

はじめに
こちらは バイセルテクノロジーズ Advent Calendar 2023 の4日目の記事です。 昨日は尾沼さんによる「サービス運用の負担軽減に繋がった、Playwrightの紹介」でした。
こんにちは。開発2部の野口です。普段はリユースプラットフォームの出品管理SaaSシステムの開発に携わっています。
私の所属しているプロジェクトでは、複雑な検索要件に対応するため、 Relational Database (以降、RDB) とElasticsearchを併用しています。
Elasticsearchを採用することにより、検索の柔軟性を獲得した一方で、両者の型システムの相違に起因した不具合に悩まされていました。
今回はElasticsearchのdynamic templatesという機能を用いて、上記の課題を解消した事例を紹介します。
背景・課題
前述した通り、私の所属プロジェクトではRDBとElasticsearchを併用しています。
具体的には、RDBから取得したデータを以下のようなJSONに整形してElasticsearchのBulk APIを叩いています。
POST my-index/_bulk { "index" : { "_id" : "1" } } { "name": "商品01", "price": 100, "stock": 1 } { "index" : { "_id" : "2" } } { "name": "商品02", "price": 200, "stock": 2 }
当初、この運用方法で問題はないと考えていましたが、後に「検索対象に含まれないデータが存在すること」に気づきました。
特に宝石類の商品を扱うジュエリー商品データにおいて、この不具合が散見されました。
検索に引っかかるデータと引っかからないデータの違いは以下の通りです。

検索時引っかからないデータのみ、caratカラムに単位を表す「ct」と言う文字が含まれています。
この時のElasticsearch側の型情報が以下です。
RDBでは文字列型のフィールド「carat」に対して、float型が割り当てられています。その結果、文字列が含まれるID=4のレコードは、そもそも書き込み時に弾かれていたようです。
{ "my-index": { "mappings": { "properties": { "carat": { "type": "float" // ここがtext型であってほしい }, ... } } } }
上記の問題は、Elasticsearchの型推測機能である「動的マッピング」に起因した不具合です。
動的マッピングとは、新規にデータを追加する際に、入力された値から自動的に型情報を推測して割りあてる機能です。
特徴として、事前に型を定義する必要がなく、手間が省ける点が挙げられます。しかし、一方で自動で型が決定されるため、予期せぬ型が割り当てられてしまうリスクもあります。
以上のような課題に対する解決策として、Elasticsearch側で事前にデータの型を定義する明示的マッピングの採用も考慮しましたが、今回はプロジェクトのDB設計の兼ね合いもありdynamic templatesを採用しました。
dynamic templates とは
動的マッピングの挙動をカスタマイズするための機能です。
具体的には、フィールド名とそれに対応する型情報をJSONオブジェクトとして定義します。これをMatch Conditionと呼びます。
上記をindexのdynamic templatesフィールドで定義することで、新規に挿入されたフィールド名が、dynamic templatesで定義したものと合致した場合、対応した型定義を割り振られるようになります。
基本的な使い方
以降 公式 document のExampleを引用しながら解説します。
まずはindexを作成します。
PUT my-index-000001 { "mappings": { "dynamic_templates": [ { "longs_as_strings": { "match_mapping_type": "string", "match": "long_*", "mapping": { "type": "long" } } } ] } } PUT my-index-000001/_doc/1 { "long_num": "5", "num": "5" }
この時dynamic_templatesフィールドを定義します。
dynamic_templatesフィールドでは、条件となるmatchフィールドと、その条件に合致した場合に割り当てる型情報を記述します。
条件指定方法には上記のようなワイルドカードの他に、正規表現も利用できます。
実際に生成されたmappingを確認します。
GET my-index-000001/_mapping?pretty
