

はじめに
こんにちは!株式会社BuySell Technologiesのテクノロジー戦略本部開発2部でバックエンドのテックリードをしている藤澤です。
私が今所属しているプロジェクトは、立ち上げから関わっており、執筆時点で約3年ほど開発を続けています。
プロジェクトを推進するにあたって、最低限の人数で開発していた頃から、プロジェクトが佳境に差し掛かるところまで、開発メンバーの人数は大きく増減しました。その中でも新しく入った人の立ち上がりや知見の引き継ぎはとても重要であり、そのために開発当初からプロジェクトのバックエンド開発環境を整備してきました。今回はその取り組みについて紹介したいと思います。
背景
チームの変遷と課題
以下のグラフは、プロジェクトの開始から現在までのバックエンドリポジトリの月別コミット人数の推移を示しています。
ご覧の通り、最大12人まで増減を繰り返して現在に至っています。 また、これまでにコミットしたユニーク人数も30人を超えていました。
当初バックエンドエンジニア1人で始まったプロジェクトですが、開発ボリュームは社内のプロダクトの中でもかなり多く、長期にわたって開発してきましたので、本当にたくさんのエンジニアが携わりました。

その中で重要になっていたのがオンボーディングです。 オンボーディングがうまくいくことで、
- 人員が早期に戦力化でき、その能力によるチームへの貢献が早まる
- 無駄な困難を排除することによるエンゲージメントの向上が期待できる
というメリットがあります。
そのため、プロジェクトの初期からオンボーディングのコストを減らし、より早期にエンジニアが開発を進められるようにするための工夫やこだわりを実施してきました。基本的なものやよくあるものを含めて、今回はどのように取り組んできたかを具体的に紹介します。
具体的なTips
① アーキテクチャと実装ルールの明確化
ソフトウェアアーキテクチャはプロダクトの保守性や拡張性を高めたり、品質やセキュリティを向上させるメリットがありますが、「チームの開発スタイルに馴染んでもらうこと」に対しても非常に有効であると思います。
元々プロジェクトの初期段階では、開発の優先度やシステム構成の兼ね合いもあり、ソフトウェアアーキテクチャを導入せずに開発を進めている時期がありました。その後、人員の増加がありましたが、明確な実装ルールが少ない状態だったため、各人が自由な設計でコードを書いてしまい、後の人がキャッチアップするのが難しくなっていました。
そこで、ソフトウェアアーキテクチャの導入とガイドライン作成に真剣に取り組み、リファクタリングやドキュメント作成を進めました。
今ではアーキテクチャの各層について共通言語化されている状態になったので、実装方針の相談や共有が非常に楽になりました。また、社内事例のあるアーキテクチャに近い構成を取ったことで、新規参加したメンバーの認知負荷が下がり、より早くプロジェクトの構成を把握できるようになりました。 本プロジェクトでは諸事情から独自のアーキテクチャを採用しましたが、広く一般的に採用されているものを利用することでさらにオンボーディングの効率が上がることが期待できます。
② APIファースト
プロジェクトではその特性として、多種多様なAPIの連携を実装する必要がありました。フロントエンドから呼び出されるGraphQLのAPIだけでなく、バッチ処理やwebhookを受けるためのRESTful APIのエンドポイントも備えています。また、APIクライアントとして、GraphQL、RESTful API (JSON)、RESTful API (XML)、SOAPなど、様々な形式の外部APIを実行します。
