

はじめに
こちらはバイセルテクノロジーズ Advent Calendar 2024の23日目の記事です。
昨日は千棒さんによる2024年情シスの業務改善とセキュリティ強化の成果を振り返るでした。
こんにちは。テクノロジー戦略本部 開発3部の今井です。
私は現在、顧客対応・SFA システム(以下、CRM)のバックエンド・インフラ領域の設計や開発に携わっています。
先日の10月31日に、システムリプレイスにおける複数DBアクセスの課題と解決策を執筆しました。
本記事ではその続きとして、システムリプレイスを進めるうえでのアプリケーション開発の課題感や対応方針についてご紹介します。
CRM の開発・運用状況
バイセルでは DX の取り組みのひとつとして、さらに多様な買取・販売チャネルに対応し、買取から販売まで一気通貫してデータを管理・活用する「バイセルリユースプラットフォーム Cosmos」(以下、Cosmos)の開発を進めています。
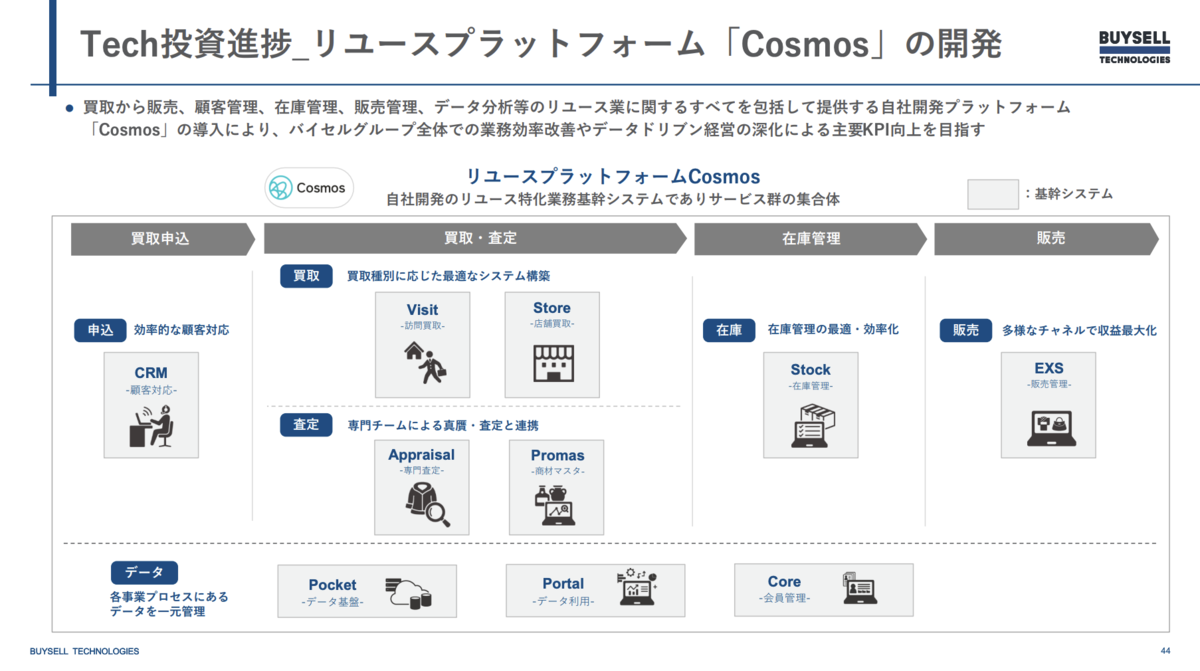
その中で私が携わっているプロジェクトでは、インサイドセールス部門で使用する CRM を開発しています。
主力事業である出張訪問買取の最初の入口となり、将来的にはマーケティング部やセールスコンプライアンス部等顧客対応のハブとなるシステムを目指しています。
また、バイセルでは既に顧客管理システムを運用していますが、様々な課題があり、Cosmos 内の各サービスへ段階的にリプレイスしていくことが決定しています。
その中で CRM は昨年から既存システムの顧客管理ドメインを担う形で開発を進めており、今回システムリプレイスの計画を立て始めました。
「システムリプレイスにおける複数DBアクセスの課題と解決策」の振り返り
先日書いた記事の内容を簡単におさらいします。
CRMのシステムリプレイスにおける計画としては、既存システムとCRMの両方を並行して開発・運用しながら、既存システムのAPIを徐々にCRMへ移行し、既存システムの顧客管理ドメインにあたるサービスを停止させるものです。
「既存システムのAPIをCRMに移行する」とは、既存システムのAPIと互換性のあるAPIをCRMで実装することを指しています。
したがって、CRM BEから既存システムの顧客管理DBへ直接アクセスする必要があります。
その過程で直面した、異なるGoogle Cloudプロジェクト間でのDB接続における課題と、IAM認証を用いた解決策についてご紹介しました。
Cloud RunからCloud SQL for PostgreSQL(以下、Cloud SQL)への接続において、VPCピアリングやPrivate Service Connectなど様々な方式を検討した結果、パブリック接続 + IAM認証による方式を採用しました。

