
はじめに
テクノロジー戦略本部の尾沼です。
私が現在携わっているプロジェクトでは、HasuraとGo言語を使ってバックエンド部分を開発しています。マイグレーションやデータのCRUDは全てHasura経由でPostgreSQLに対して実行しており、マスタデータのUPSERTもHasuraを経由して実施しています。
この度、マスタデータの管理方法をスプレッドシートに移行させたのでその際に行ったことを紹介したいと思います。
課題
従来のマスタデータ管理方法では以下のような問題がありました。
カラム数が多いレコードを、手動でデータ編集をするのに非常に手間がかかるようになっていた。
エンジニアしかマスタデータを読んだり更新したりできない状況であった。
レコード数やデータ量が多い場合、それらを追加するSQL上で値がどのカラムに属するかを判別することが難しかった。
スプレッドシートで管理する方式にすることで以下のようなメリットを享受し、上記を解決できると考え、改修を行いました。
スプレッドシート関数を利用してデータの追加/加工が行える。
非エンジニアメンバー含め、複数人で同時に作業ができる。
レコード数やデータ量が多くなっても値がどのカラムに属するかを容易に判別できる。
改修概要
前提として、弊プロジェクトではhasura cliを用いてSQLファイルをHasura経由でPostgreSQLに対して実行しています。
今回の改修によってマスタデータを追加/更新する際の方法が以下のように変わりました。
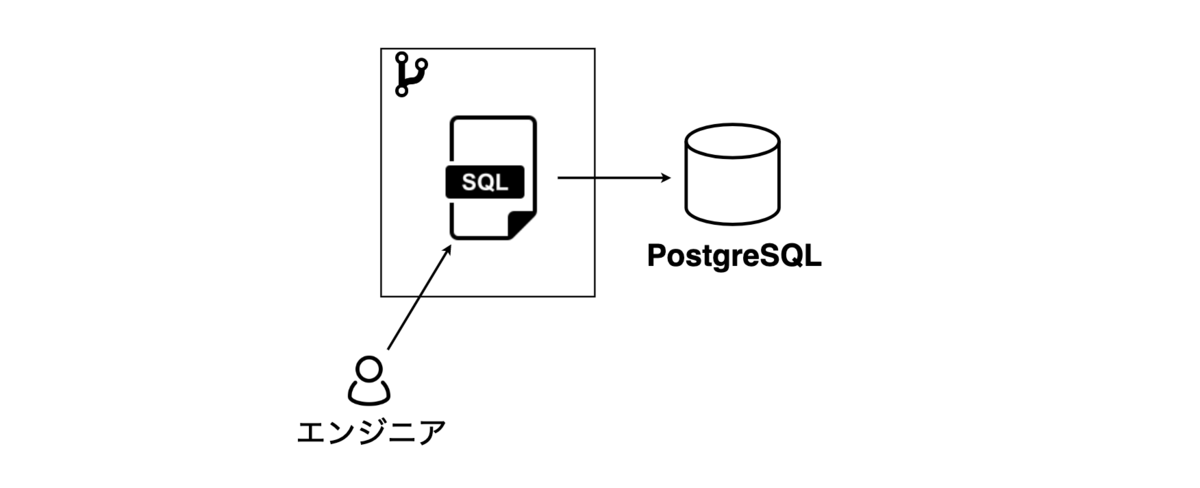
Before
開発者が直接SQLファイルを作成/更新する
- バージョン管理はSQLをGit管理することで実現する
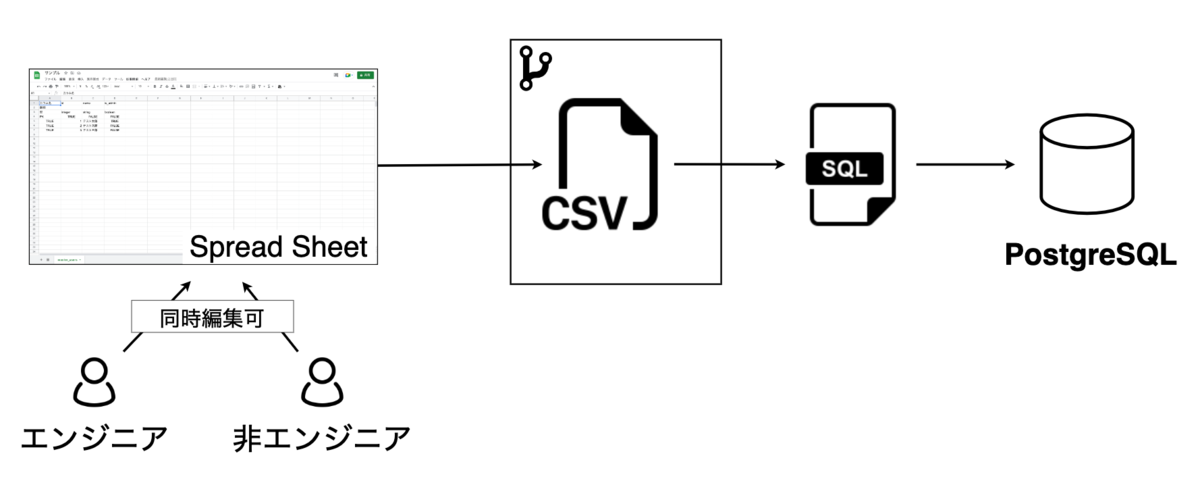
After
スプレッドシートで追加更新を行い、アプリケーション側に用意したコマンドで取り込んで反映するだけにする。
同時編集が可能
エンジニアと非エンジニアが編集可能
バージョン管理はCSVをGit管理することで実現する
- Github上でCSVのほうがSQLよりも見やすいため
工夫した点
今回特に工夫した点を紹介したいと思います。
スプレッドシートで細かい設定をできるようにした
ユーザーアカウントでスプレッドシートへのアクセスを認証するようにした
シートの情報からCSVファイルを生成するようにした
CSVファイルからUpsertのSQLファイルを出力するようにした
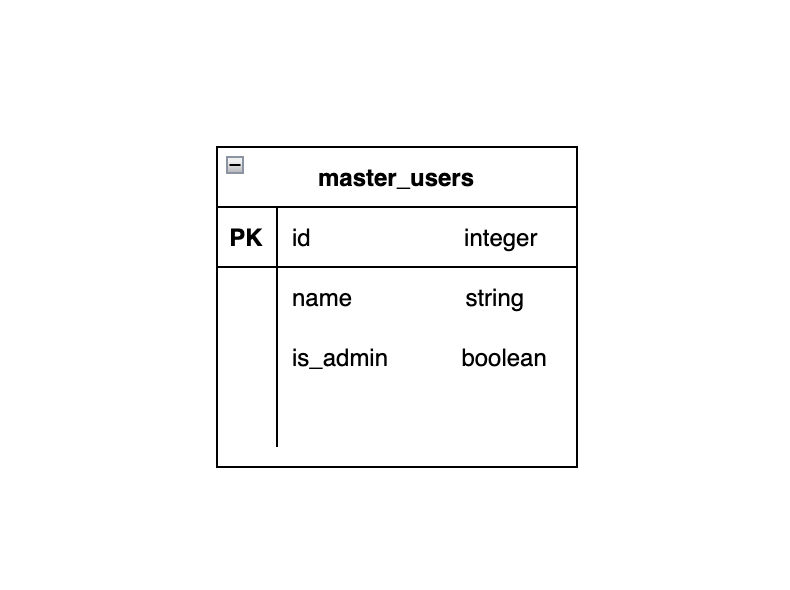
以下のような構造のmaster_usersテーブルにデータを投入する例を通じて紹介します。
本記事では説明の都合上、コード中省略している箇所がございます。動作するサンプルコードは以下にアップロードしています。
スプレッドシートで細かい設定をできるようにした
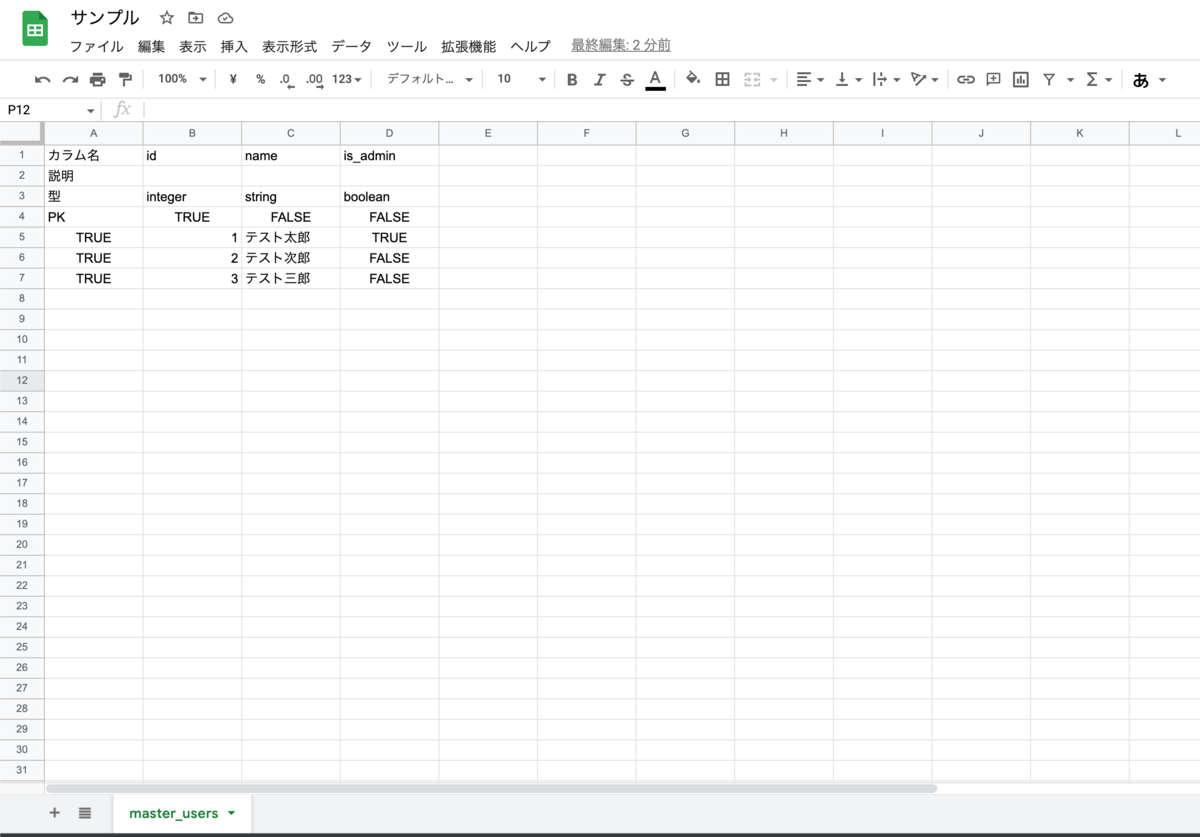
スプレッドシートを用意します。工夫した点は以下です。
シート名をテーブル名にすることで、どのシートがどのテーブルに対するものかを判別できるようにしました。
2行目に各カラムの説明を入れられるようにしました。
最終的にSQLに変換するにあたって、型を自由に設定できるようにしたいため3行目に各カラムの型を設定できるようにしました。
- 今回の例ではinteger, boolean, stringに対応
UpsertのSQLにてON CONFLICT句の条件にプライマリキーを指定しています。そのため、どのカラムがプライマリキーか判るように4行目に設定できるようにしました。
SQLに含ませたいデータを指定できるようにしました。
含ませたいデータ → 1列目をTrue