それら多種多様なAPIを、オンボーディング時にソースコードを読んで理解するという状態では、早々に保守性が破綻すると感じていました。そこで当初からのこだわりとして、すべてのAPIサーバー/クライアントの定義をドキュメントとして保持し、ドキュメントからのコード生成によって開発を行うようにしています。
GraphQLサーバーとしては、スキーマファイルからgqlgenの自動生成を利用し、RESTful APIのサーバーとしては、OpenAPIフォーマットで定義を記述し、oapi-codegenを用いてコードを生成しています。
また、GraphQLクライアントとしては、スキーマをイントロスペクションしてgenqlientでコードを生成し、RESTful APIのクライアントとしては、OpenAPIフォーマットを用意し、openapi-generatorを用いてコードを生成しています。
さらに、SOAP形式のAPIクライアントの場合は、wsdlのドキュメントからgowsdlを用いてコードを生成しています。
| API形式 | API定義ファイル | 利用ライブラリ |
|---|---|---|
| GraphQL(サーバー) | GraphQL SDL | gqlgen |
| RESTful API(サーバー) | OpenAPI | oapi-codegen |
| GraphQL(クライアント) | GraphQL SDL | genqlient |
| RESTful API(クライアント) | OpenAPI | openapi-generator |
| SOAP API(クライアント) | WSDL | gowsdl |
③ CLI環境の整備
プロダクト開発では、コードを書く以外にもやるべき作業が多くあります。設定の変更、データ修正、チェック、アセットの作成など…。作業の途中で「こんなもの人間のやることじゃない!」とエンジニアなら誰しも思ったことがあるのではないでしょうか。そういった感情を動機として作業の自動化に取り組むことは多くあります。このプロジェクトではそういったものの受け皿としてCLI開発/実行環境も準備しました。
バックエンドの開発言語と同じ言語を用いてコンテキストスイッチ無く開発でき、作成したCLIは makeコマンドを通してチーム全員に配布できるようにしました。
一例として、
- プロダクトで使える大量の画像ファイルを準備するコマンド
- seeding 用のデータをスプレッドシートから生成するコマンド
- 外部APIへの接続情報をセットアップするコマンド
などの自動化のためのコマンドや、
- モデルのバリデーション
- 設定ファイルのバリデーション
などのチェック作業を代替するものなど、多種多様な作業効率化のためのコマンドが開発メンバーから自発的に生まれました。 詳しくはメンバーが書いたブログなどの記事をご覧ください。
tech.buysell-technologies.com tech.buysell-technologies.com speakerdeck.com
結果として、オンボーディングの局面では、作業の引き継ぎを一部手順書ではなく、コマンドを伝えることで簡単に実施できるようになりました。
また、バリデーション系のCLIをCIの中で実施するようにしたことで、チェック作業そのものをなくし、生産性の向上とデプロイの安全性の確保も同時に達成できるようになりました。 以下は実際に作成されたCLIの一覧です。
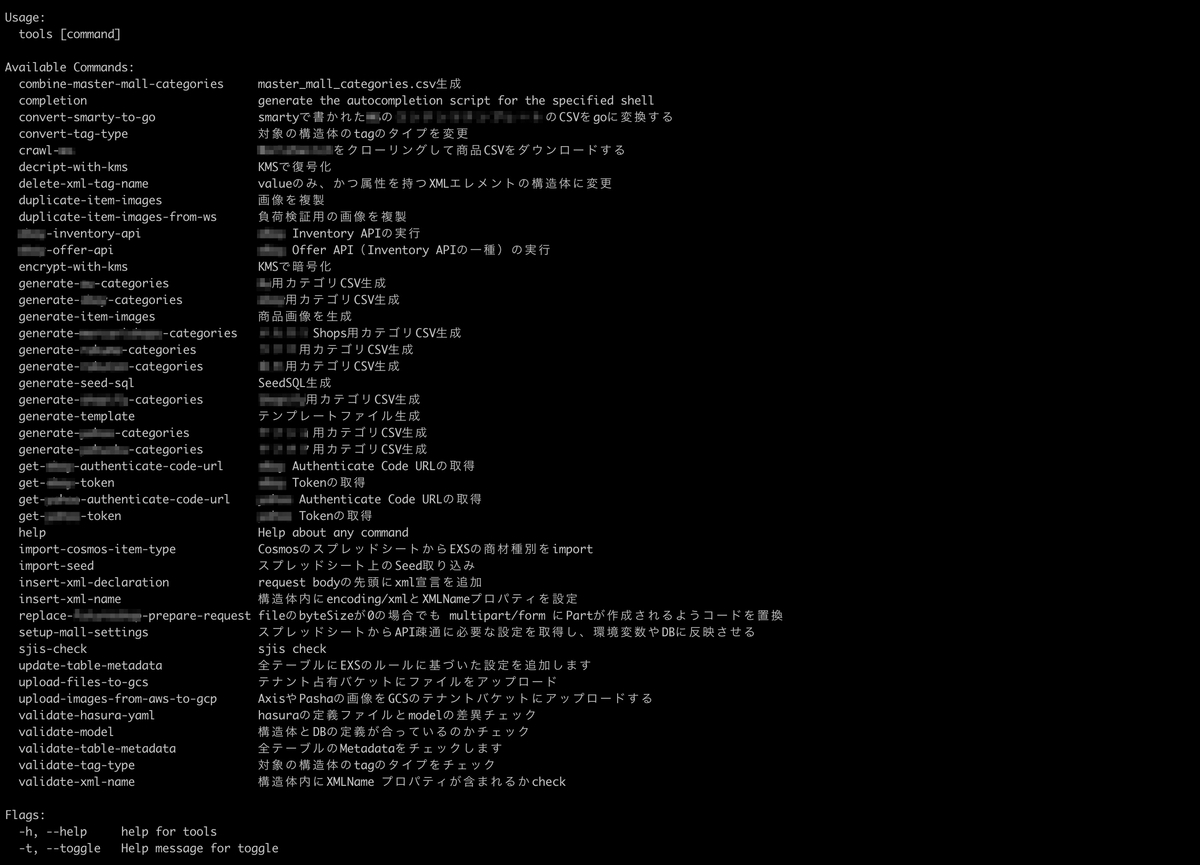
④ 依存性の排除
ローカルの開発環境は、オンボーディングの観点ではローカル以外の何にも依存しない状態で動作できることが理想的と考えていました。これによって、新しく参加したメンバーがアプリケーションを動作させるまでにかかる時間を短縮でき、より早く開発作業に入ることを目指しました。