こちらでインフラストラクチャの課題は解決しました。
一方で、互換性のあるAPIを開発するためには、既存システムのアーキテクチャや言語・フレームワークなどを踏まえた設計・開発が必要でした。
既存システムのアーキテクチャと技術スタック
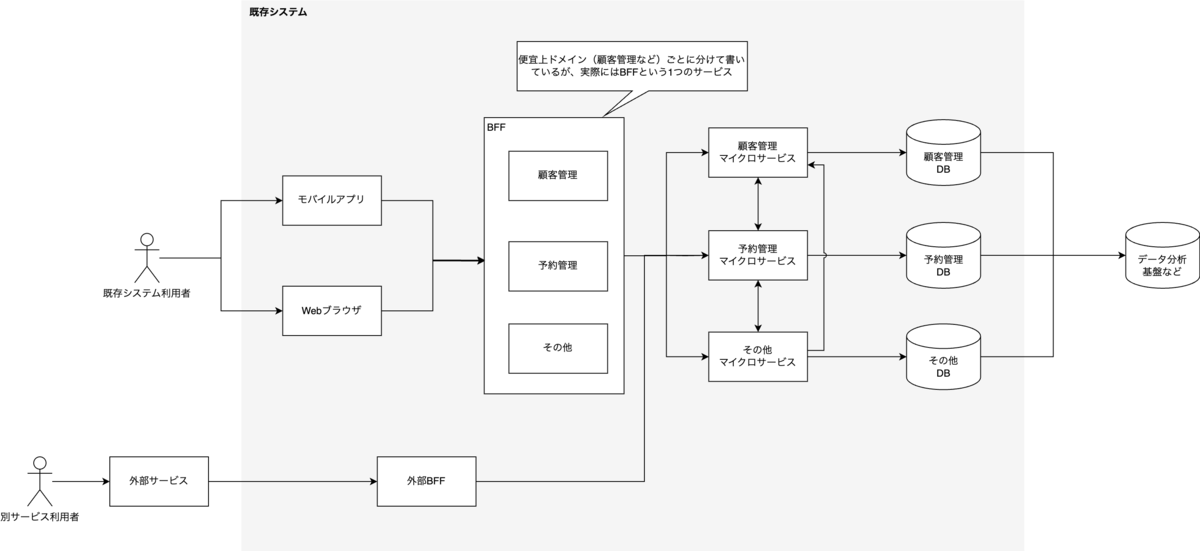
既存システムのアーキテクチャについて、まず全体像を説明します。
アーキテクチャ
基本構造
- BFFパターンを採用し、ドメインロジックを管理するマイクロサービス群を後方に配置
- 各マイクロサービスは独立したDBを保持(物理サーバーは共有)
- DBアクセスは、所属マイクロサービスからのみ許可
- マイクロサービス間の連携を許可し、複数サービスを跨いだ処理が可能
クライアントアクセス
- WebブラウザとiOSアプリが共通のWeb APIを利用
- 外部サービスからは専用のBFFを経由してアクセス
- 認証方式は内部・外部で区別
データ連携
- CDCを利用してデータ分析基盤と連携
- BigQuery上でレコードごとの更新履歴を管理
技術スタックの比較
続いて、以下は両システムの主要な技術スタックの比較です。
| 項目 | 既存システム | CRM |
|---|---|---|
| 言語 | Ruby | Go |
| フレームワーク | Ruby on Rails | ogen |
| ORM | Active Record | SQLBoiler |
| 実行基盤 | Google Kubernetes Engine | Cloud Run |
| DB | Cloud SQL for PostgreSQL (PostgreSQL 11) | AlloyDB for PostgreSQL (PostgreSQL 14) |
データの整合性における課題と対策
システムリプレイス期間中は、既存システムとCRMの両方からデータの登録・更新が行われるため、データ整合性の維持が最重要課題だと考えました。
具体的な対策を、予防と発見・復旧の2つの観点から説明します。
データ不整合を未然に防ぐための対策
実装時の注意点
データの整合性を維持するためには、既存システムの仕様を理解することが必要不可欠です。
そこで事前調査として、具体的には以下のプロセスで理解を深めていきました。
ソースコードレベルでの調査
- テーブル定義やカラムの制約条件
- モデル間の依存関係
- バリデーションルール
運用チームとの知見共有
- 明文化されていない業務ロジック
- 過去のトラブル事例
- 運用上の注意点