{ "my-index-000001": { "mappings": { "dynamic_templates": [ { "longs_as_strings": { "match": "long_*", "match_mapping_type": "string", "mapping": { "type": "long" } } } ], "properties": { "long_num": { "type": "long" // 割り当てられる型が変化している }, "num": { "type": "text", "fields": { "keyword": { "type": "keyword", "ignore_above": 256 } } } } } } }
prefixにlong_を持つフィールドには long型 が、持たないフィールドには text型 が割り当てられています。
このようにデフォルトの動的マッピングの挙動をカスタマイズできます。
具体的な実装方針
上記の内容を踏まえて、以降は私たちの具体的な実装方針について説明します。
流れは大まかに以下です。
- RDBの型に対応したElasticsearchの型を列挙
- dynamic templatesを適用したindexの作成
- Elasticsearchへの書き込み・読み込み時のフィールド名調整
RDB 型に対応した Elasticsearch の型を列挙
必要な型を洗い出すために、現状利用しているRDBの型定義と、それに対応するElasticsearchの型定義を列挙しました。
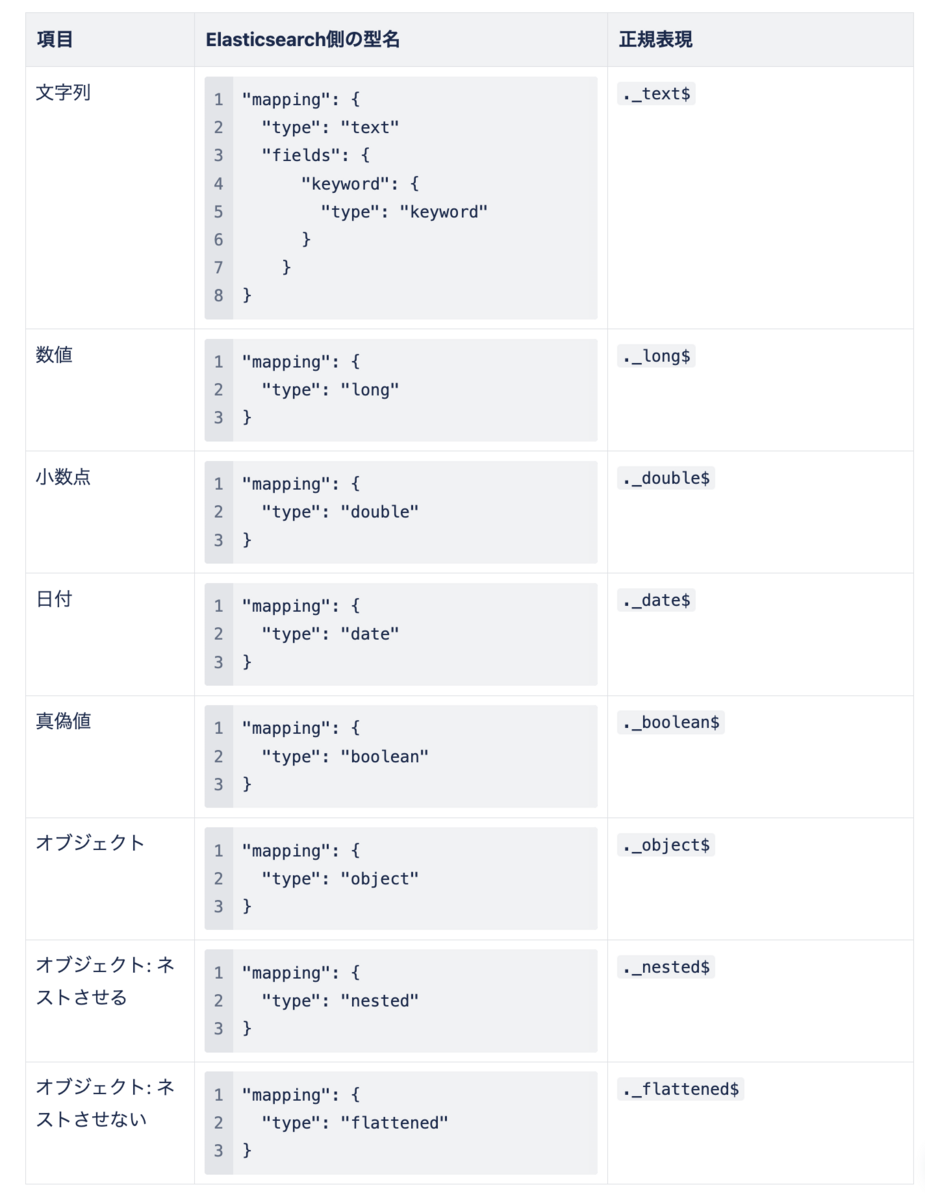
補足として、オブジェクトには3つの型を割り当てていますが、主に利用するのはnested 型です。
nested型が必要な理由は「デフォルトのobject型はオブジェクトのプロパティ同士の関連性を表せない」ためです。
例えば以下のようにユーザの配列を持ったグループがあるとします。
PUT my-index/_doc/1 { "group" : "fans", "user" : [ { "first" : "John", "last" : "Smith" }, { "first" : "Alice", "last" : "White" } ] }
この時、firstとlastをごちゃ混ぜにした「Alice Smith」さんという人物が所属するグループを検索するとどうなるでしょうか。
本来そんな人物は存在しないので、検索には引っかからないはずです。が、実際は1件documentがhitしてしまいます。
GET my-index/_search { "query": { "bool": { "must": [ { "match": { "user.first": "Alice" }}, { "match": { "user.last": "Smith" }} ] } } } // 結果: 1件hit
これではユーザに間違った情報を提供してしまう可能性があるため問題です。
対してnested型は、オブジェクトのプロパティ同士の関連性を保持しているため、上記のようなクエリはhitしません。
// nested型を割り当てる PUT my-index { "mappings": { "properties": { "user": { "type": "nested" } } } } // 検索 GET my-index/_search { "query": { "nested": { "path": "user", "query": { "bool": { "must": [ { "match": { "user.first": "Alice" }}, { "match": { "user.last": "Smith" }} ] } } } } } // 結果: 0件
このような背景から、オブジェクトに対してnested型を割り当てるようにしています。
dynamic templates を適用した index の作成
先ほど洗い出した型情報を踏まえてindexを作成します。
{ "mappings": { "dynamic_templates": [ { "long_fields": { "match_pattern": "regex", // 正規表現を有効化 "path_match": ".*_long$", // suffixにElasticsearch側の型名を付与 "mapping": { "type": "long" } } }, { "float_fields": { "match_pattern": "regex", "path_match": ".*_double$", "mapping": { "type": "double" } } }, { "text_fields": { "match_pattern": "regex", "path_match": ".*_text$", "mapping": { "type": "text", "fields": { "keyword": { "type": "keyword" } } } } }, { "boolean_fields": { "match_pattern": "regex", "path_match": ".