` rows, err := db.Query(stmt) if err != nil { log.Fatal(err) } defer rows.Close() tables := make(map[string][]Column) for rows.Next() { var ( table string column string isNullable string dataType string ) if err := rows.Scan(&table, &column, &isNullable, &dataType); err != nil { log.Fatal(err) } if _, ok := tables[table]; ok { tables[table] = append(tables[table], Column{ Name: column, IsNullable: isNullable, DataType: dataType, }) } ... }
上のコードでは各テーブルに対するカラム情報を整理しています。
ここで格納している IsNullable は boolean ではなく YES/NO の文字列です。今回作るツールでは特にそのままでも問題がなかったので boolean に変換せずにそのままにしました。
dataType には文字列として SQL の型情報が入っています。コードを後述していますが、さまざまな型(例えば int4 や smallint など)が GORM の一つの型(int)に割り当てられているので SQL 側で新しい型を利用する際には少し注意が必要です。
次にプログラム解析の説明に移りたいと思います。
モデルファイル群から 構造体 部分を抽出して、解析
それでは肝心の構造体が DB 上の定義と合致しているのかの解析について述べていこうと思います。
まずは、具体的にプログラムを見ていこうと思います。
import ( "go/ast" "go/parser" "go/token" ) fset := token.NewFileSet() f, err := parser.ParseFile(fset, "./item.go", nil, parser.ParseComments) if err != nil { log.Fatal(err) } fields := make(map[string]string) ast.Inspect(f, func(n ast.Node) bool { switch n.(type) { case *ast.TypeSpec: s, _ := n.(*ast.TypeSpec) v, ok := s.Type.(*ast.StructType) if !ok || s.Name.Name != modelName { return false } // 構造体かつその名前が対象のモデルの場合 for _, l := range v.Fields.List { if len(l.Names) <= 0 { continue } switch l.Type.(type) { case *ast.Ident: // intやstringのようなプリミティブな型の場合 t, _ := l.Type.(*ast.Ident) fields[l.Names[0].Name] = t.Name case *ast.SelectorExpr: // time.Timeやnull.Stringのような型 t, _ := l.Type.(*ast.SelectorExpr) x, _ := t.X.(*ast.Ident) name := x.Name + "." + t.Sel.Name fields[l.Names[0].Name] = name case *ast.StarExpr: t, _ := l.Type.(*ast.StarExpr) switch t.X.(type) { case *ast.Ident: // *intのようなプリミティブのポインタ型 // 処理内容は上のIdentとほぼ同じなので省略 case *ast.SelectorExpr: // *time.Timeのようなポインタ型 // 処理内容は上のSelectorExprとほぼ同じなので省略 } } } } return true })
少しプログラムの中身を解説したいと思います。
token.NewFileSet()
- ファイル中のノード位置情報を保持のために設定します (参考)
parser.ParseFile
- ファイルを指定してあげるとそのファイルの抽象構文木を ast.File の形で返してくれます。
ast.Inspect
- 抽象構文木を深さ優先で探索していきます。引数で渡されている無名関数が検索によってノードに到達するごとに処理を実行していきます。 今回だと type Model struct というモデルの構造体部分だけ探索できれば良かったので、Inspect 内の処理でもそのように処理しました。具体的には TypeSpec > StructType 以下が相当したのでその中で各フィールド毎に処理を分けました。
次に、今回関係があったノードの型をいくつか挙げておきます。
| 今回関係がある型 | 説明 | 例 |
|---|---|---|
| TypeSpec | 型宣言がされているノード | type MyInt ... |
| StructType | 構造体型 Node | type Model struct ... |
| Ident | 識別子ノード | 変数名など |
| SelectorExpr | セレクタ式ノード | time.Time, null.String など |
| StarExpr | "*"を利用する式 | 主にはポインタ |
モデル情報に関する AST の簡略図が以下になります
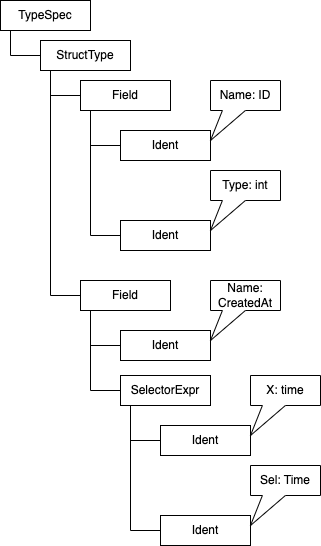
実際に抽象構文木で構造体以下の木構造をみてみると、型によって構造の深さが違うことに気づきます。