また、より技術的な観点では、言語仕様やフレームワークの特性を調査し、実装面で注意を払っています。
Ruby on Rails(以下、Rails)はフレームワークとして暗黙的に動作する処理が多く、Goではそれらを明示的に実装する必要があります。
型システムとエラーハンドリング
- Rubyの動的型付けに対し、Goは静的型付け
- RailsのActiveModel::Errorsに相当するエラーハンドリングの実装
- エラーの種類ごとに適切なエラー型の定義と伝播の制御
Null値の取り扱い
- 互換性を保ちつつも、Nullポインタ参照を避けるために値オブジェクトを活用
- database/sqlパッケージのNullString、NullTimeなどの適切な活用
- Nullチェックロジックの明示的な実装
データ取得パターンの違い
Model.findの404エラー相当の挙動の実装- Railsの関連データ取得(preload、eager_load)に相当する実装
- N+1問題を防ぐための明示的なJOINクエリの実装
モデルの振る舞いの実装
- Active Recordのcallbackに相当する前処理・後処理の実装
- バリデーションルールの明示的な定義
- トランザクション境界の明確な制御
このように、Railsの便利な機能を理解した上で、Goの特性を活かしつつ同等の機能を実装することで、既存システムとの互換性を保ちながら、堅牢性を両立させることを目指しました。
テスト設計のアプローチ
既存システムのAPIと同等の振る舞いをしているかどうかを担保するために、既存システムのAPIで実装されている単体テストや結合テストをCRMで開発するAPIでも可能な限り踏襲するよう設計しました。
これにより、APIのIN/OUTが同等であることを担保できると考えました。
データ不整合が発生した場合の対策
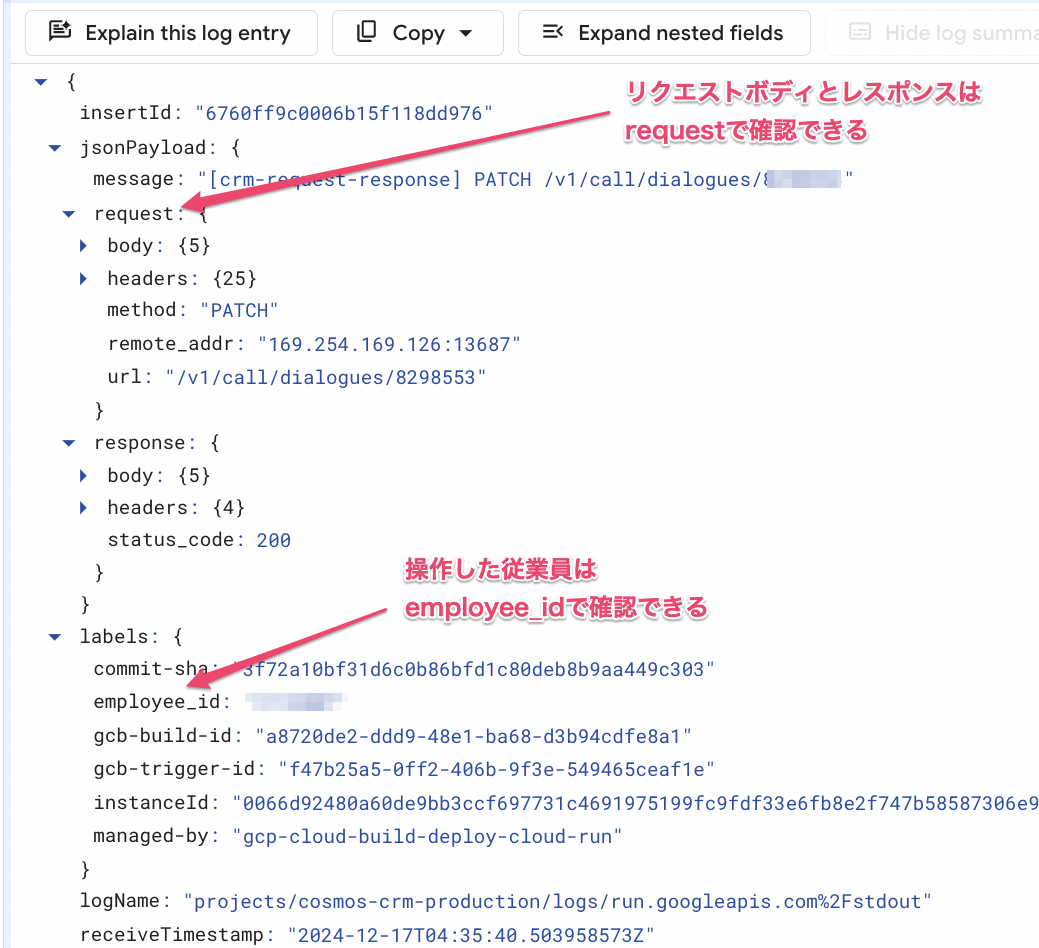
ログ設計の統一
障害が発生した場合、対象のデータを書き込んだAPIが、既存システムなのかCRMなのかのログを追える必要があります。
結果として、CRMでは既にその仕組みを整えており、既存システムでも問題なくログを追えるようになっていました。
具体的には、現状「いつ・どこで・誰が・何をしたか」をログに出力するようにしています。
この仕組みにより、ログからどのAPIでデータを書き込んだか追えるようになっています。
以下はCRMで出力しているログの例です。
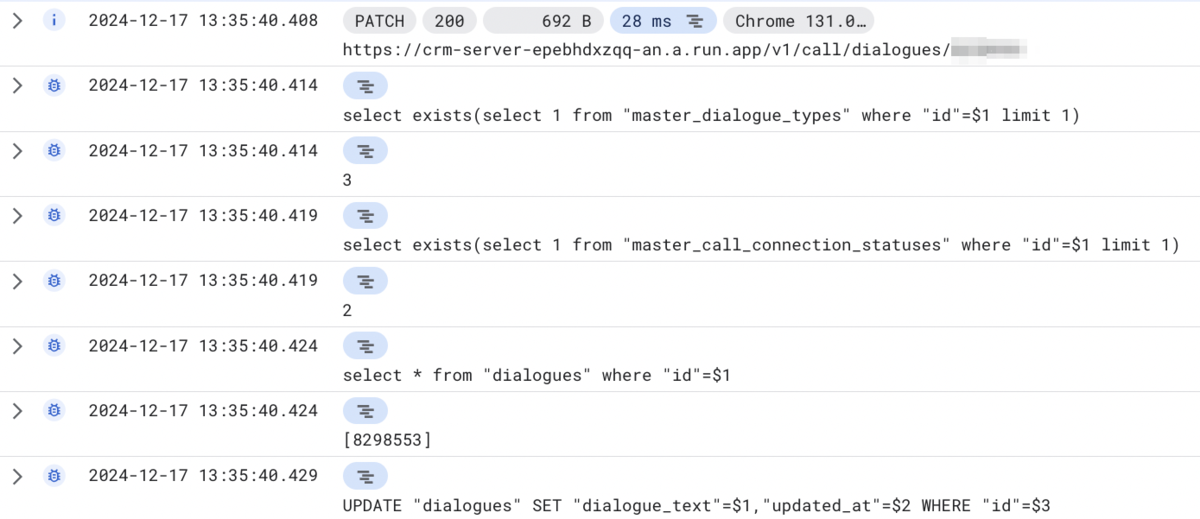
DBユーザーの分離
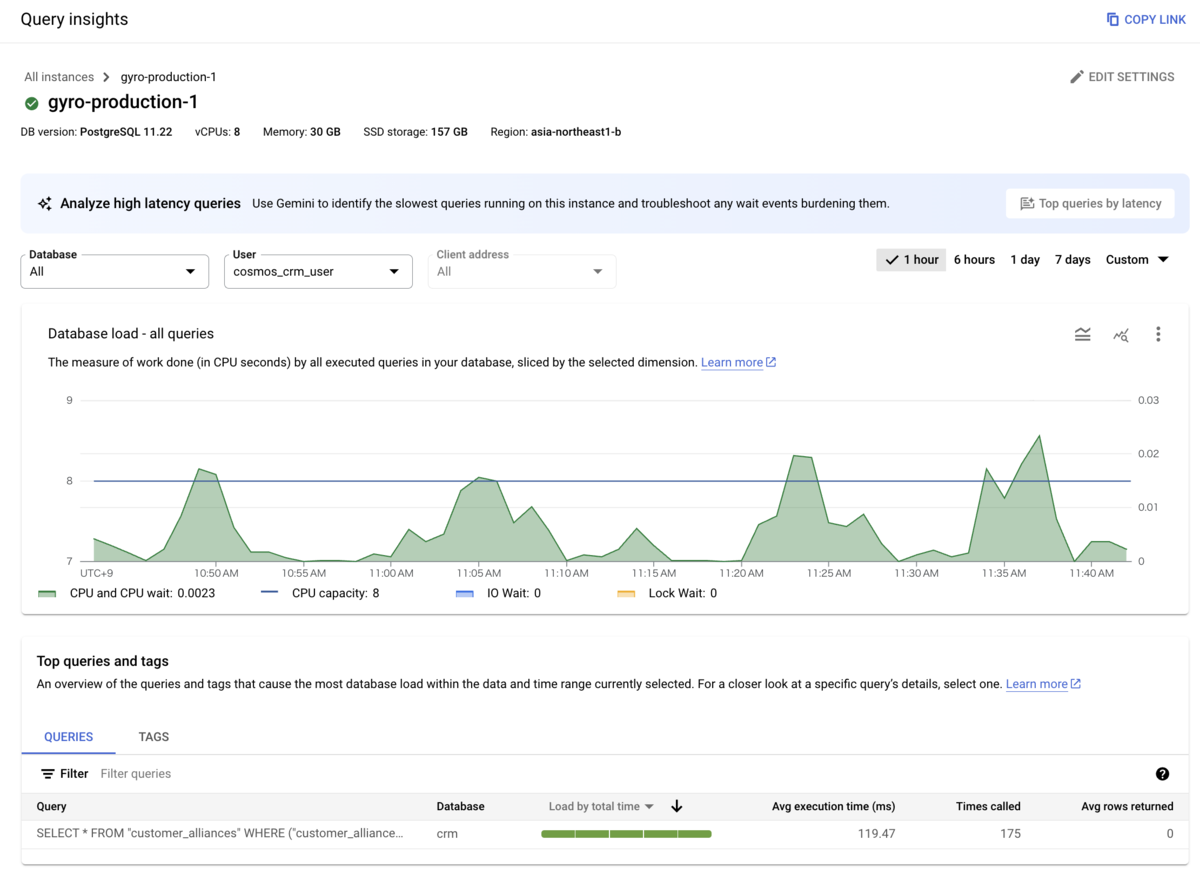
