

はじめに
こちらは バイセルテクノロジーズ Advent Calendar 2024 の6日目の記事です。 昨日は小島さんによる長期的に活躍する!オンボーディング期間の重要性とやるべきことについてでした。
こんにちは、テクノロジー戦略本部 CTO室 BuySell Research の小貫です。私は 2024 年の 4 月に中途採用で入社し、Research Scientist として当社内にある課題の解決に向けた研究業務に従事しています。
今回は、直近の研究課題である「電話などにおけるセールストークの定量評価手法の研究」に取り組んでいる際に直面した問題について紹介します。
セールストークの定量評価では、音声データとそれの文字起こしデータを用いた解析を今のところ想定します。文字起こしには Whisper を用いたのですが、何も考えずに大量の音声データを Whisper で処理したら、文字起こし精度が劣化する問題に直面しました。本記事では、その原因と対処法について紹介します。
セールストークの定量分析
セールストークの評価方法
当社では、電話にて当社取扱の商材の訪問査定の予約受付等を実施しています。訪問査定の予約数の向上が実際の売上に繋がるため、この段階でのお客様対応の質の向上は非常に重要です。お客様対応の質の向上のために、現場では実際のセールストークの評価・フィードバックを実施しています。
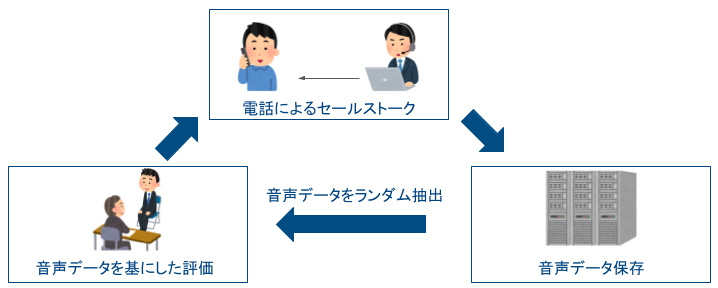
上図のように、実際のお客様対応中の音声データ *1 を用いて、セールス担当者の上長などがセールストークの評価を実施します。そして、評価を受けたセールス担当者はそれを参考にお客様対応方法を改善し、現場にて実践します。この一連のサイクルによって、日々、セールストークは磨かれています。
この評価方法の問題点を挙げるならば、全音声データを用いた評価ができないことです。幸いなことに、当社はお客様対応する機会を多くいただけており、膨大な量の音声データを日々蓄積できています。
そのため、評価の際には、セールス担当者の音声データの中からいくつかランダム抽出して評価することが現実的です。しかし、ランダム抽出した音声データが、たまたま良い・悪いセールストークに偏った場合には正当な評価ができず、教育機会の損失になる可能性があります。

その問題を解決するために、全ての音声データを統一された基準( AI )で定量評価し、それを用いてセールス担当者の評価・フィードバックを実施することが望まれています。
セールストーク定量化に向けて必要な処理
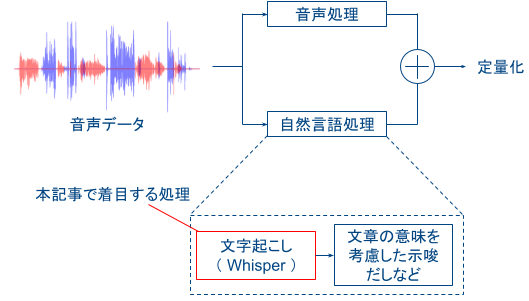
評価の定量化に向けて、上図のように音声処理・自然言語処理での結果を統合して評価することを想定しています。これらの処理では以下のような解析を想定しています。
- 音声処理:発話者の声のトーンなどを解析して声自体の評価
- 自然言語処理:文章の意味などを考慮して会話の評価
上記の 2 つの評価を統合することで、セールストークの評価の定量化を目指しています。本記事においては、この処理の中の一部分である「文字起こし」に着目します。
本記事では、文字起こしは、人の発話内容を PC 上に文字データとして表現することとします。これは、人手で実施も可能ですが、データが多くなるとそれが難しくなることは直感的に分かると思います。
当社の状況としては、業務上 1 ヶ月で 6,000 以上の音声データが蓄積されており、音声データの大部分は、1 データあたり 3~10 分ほどです。この場合、全ての音声データを処理するには、文字起こしを実施するスタッフを大人数雇用して対応する必要があります。