*_boolean$", "mapping": { "type": "boolean" } } }, { "date_fields": { "match_pattern": "regex", "path_match": ".*_date$", "mapping": { "type": "date" } } }, { "nested_fields": { "match_pattern": "regex", "path_match": ".*_nested$", "mapping": { "type": "nested" } } }, { "flattened_fields": { "match_pattern": "regex", "path_match": ".*_flattened$", "mapping": { "type": "flattened" } } }, { "object_fields": { "match_pattern": "regex", "path_match": ".*_object$", "mapping": { "type": "object" } } } ] } }
"match_pattern": "regex"を指定することで、正規表現を利用できるようになります。
ここでは末尾にElasticsearchの型名が付与されていた場合のみ、対象の型が割り振られるように設定しておきます。
Elasticsearch への書き込み・読み込み時のフィールド名調整
先ほど作成したindexのルールに則り、suffixにElasticsearchの型名を付与するように修正します。
POST my-index/_bulk { "index" : { "_id" : "1" } } { "name_text": "商品01", "price_long": 100, "stock_long": 1, "carat_text": 1.1, "listing_history_nested": { "listing_status_text": "出品中", "listing_count_long": 3 } }
作成されるmappingが以下です。
{ "my-index": { "mappings": { "dynamic_templates": [ // 省略 ], "properties": { "carat_text": { "type": "text", // 値は小数だがtext型が割り当てられている "fields": { "keyword": { "type": "keyword" } } }, "listing_history_nested": { "type": "nested", // デフォルトのobject型ではなくnested型が割り当てられている "properties": { "listing_count_long": { "type": "long" }, "listing_date": { "type": "date" }, "listing_status_text": { "type": "text", "fields": { "keyword": { "type": "keyword" } } } } }, "name_text": { "type": "text", "fields": { "keyword": { "type": "keyword" } } }, "price_long": { "type": "long" }, "stock_long": { "type": "long" } } } } }
期待通り、小数にもtext型が割り振られていること、オブジェクトにはnested型が割り振られていることが分かります。
今回は具体的なアプリケーションの実装には触れませんが、内部でも上記のようなJSONを生成するように修正を加えています。
具体的には、O/Rマッパが取得した構造体のフィールドの型を判定して、それに対応したElasticsearch側の型名をsuffixに付与する処理を記述しています。
おわりに
本記事では、dynamic templatesを用いてRDBとElasticsearchの型不整合を解消する具体的な事例を紹介しました。
dynamic templates は、動的マッピングの手軽さを保ちながら型定義を細かくコントロールできるため、我々のように Elasticsearch へ紐づけたいフィールド数が極端に多いプロジェクトでは恩恵を受けやすいと思います。
また、単に型不整合を防ぐだけでなく、nested型等のElasticsearch固有の型を活用することで、より柔軟な検索を実現できるようになりました。
最後に、バイセルでは新卒エンジニアを随時募集しております。興味のある方はぜひ以下の採用サイトをご覧ください。
recruit.buysell-technologies.com
明日の バイセルテクノロジーズ Advent Calendar 2023 は馬場さんによる「Cloud Runジョブのオーバーライド機能で実現した単発処理群管理のための快適な環境」です。お楽しみに。