近年はクラウド上のフルマネージドサービスをインフラアーキテクチャの中で採用することが多いと思います。私たちもGoogle Cloud上のさまざまなフルマネージドサービスを利用しています。また、前述したように外部サービスとのAPI連携も多く、さらにFTPサーバーを利用した外部サービスとのファイルのやり取りなども含まれています。もはや、Web3層構造をローカルで実現するだけではアプリケーションの検証がほぼできないほど複雑な連携を含むシステムになっていますが、それでも私たちはローカルで完結する動作環境を維持することにこだわりました。
クラウド上のフルマネージドサービス等には、それぞれエミュレータを利用してローカル環境での検証を可能にしています。
| 利用サービス(リソース) | イメージ・エミュレータ等 |
|---|---|
| Cloud Storage | fake-gcs-server |
| Cloud Tasks | cloud-tasks-emulator |
| Cloud Memorystore for Redis | redis(Docker Official Image) |
| Elasticsearch | elasticsearch |
| Kibana | kibana |
| FTPサーバー | docker-pure-ftpd |
| APIサーバー | wiremock |
また、外部APIはWireMockを利用してすべてのAPIをモックできるスタブサーバーを作成しました。 WireMockの利用については以下のブログにも詳細が書いてあります。
また、Seedingを利用してマスターデータと検証用のユーザーデータをDBに準備できるようにし、立ち上げ後に即座にアプリケーションが動作し、動作確認に使用するデータをチーム全員で共有できるようにしました。
最後に簡単に環境が立ち上がること!これが本当に一番大事だと思います。以前は環境のセットアップに丸1日以上かかることもありましたが、今のプロジェクトの環境ではコマンドを1つ実行するだけで環境が立ち上がるようになっています。
そのためにローカルマシンの環境への依存を排除することにこだわっています。Dockerのようなコンテナ技術の進歩によって、それがとてもやりやすくなっていますが、エミュレータやスタブサーバー、CLIの実行環境まで、Docker以外の依存はない状態を維持しています。
新しくチームに来たメンバーは最初に適当なバージョンのDocker Desktopをインストールしさえすれば、すぐに環境をセットアップでき、当日中には開発に着手できるようになります。長らくプロジェクトのREADMEにはRequirement: Docker以外が記載されていません。

成果

これは直近のチームの人数の増加と、PR作成数の変遷のグラフです。稼働人数の増加に比べてPR作成数のほうが増加割合が多く見えるかと思います。チーム内メンバーの感想としても、以前に比べて人数が増えた際のアウトプットの増加が感じやすくなっという話も出ています。。プロジェクトも佳境に差し掛かっており、メンバーが実力を早く発揮できることは本当に助かっています。
今後の展望としては、GitHub CopilotのようなAIベースのコーディング支援ツールをセットアップの中に組み込んで、既存コードの理解を早めるようなオンボーディング施策を試してみても面白いかなと思っていますので、機会があれば取り組んでいきたいです。
終わりに
いかがでしたでしょうか。今回はバイセルのバックエンドの開発環境でオンボーディングのために工夫したことをいくつか紹介しました。この記事が皆さんの開発の一助となれば幸いです。
最後に、バイセルではエンジニアを随時募集しております。興味のある方はぜひ以下の採用サイトをご覧ください。