また、CRM専用のDBユーザー(cosmos_crm_user)を作成し、Query Insightsを活用することで、どのシステムからの更新なのかを明確に識別できるようにしました。
既存システムのDBではCloud SQLを採用しているため、Query Insightsを有効にすることで、ログからDBユーザーとSQLクエリの実行内容を把握することが可能です。
以下はQuery Insightsで出力しているログの例です。
見送った対策案
一方で、見送った対策案としては「どちらのアプリケーションから書き込まれたかのカラムを設ける」というものがありました。
この場合、DB上で管理できるので調査が容易になり、履歴上でも判別できるメリットがあります。
ただし、既存システムに改修が発生する、またCRMでも追加開発が必要になるデメリットがあります。
APIやSQLクエリのログなど各種ログが既存システムとCRM双方で追える状態であれば、この対応は必須では無く、スケジュールや開発工数などを加味して、最終的には見送ることとしました。
トランザクション管理や排他制御における課題と対策
システムリプレイスが完了するまで、同じDBのテーブルに対して既存システムとCRMそれぞれで登録・更新を行う処理があります。
この際、適切にトランザクションを実行しないとデータ不整合が発生してしまうリスクがあります。
また更新する際には、対象テーブルやレコードを同じ順で更新(行ロック)しないと、デッドロックが発生してしまうリスクがあります。
トランザクション管理における課題と対策
既存システムで採用されているRuby on RailsのActive Recordは、自動でトランザクションを実行してくれます。
一方で、CRM BEで採用しているSQLBoilerは、自動でトランザクションを実行していません。
そのため、トランザクションを実行する関数を定義し、登録・更新処理の前後でトランザクションを実行するようにしました。
※記載しているコードは実際のコードではありません。ご了承ください。
package repository import ( "context" "database/sql" "fmt" "log/slog" "github.com/volatiletech/sqlboiler/v4/boil" ) func DoTransaction(ctx context.Context, fn func(context.Context, *sql.Tx) error) (err error) { tx, err := boil.BeginTx(ctx, nil) if err != nil { return