含ませたくないデータ → 1列目をFalse
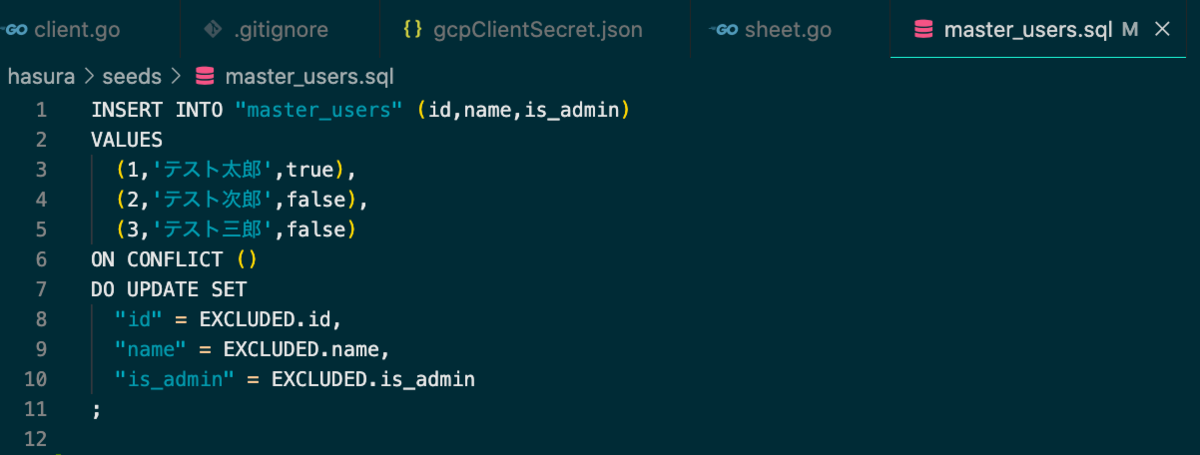
最終的には上のスプレッドシートから以下のようなSQLが出力されます。
ユーザーアカウントでスプレッドシートへのアクセスを認証するようにした
サービスアカウントではなくユーザーアカウントで認証することで、権限の管理をユーザー単位で行えるようにしました。
まず、Goの処理の中でスプレッドシートにアクセスしてデータを取得するために、GoのSheets APIクライアントを利用します。
事前準備として、GCPのプロジェクトを作成してGoogle Sheets APIを有効にしておきます。

今回はOAuth2.0クライアント認証でGCPにアクセスします。クライアントIDを作成し、JSONのキーをダウンロードします。

以下のようなJSONキーがダウンロードできると思うので、Goプロジェクト内に配置しておきます。
{
"installed":
{
"client_id":"xxxxxxxxxxxxxxxxxx",
"project_id":"xxxxxxxxxxxxxxxxxxx",
"auth_uri":"https://accounts.google.com/o/oauth2/auth",
"token_uri":"https://oauth2.googleapis.com/token",
"auth_provider_x509_cert_url":"https://www.googleapis.com/oauth2/v1/certs",
"client_secret":"xxxxxxxxxxxxx",
"redirect_uris":["urn:ietf:wg:oauth:2.0:oob","http://localhost"]
}
}
続いて、スプレッドシートへアクセスするために、ユーザー権限で認証を行うhttp clientを作成します。
まず、以下のようにhttp clientのコンストラクタを作成します。OAuth2.0クライアントの認証キーから接続先GCPプロジェクトの情報を読み込み、スプレッドシートのRead権限の利用が許可されるように設定します。
import (
"context"
"net/http"
"os"
"golang.org/x/oauth2/google"
)
func NewClient(ctx context.Context) (*http.Client, error) {
// gcpからダウンロードしたJSON keyのパスを指定する
const gcsAuthJSONFilePath = "/go/src/google/gcpClientSecret.json"
b, err := os.ReadFile(gcsAuthJSONFilePath)
if err != nil {
return nil, err
}
config, err := google.ConfigFromJSON(b, "https://www.googleapis.com/auth/spreadsheets.readonly")
if err != nil {
return nil, err
}
token, err := getTokenFromWeb(config) // 後で定義します
if err != nil {
return nil, err
}
client := config.Client(context.Background(), token)
if err != nil {
return nil, err
}
return client, nil
}