今回の構造体の場合だと大きく分けて 3 つに分類されます
int のようなプリミティブな型
time.Time のようなセレクタを伴った型
ポインタ型
これらによって深さが違ったり、中の構造が少々違ったりするので、switch 文でさらに処理を分けるなどして処理を行なっていきます。
最終的には fields という map に存在したフィールド名と型が入っている状態になります。
型の対応とチェック
次に SQL と Go の型を揃える必要がありました。
下のような感じで新しい型を利用する際に少しでも追加しやすいようにしました。
const ( nullableTrue = "YES" nullableFalse = "NO" // SQL側の型のための定数 dataTypeInt = "int" ... 中略 ... ) dataTypes := map[string][]string{ "int": []string{"integer", "int4", "smallint"}, ... 中略 ... } type checkType struct { goType string nullable string dataTypes []string } checkTypes := []checkType{ { goType: "int", nullable: nullableFalse, dataTypes: dataTypes[dataTypeInt], }, ... 中略 ... }
これで先ほど AST にて fields に登録した 型を比較するための準備ができました。
具体的なチェックとしては Go 側 の型について checkTypes に存在するのか比較します。 SQL の型がそもそも checkTypes に登録されていない場合についてのチェックも必要です。
以下は Go 側の型が正しいかをチェックするロジックです。
import "golang.org/x/exp/slices" for fk, fv := range fields { // goTypesはcheckTypesで利用されているgoTypeの集合 if !slices.Contains(goTypes, fv) { log.Printf("テーブル: %v, カラム: %v\n", table, fk) log.Fatal("新しい型の定義かもしれません: 正しい場合には型の追加をしてください") } if val != c.goType { continue } if column.IsNullable != c.nullable || !slices.Contains(c.dataTypes, column.DataType) { log.Printf("テーブル: %v カラム: %v をチェックする必要があります\n", table, column) continue } checked = append(checked, column) }
また SQL 側との齟齬チェックとして nullable の状態が一致しているかのチェックを行います。
問題がなかった場合、型チェックを通過したものとして checked に追加していきます。
モデルごとにチェックを行い、全てのカラムで問題なければ次のモデルへ、といった具合に全てのモデルを精査していくことで、schema 定義とモデルの検証を行う形となります。
実際に SQL と Go で上で定義した中に型の対応がなかったりすると上のチェックで弾かれます。また、フィールド自体に過不足がある場合には SQL のカラム数(table に存在する Column の length)と len(checked)でチェック済みのフィールド数とを比較すると差異がわかります。
実行してみた例は以下のようになります。
- item.go の description の型が string ではなく、int で設定されていた場合
テーブル: items カラム: {description text NO} をチェックする必要があります
- item.go の description の型を追加していない場合
テーブル: items, カラム: Description 新しい型の定義かもしれません: 正しい場合には型の追加をしてください
これで大まかな実装についての解説は終わりになります。
バージョンアップ等で取り扱う型が増えた場合は、SQL の型に対応する Go の型などは追加して対応していくだけなのでメンテナンスコストも比較的小さいと考えています。
まとめ
ast パッケージを利用して schema とモデルとの整合性チェックができるようになりました!
今回は細かいところは省きましたが、ツールの作成自体は思っていたよりも敷居が低かったのではないでしょうか?
ツールの作成により、以前からあった schema とモデルの差異を完全に無くすことに成功しました。不要なモデルやフィールドがそのまま残っていると新規メンバーが戸惑う、バグが混入するなどの問題が発生してしまう可能性があったので、それを解消できたのは良かったと思います。
個人的な感想としては、利用している型が多くなったりしてもある程度は柔軟性のある仕組みを作れたと思います。
AST についても普段はあまり利用しないかもしれませんが、プログラムしていてこんなことができるんだという楽しさがあるパッケージでした。
また今回は紹介しませんでしたが、astutil を利用すれば Cursor.Replace を利用してファイルに任意の構造の差し込みや削除なども行えます。
コード自動生成ツールや、自作のファイルの解析ツールを Go で作成してみたい方は一度 ast や astutil パッケージの詳細を調べてみていただければと思います。
最後に BuySell Technologies ではエンジニアを募集しています。
明日のアドベントカレンダーは市田さんによる「デプロイ頻度を上げるためにやったこと」です! そちらもぜひ読んでみてください!