多くのデータを処理するために、本研究では、Whisper による文字起こしの自動化を選択しました *2 。
Whisper による文字起こしの自動化
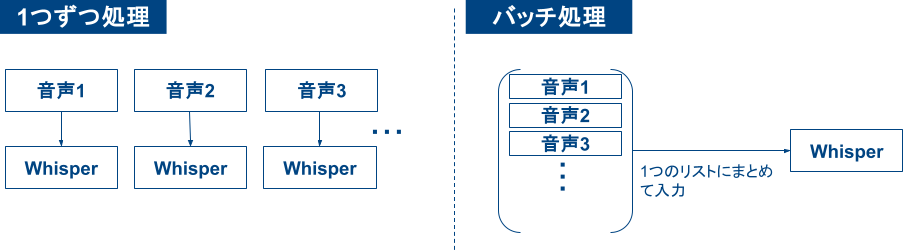
上図のように、Whisper を用いて文字起こしをする際には以下の 2 パターンの方法があります。
- 音声データを 1 つずつ文字起こしする
- 複数個の音声データを並列で文字起こし(バッチ処理)
前者の方法では、1 つ前の文字起こしタスクが終了するまで、次の文字起こしタスクが開始できません *3 。この待機時間によって、全ての音声データを処理するまでの計算時間が長くなります。
他方、バッチ処理の場合は、複数個のデータをまとめて処理が可能なので、前者の方法よりも少ない計算時間で全ての音声データの文字起こし結果を得ることが期待できます。
バッチ処理の問題
しかし、バッチ処理を何も考えずに実行すると文字起こし性能が劣化する問題に直面しました。例えば、以下のようにバッチ処理を行う場合を考えます。
device = "cpu" torch_dtype = torch.float32 model_id = "openai/whisper-large-v3" batch_size = 2 model = AutoModelForSpeechSeq2Seq.from_pretrained( model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True, ) model.to(device) processor = AutoProcessor.from_pretrained(model_id) pipe = pipeline( "automatic-speech-recognition", model=model, tokenizer=processor.tokenizer, feature_extractor=processor.feature_extractor, torch_dtype=torch_dtype, device=device, ) transcript = pipe( inputs=waveform_list, generate_kwargs={"language": "japanese", "num_beams": 2}, return_timestamps=False, batch_size=batch_size, ) print(transcript)
上記の waveform_list に、こちらの「土谷麻貴様」の音声の通常の喋り方における「tsuchiya_normal_001.wav」「tsuchiya_normal_002.wav」の 2 つの音声データを格納し、それを Whisper でバッチ処理を行いました。その結果が以下です。
{'text': 'また同時のように、下手な上手をはがしようがないような調理をさらに受けてみよう。'}, {'text': 'ご視聴ありがとうございました。'}
なお、音声データで発話されている内容は以下のようになります。
{'text': 'また、東寺のように、五大明王と呼よばれる、主要な明王の中央に配されることも多い。'}, {'text': 'ニューイングランド風は、牛乳をベースとした、白クリームスープであり、ボストンクラムチャウダーとも呼ばれる。'}
比べると、文字起こしが全く正確でないことが分かると思います。この問題はどのように解決できるでしょうか?