続いて、認証コードを標準入力で受け取ってトークンに変換して返す getTokenFromWeb 関数を定義します。 以下記事を参考にしました。
import (
// 省略
"golang.org/x/oauth2" // 追加
)
// 省略
func getTokenFromWeb(config *oauth2.Config) (*oauth2.Token, error) {
authURL := config.AuthCodeURL("state-token", oauth2.AccessTypeOffline)
fmt.Printf("\nブラウザで以下のURLを開いてauthentication codeを取得してください: \n\n%v\n\n", authURL)
var authCode string
fmt.Print("authorization code: ")
if _, err := fmt.Scan(&authCode); err != nil {
return nil, err
}
token, err := config.Exchange(context.TODO(), authCode)
if err != nil {
return nil, err
}
return token, nil
}
シートの情報からCSVファイルを生成するようにした
シートの情報をCSVとしてアウトプットします。
シートのデータの中にあるメタデータを元に、CSVに出力する情報の制御や変換を行うカスタムロジックを挟みます。
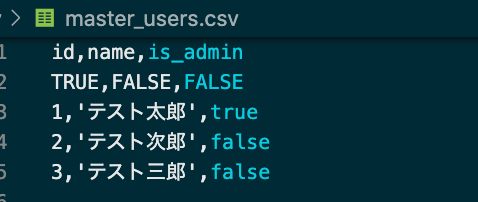
アウトプットするCSVは、サンプルでは以下のような形になる想定です。
1列目はカラム名
2列目はプライマリキーであるかどうか
3列目以降は各レコード(値はスプレッドシートで指定したカラム型に合わせて変換されている)
まず、CSVの値を出力するgenerateCSVValue関数を定義します。スプレッドシートの3行目に定義したカラムタイプで条件分岐をし、初期値などを設定できるようにしました。値が入っていた場合は初期値ではなくその値を返すようにしました。
import (
// 省略
"strconv" // 追加
)
func generateCSVValue(dataType string, v string) string {
var result string
switch dataType {
case "integer":
num, err := strconv.Atoi(v)
if err != nil || v == "" {
// integerにできない値がvalueに入っていたら0で返す
result = "{{ 0 }}"
} else {
result = fmt.Sprintf("{{ %v }}", num)
}
case "string":
if v == "" {
result = "{{ '' }}"
} else {
result = fmt.Sprintf("{{ '%s' }}", v)
}
case "boolean":
val, err := strconv.ParseBool(v)
if err != nil || v == "" {
// 変換できなかった時はfalseにする
result = "{{ false }}"
} else {
result = fmt.Sprintf("{{ %v }}", val)
}
}
return result
}
続いて、Goのsheetsパッケージが提供するSheet 構造体を受け取ってCSVを書き出すSheetToCSV関数を定義します。先ほど定義したgenerateCSVValueを利用します。