fmt.Errorf("failed to begin transaction: %w", err) } defer func() { if shouldRollback(err, recover()) { rollbackTx(ctx, tx) } }() if err := fn(ctx, tx); err != nil { return err } if err := tx.Commit(); err != nil { return fmt.Errorf("failed to commit transaction: %w", err) } return nil } // shouldRollback はロールバックが必要かどうかを判断します func shouldRollback(err error, recovered interface{}) bool { return err != nil || recovered != nil } // rollbackTx はトランザクションのロールバックを実行します func rollbackTx(ctx context.Context, tx *sql.Tx) { if err := tx.Rollback(); err != nil { slog.ErrorContext(ctx, fmt.Sprintf("failed to db rollback: %v", err)) } }
排他制御における課題と対策
既存システムのロジックを調査したところ、排他制御(楽観的ロック・悲観的ロックともに)をしているAPIもあれば無いAPIもあり、統一的なルールがありませんでした。
同じDBのテーブルを更新する複数のAPI全てで実行されていないと、排他制御をすることはできません。
そのためCRMで開発するAPIで排他制御を実行しても、既存システムのAPIになければ機能しないことになります。
なので、既存システムのAPIにも排他制御の仕組みを追加することを検討しましたが、APIの数がとても多く複雑な処理をしているものもあったため、スケジュールや開発工数を加味すると実現することは難しいと判断しました。
また、Active RecordとSQLBoilerでは、モデルの更新処理に関する仕様が異なります。
この違いにより、特に同時更新時に異なる結果となる可能性があることが分かりました。
Active RecordにはDirty Trackingという機能が実装されており、モデルの属性変更を追跡します。
これにより、実際に変更されたカラムのみをUPDATE文に含めることが可能です。
一方で、SQLBoilerではモデルの属性変更を追跡していないため、変更がないカラムでもUPDATE文に含まれます。