バッチ処理の問題の解決方法
この問題の主原因は「サンプリング周波数を 16,000 [Hz] 以外の音声信号を Whisper に入力した」ことです(サンプリング周波数の説明については後述します)。それであれば、入力する音声データのサンプリング周波数をどうにかして 16,000 [Hz] に変更できれば良さそうです。
ちなみに、音声データを 1 つずつ処理する場合は、このサンプリング周波数の問題が Whisper 内部で自動で解決できます。これを実現するためには、まず、whisper-large-v3 モデルのサンプルコードの sample を以下のように書き換えれば良いです。
sample = {
"sampling_rate": 48000,
"raw": dataset[0]["audio"],
}
result = pipe(sample)
上記において、"sampling_rate" には入力する音声データのサンプリング周波数を指定し、"raw" には入力する音声信号を指定します。
このような入力にすると、AutomaticSpeechRecognitionPipeline の preprocess メソッド内の関数(こちらを参照してください。)によって 16,000 [Hz] になるように音声データのサンプリング周波数が変換されます。これにより、音声信号を 1 つずつ処理する場合は、任意のサンプリング周波数の音声でも適切に処理できます。
バッチ処理も上記と同様に Whisper 内部で処理できればよいですが、残念ながら、 Whisper への入力の段階で "sampling_rate" を指定できないため、任意のサンプリング周波数を扱えません。また、バッチ処理の実装を見ると、上述のようにサンプリング周波数を変換する処理が存在しないため、Whisper 内部では変換できないはずです。
手っ取り早い解決方法としては、全ての音声データのサンプリング周波数を事前に変換しておくことです。
def resampling_waveform(waveform, sample_rate): return F.resample(torch.from_numpy(waveform), sample_rate, 16000).numpy() resampled_waveform_list = [resampling_waveform(waveform, 48000) for waveform in waveform_list]
これは前述の preprocess メソッド内と同様の方法です。このようにして作った resampled_waveform_list をパイプラインに入力してバッチ処理すれば、文字起こし精度の劣化が抑えられることが期待できます。
実際に、前述の実験で用いた音声データ( サンプリング周波数 48,000 [Hz] )を 16,000 [Hz] に変換し、それを Whisper でバッチ処理すると以下のような結果を導出できます。
{'text': 'また陶寺のように古代明王と呼ばれる主要な明王の中央に配されることも多い'}, {'text': 'ニューイングランド風は牛乳をベースとした白いクリームスープでありボストンクラムチャウダーとも呼ばれる'}
上記を見ると「陶寺」のみ漢字の間違いがありますが、ほとんど正確な文字起こし結果が得られました。
バッチ処理の問題
問題の回避方法は分かりました。しかし、なぜ「サンプリング周波数が 16,000 [Hz] 以外の音声データ」の場合には文字起こしの精度が劣化するのでしょうか?
本章ではこの疑問について考察したいと思います。まずは、この現象を理解するために、音声に対する予備知識から紹介します。
予備知識1:サンプリング周波数
まず、サンプリング周波数とは何か?から説明を開始します。
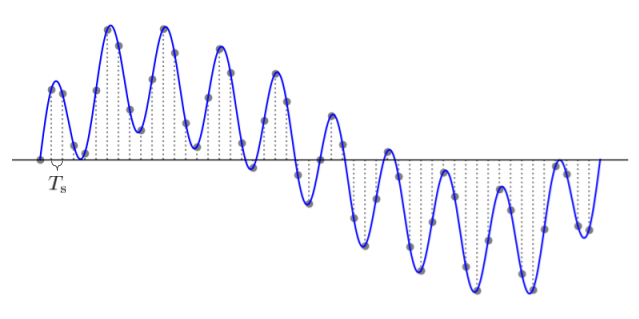