この処理の中で、出力する行の取捨やCSVに書き込む値の生成なども行っています。
import (
// 省略
"errors" // 追加
)
func SheetToCSV(s *gsheets.Sheet, csvOutputDir string) error {
fileName := s.Properties.Title // シート名 = ファイル名
// headerの名前を取得
var columnNames []string
const headerRowIndex = 0
for i, value := range s.Data[0].RowData[headerRowIndex].Values {
if i == 0 {
continue
}
columnNames = append(columnNames, value.FormattedValue)
}
records = append(records, columnNames)
// column型を取得
var columnTypes []string
const columnTypeRowIndex = 2
for i, columnType := range s.Data[0].RowData[columnTypeRowIndex].Values {
if i == 0 {
continue
}
columnTypes = append(columnTypes, columnType.FormattedValue)
}
if len(columnNames) != len(columnTypes) {
return errors.New("ヘッダーかカラムタイプの長さが一致しません")
}
// pkの設定
var pks []string
const pkRowIndex = 3
for i, columnType := range s.Data[0].RowData[pkRowIndex].Values {
if i == 0 {
continue
}
pks = append(pks, columnType.FormattedValue)
}
records = append(records, pks)
// レコードの差し替え
// レコードが入っているのは4行目以降
const dataBeginRowIndex = 4
for _, row := range s.Data[0].RowData[dataBeginRowIndex:] {
if len(row.Values) == 0 {
continue
}
const dataBeginColumnIndex = 1
// 先頭がfalseの行はCSV出力しない
if len(row.Values) > 0 && row.Values[dataBeginColumnIndex-1].FormattedValue != "TRUE" {
continue
}
var record []string
values := row.Values[dataBeginColumnIndex:]
for i, value := range values {
// 改行あるとCSVが壊れるので余計な改行コードを削除する(任意に文字列データに改行入れたいときはエスケープ文字構文に対応させる)
rowValue := strings.Replace(value.FormattedValue, "\n", "", -1)
v := generateCSVValue(columnTypes[i], rowValue)
// {{ hoge }} のマスタッシュ部分だけ削除
v = strings.TrimPrefix(v, "{{ ")
v = strings.TrimSuffix(v, " }}")