そのため並行して処理が実行された状況下では、更新結果に差異が発生します。
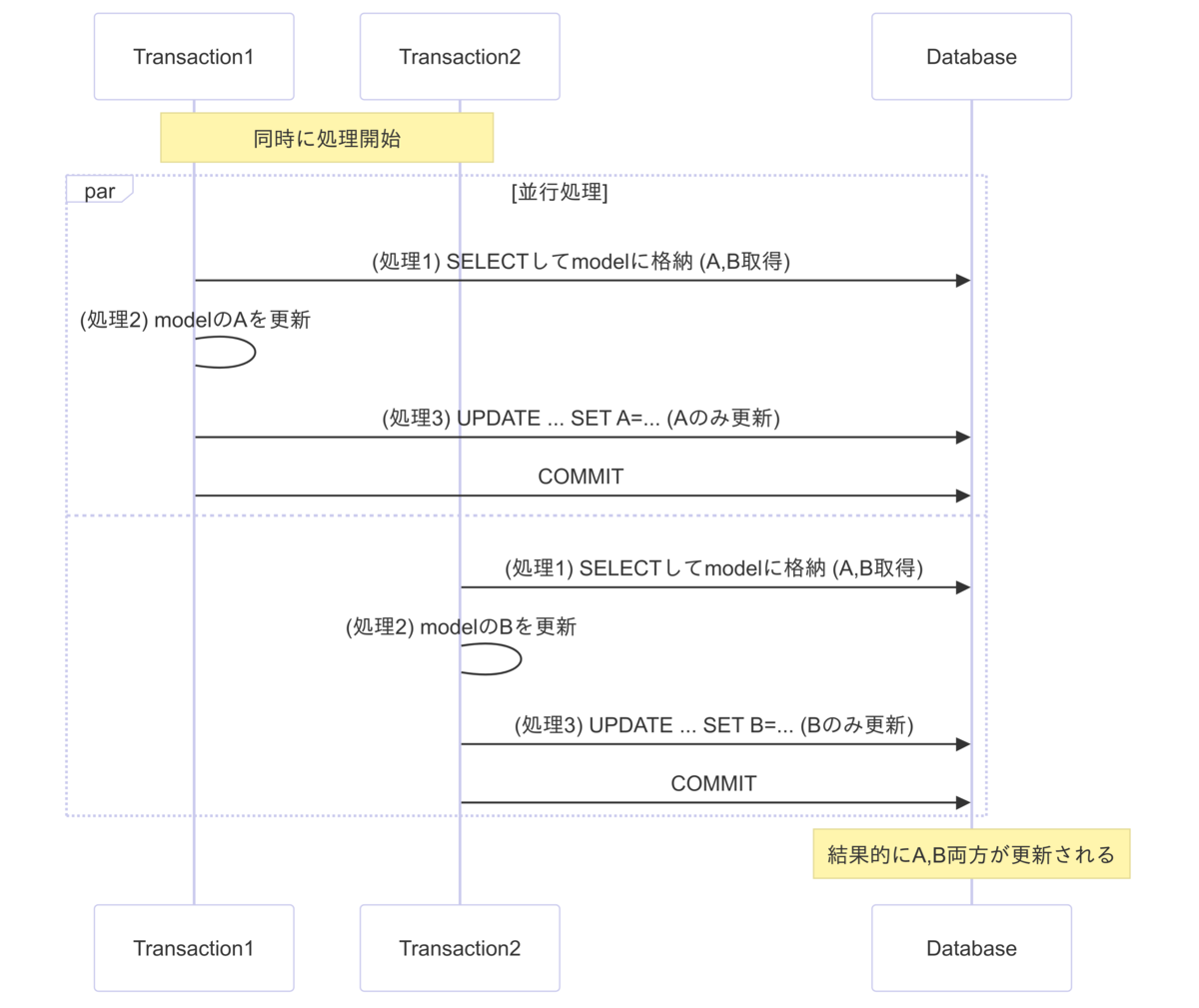
Active Recordの場合
更新したカラムのみUPDATE文に含まれるため、最終的にはカラムAとカラムBが更新されたデータになります。
SQLBoilerの場合
カラムAの内容は処理1で取得した状態の値で上書きされるので、最終的にカラムBだけが更新されたデータになります。
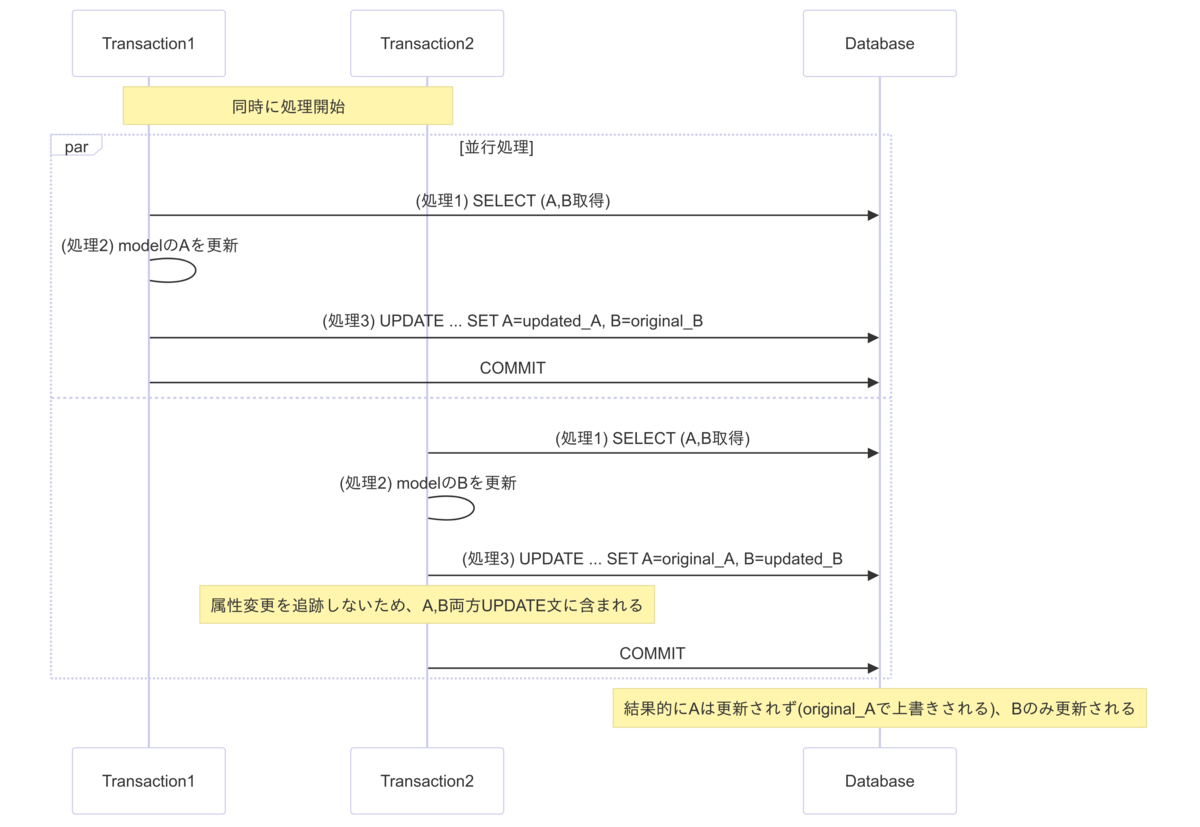
排他制御が実行できないAPIに関しては、SQLBoilerの処理を拡張し、Active Recordの更新処理と同等の処理にする必要があると判断しました。
そこで具体的には、以下の2点を実装しました。
- 同値の値だった場合、更新しない。
- 変更がない場合、UPDATE文を発行しない。
※記載しているコードは実際のコードではありません。ご了承ください。
package boilerutil import ( "context" "reflect" "strings" "time" "unicode" "github.com/cockroachdb/errors" "github.com/volatiletech/sqlboiler/v4/boil" ) // Modelは、SQLBoilerのModelインターフェースを満たす必要がある構造体。 // Updateメソッドは、指定されたカラムのみUPDATEを発行できる。 type Model interface { Update(context.Context, boil.ContextExecutor, boil.Columns) (int64, error) } // Updateは、beforeとafterモデルを比較し、変更があったカラムのみUPDATEを実行する。 func Update(ctx context.Context, db boil.ContextExecutor, before, after Model) (int64, error) { changedCols := Compare(before, after) if len(changedCols.Cols) == 0 { // 変更がない場合はUPDATEをスキップ return 0, nil } // UpdatedAtがある場合は現在時刻をセットする setUpdatedAt(after) // 部分的なUPDATEを実行 rowsAffected, err := after.Update(ctx, db, changedCols) if