上図の青線が、音などの生の音声信号(アナログ信号)となります。このアナログ信号は連続した値となっているため、これをそのまま PC 上で処理することができません。この問題に対処するため、上図のように、アナログ信号を一定間隔の 秒ごとに信号値をサンプリングする必要があります *4 。
このサンプリング間隔 より、サンプリング周波数
は以下のように求められます。
この式を見ると、サンプリング周波数は、アナログ信号から 1 秒間に何回信号値をサンプリングするかを表す指標であると理解できます。
予備知識2:アナログ信号の周波数
サンプリング周波数と似た名前で、信号の周波数というものがあります。これは、アナログ信号が下図のように正弦波の重み付き和で表現したときの指標になります。
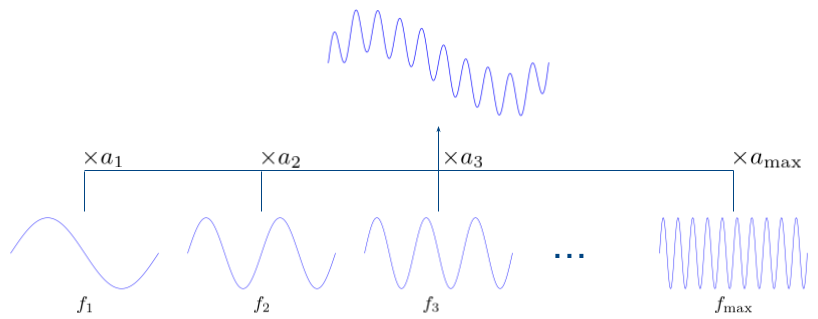
上図の というのが、観測されたアナログ信号に含まれる周波数になります。このときの周波数は、1 秒間にいくつの波が含まれているかという指標で、最大周波数
に近い周波数ほど高い音の成分になります。
この性質から、例えば、高い音の成分を抑えたいならば、最大周波数 に近い周波数の値(
であれば
の値 )を小さくすれば良いです。つまり、所望の性質の音声を得たい場合は、この周波数の値を上手く変換すればよいです。
予備知識3:サンプリング定理
前述のように、PC 上で音声を扱う場合は、サンプリングされた信号を処理することになります。このとき、サンプリングは元のアナログ信号から値を捨てていることになるので、音の性質自体が保てないのでは?と直感的に思うかもしれません。
幸いなことにサンプリング定理 *5 によって、アナログ信号の性質を完全に保ったままサンプリング出来ることが知られています。そのサンプリング定理は以下のようになります。
上記のようなサンプリング周波数でサンプリングされた信号値であれば、元のアナログ信号が復元可能という定理です。
この定理から、例えば、音声信号のサンプリング周波数が 16,000 [Hz] であれば、8,000 [Hz] までの周波数の値が扱えるように、音声信号がデータとして保存されているはずです *6 。
原因の考察
まず、Whisper のアルゴリズムを openAI の公式ページで確認してみましょう。openai.com
これより Whisper では、入力した音声信号は Log-mel spectrogram に変換したあとに、エンコーダ・デコーダの処理が開始します。この Log-mel spectrogram ですが、「人間が実際に耳で知覚しているような値」になるように音声信号の周波数の値が変換されたものになります *7 。
この Log-mel spectrogram への変換は、Whisper のコードのこの部分 で行われています。この箇所をよく見ると、入力した音声信号の 0 ~ 8,000 [Hz] の周波数に対して変換が行われるようです。注意したいのが、この変換の上限値である 8,000 [Hz] は、どのような音声信号が入ってきても固定されていることです *8 。
この固定された上限値が、ここでは問題となります。これについて、例を示して説明します。
- 最大周波数が 4,000 [Hz](サンプリング周波数が 8,000 [Hz] )の音声信号を入力した場合
- 4,000 [Hz] 以下の周波数の値は変換される
- 4,000 [Hz] より大きい周波数の値は存在しないはずなので 0 になる
- 最大周波数が 24,000 [Hz](サンプリング周波数が 48,000 [Hz] )の音声信号を入力した場合
- 8,000 [Hz] までの周波数の値は変換
- 8,000 [Hz] より大きい周波数の値は切り捨て
以上のように、周波数の値が 0 で代用されたり、そもそも値が切り捨てられることで、元の音の性質が大きく変わってしまう事態に陥っています。この意図しない音声データの変化が、文字起こしの劣化に大きく関わっていると言えるでしょう。
以上より、最大周波数が 8,000 [Hz] 、つまり、サンプリング周波数が 16,000 [Hz] の音声信号を入力することが、上記の変換が意図通りに実施され、文字起こし精度が保たれる理由です。