record = append(record, v)
}
records = append(records, record)
}
fileFullPath := fmt.Sprintf("%s%s", csvOutputDir, fileName)
if err := writeCSV(fileFullPath, records); err != nil {
return err
}
return nil
}
CSVファイルからUpsertのSQLファイルを出力するようにした
UpsertのSQLの生成はGo標準テンプレートエンジンのtext/template を用いて行うようにしました。
text/templateは文字列の雛形に餌となるデータを渡して新しい文字列を生成することができます。
これを利用してCSVからUpsertのSQLファイルを作成する実装をします。
まずUPSERTのSQLの雛形を用意します。TableNameやColumnNamesは構造体のフィールド名になります。
INSERT INTO "{{ .TableName }}" ({{ .ColumnNames }})
VALUES
{{ .Values }}
ON CONFLICT ({{ .Pk }})
DO UPDATE SET
{{ .UpdateSetting }}
;
続いてUPSERTのSQLの置換に使うUpsertContentDataという構造体とコンストラクタを定義します。
type UpsertContentData struct {
TableName string
ColumnNames string
Values string
Pk string
UpdateSetting string
contentsTemplate string
}
func NewUpsertContentData() *UpsertContentData {
// upsert句のテンプレ
contentsTemplate := `INSERT INTO "{{ .TableName }}" ({{ .ColumnNames }})
VALUES
{{ .Values }}
ON CONFLICT ({{ .Pk }})
DO UPDATE SET
{{ .UpdateSetting }}
;
`
return &UpsertContentData{
contentsTemplate: contentsTemplate,
}
}
UpsertContentData構造体の各フィールドにCSVから得たデータを入れていく処理をRegisterContentMapメソッドとして書きます。
import (
// 省略
"fmt" // 追加
)
func (c *UpsertContentData) RegisterContentMap(tableName string, records [][]string) {
// ヘッダーの置き換え 1行目はヘッダーのはず
columnNames := strings.Join(records[0], ",")
var values []string
for i, record := range records {
// ヘッダーはスキップ
if i < 2 {
continue
}
var texts []string
for _, v := range record {
if v == "" {
texts = append(texts, "null")
} else {
texts = append(texts, v)
}
}
var splitToken string
if i == len(records)-1 {
splitToken = ""