err != nil { return 0, errors.Errorf("failed to update model: %w", err) } return rowsAffected, nil } // Compareメソッドは、beforeModelとafterModelを比較し、変更があったカラムのみを抽出する。 // 返り値はboil.Whitelist(changedColumns...)で、指定カラムのみUPDATE文に適用可能。 func Compare(beforeModel, afterModel Model) boil.Columns { reflectBefore := reflect.ValueOf(beforeModel).Elem() reflectAfter := reflect.ValueOf(afterModel).Elem() var changedColumns []string for i := 0; i < reflectBefore.NumField(); i++ { fieldBefore := reflectBefore.Type().Field(i) fieldAfter := reflectAfter.Type().Field(i) // 特定フィールドの除外例(R, L, CreatedAt, UpdatedAtなど) if fieldBefore.Name == "R" || fieldBefore.Name == "L" || fieldBefore.Name == "CreatedAt" || fieldBefore.Name == "UpdatedAt" { continue } beforeVal := reflectBefore.Field(i) afterVal := reflectAfter.Field(i) if isChanged(beforeVal, afterVal) { changedColumns = append(changedColumns, ToSnakeCase(fieldBefore.Name)) } } // 変更があればupdated_atカラムもセット(必要に応じて削除可能) if len(changedColumns) > 0 { changedColumns = append(changedColumns, "updated_at") } return boil.Whitelist(changedColumns...) } // isChangedメソッドは、beforeValとafterValが変更されたか判定する処理の例 func