余談
上記は、既に音声データをメモリにロードしている状態に対して有効な方法です。
本研究で取り扱っている音声データでは、Whisper に入力する前に音声データを適切に分割する処理が必要となりました。その処理を行った音声データをファイルに書き出すには、処理時間・ストレージの容量の観点から難しい状況です。そこで上記のように、メモリに既にロードされた音声データに対してリサンプルをしてバッチ処理を実施する方法を採用しました。
しかし、公式のバッチ処理の想定は音声データファイルのパスを入力することだと思います。Whisper 内部では ffmpeg が使用されているので、音声ファイルをロードする際にサンプリング周波数を 16,000 [Hz] に変換していることも考えられます。ここに関しては確認していませんので、読者の皆様からのコメントを待ちたいと思います。
また、リサンプリングなどを用いずにサンプリング周波数が 16,000 [Hz] 以外の音声データを用いたい場合は、Log-mel spectrogram に変換する際の周波数を 8,000 [Hz] に固定せず、サンプリング周波数の半分である を採用できるように書き換える必要があると思います。
上記に加えて、エンコーダ・デコーダに入力する配列の大きさなどを調節し、モデルの再学習を時間をかけて実行すれば、特定のサンプリング周波数に合ったモデルができるかもしれません。
まとめ
今回は Whisper のバッチ処理における入力音声データの気をつける点を記述しました。本記事では、なぜサンプリング周波数が 16,000 [Hz] の音声データでないと文字起こし精度が劣化するのかの理由を、信号処理の観点から示しました。そして、実際に、この問題の回避方法についても示しました。本記事が、同様な問題に直面した方々の一助になれば幸いです。
バイセルでは一緒に働くエンジニアを募集しています、興味がある方は、以下よりご応募ください。 herp.careers 明日の バイセルテクノロジーズ Advent Calendar 2024 は内田さんによる 「1年でSecure SketCHの点数を100点以上向上させた話」です。 お楽しみに!
*1:セールス担当者のお客様対応の質の向上・教育を目的として、お客様の許可を得て録音されたものです。
*2:Whisper の他にも Google Cloud の speech-to-text の利用も考えました。しかし、費用面と文字起こし精度を考慮して Whisper を利用することにしました。ただし、2024 年 11 月の段階での話ですので、今後、Whisper 以外の候補が出てくるかもしれません。柔軟にモデルの変更を検討したいです。
*3:whisper-large-v3 モデルの場合は、1回の文字起こしで 10 GB ほどのメモリを使用するようです。これだと、多くのデータ数を並列処理するのは厳しいと思います。
*4:サンプリングする以外にも、信号値を量子化する処理も合わせて必要になりますが、本記事の内容には直接関係してこないので説明を割愛します。
*5:導出などの理解には以下の書籍をおすすめします。「山下幸彦, 田中聡久, 鷲沢嘉一. 工学のためのフーリエ解析, 数理工学社, 2016年, p. 179」
*6:ディジタルオーディオの代表例である CD (コンパクト・ディスク)では、サンプリング周波数が 44,100 [Hz] と決められています。これは、人間の可聴域の上限がおおよそ
20,000 [Hz] であることに依存した設定のようです。これはサンプリング定理を満たしているので、アナログ信号に復元可能です。この辺の内容をより知りたい人は、「田中聡久, 川村新. 音声音響信号処理の基礎と実践, コロナ社, 2021年, p. 220」を読んでみてください。
*7:人の耳は、低周波の音に敏感に知覚し、高い音を低めに知覚するようです。その性質を考慮した変換となります
*8:メルフィルタバンクの初期値 を見ると変換する周波数が固定されていることが分かると思います。