} else {
splitToken = ","
}
values = append(values, fmt.Sprintf(" (%s)%s", strings.Join(texts, ","), splitToken))
}
var updateSetting []string
for i, v := range records[0] {
var splitToken string
if i == len(records[0])-1 {
splitToken = ""
} else {
splitToken = ","
}
updateSetting = append(updateSetting, fmt.Sprintf(" %q = EXCLUDED.%s%s", v, v, splitToken))
}
var pkColumns []string
for i, columnName := range records[0] {
if records[2][i] == "TRUE" && columnName != "" {
pkColumns = append(pkColumns, columnName)
}
}
c.TableName = tableName
c.ColumnNames = columnNames
c.Values = strings.Join(values, "\n")
c.Pk = strings.Join(pkColumns, ",")
c.UpdateSetting = strings.Join(updateSetting, "\n")
}
以下のように、CSVから読み取ってきたデータを置換してファイルに書き込むことで、SQLファイルを生成することができます。
import (
// 省略
"bytes"
"text/template"
)
func CSVToUpsertSQL(csvPath string, outputDir string) error {
records, err := readCSV(csvPath)
if err != nil {
return err
}
// 省略
data.RegisterContentMap(tableName, records)
tmpl, err := template.New("tmpl").Parse(data.contentsTemplate)
if err != nil {
return err
}
var doc bytes.Buffer
if err = tmpl.Execute(&doc, data); err != nil { // 置換を実行
return err
}
str := doc.String()
if _, err := fmt.Fprintf(f, "%v", str); err != nil {
return err
}
return nil
}
まとめ
弊プロジェクトの全てのマスタデータ管理をスプレッドシートに移行させたことで、当初の想定メリットであった、
スプレッドシート関数を利用してデータの追加/加工が行える。
非エンジニアメンバー含め、複数人で同時に作業ができる。
レコード数やデータ量が多くなっても値がどのカラムに属するかを容易に判別できる。
これらに関してかなり恩恵を享受できるようになりました。
どうしてもカラム数やレコード数が増えると、SQLを目視で追ったり改修することにミスが生じやすくなってしまうので、見やすいスプレッドシートだけを編集してあとはコマンドを叩くだけにした今回の改修は実施して良かったなと感じています。
最後に、Buysell Technologiesではエンジニアを募集しています。興味がある方はぜひご応募ください!