isChanged(beforeVal, afterVal reflect.Value) bool { // nullパッケージやtime.Timeなど特別な型に応じた比較ロジックもここで記述可能 return !reflect.DeepEqual(beforeVal.Interface(), afterVal.Interface()) } // setUpdatedAtメソッドは、UpdatedAtフィールドを持つモデルがある場合、現在時刻を設定する例 func setUpdatedAt(m Model) { reflectModel := reflect.ValueOf(m).Elem() if field := reflectModel.FieldByName("UpdatedAt"); field.IsValid() && field.CanSet() { field.Set(reflect.ValueOf(time.Now())) } } // ToSnakeCaseはフィールド名をスネークケースに変換する例 func ToSnakeCase(s string) string { b := &strings.Builder{} for i, r := range s { if i == 0 { b.WriteRune(unicode.ToLower(r)) continue } if unicode.IsUpper(r) { b.WriteRune('_') b.WriteRune(unicode.ToLower(r)) continue } b.WriteRune(r) } return b.String() }
この処理を更新処理に適用することで、同時更新時にも既存システムと同等の挙動になることを担保できました。
先日、この処理を適用したAPIをリリースしましたが、現状問題なく動作しています。
最後に
今回ご紹介した解決策により、以下の課題に対応できました。
- データ整合性の維持
- 不整合発生時の原因特定
- 更新処理の一貫性確保
他にも多くの問題がありますが、今回はCRM BEの設計・開発において特に重要度の高いデータの整合性に関する観点をご紹介しました。
現在も引き続きCRM BEの開発を進めており、今後の計画ではより難易度の高い設計・開発が必要なAPIもあります。
その際に得た知見は、またどこかでご紹介できればと思います。
バイセルではエンジニアを募集しています。少しでも気になった方はぜひご応募お待ちしています。
明日のバイセルテクノロジーズ Advent Calendar 2024は馬場さんの「生成AIのOCRを用いた切手集計業務の改善」です。そちらもぜひ併せて読んでみてください。