

こちらはバイセルテクノロジーズ Advent Calendar 2023の20日目の記事です。
前日の記事は飯島さんの「開発者の脳内リソースを食い潰さないという観点のフロントエンド設計」でした。
こんにちは。テクノロジー戦略本部 開発三部の今井です。
私は現在、顧客対応・SFAシステム(以下、CRM)の開発に携わっています。
本記事では、以前執筆した「AlloyDBを採用したCRMアーキテクチャの設計と運用」の中で触れた「業務向けの機能の互換性を担保する必要がある」についてまとめます。
背景
弊社ではDXの取り組みのひとつとして、さらに多様な買取・販売チャネルに対応し、買取から販売まで一気通貫してデータを管理・活用する「バイセルリユースプラットフォーム Cosmos」(以下、Cosmos)の開発を進めています。
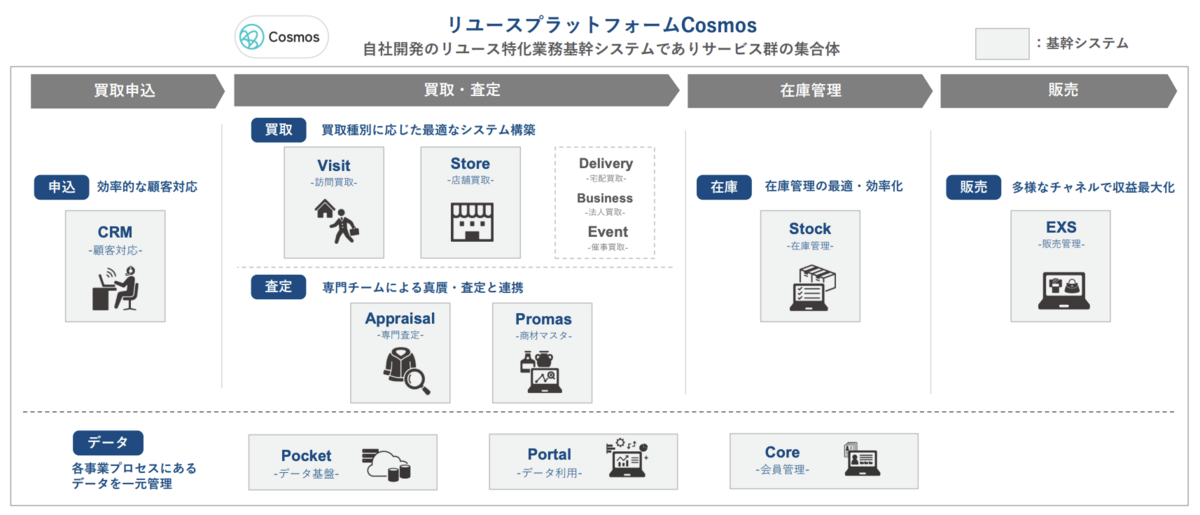
その中で私が携わっているプロジェクトでは、インサイドセールス部門で使用するCRMを開発しています。
主力事業である出張訪問買取の最初の入口となり、将来的にはマーケティング部やセールスコンプライアンス部等顧客対応のハブとなるシステムを目指しています。
CRMプロジェクトは2023年1月にキックオフされ、2023年10月にリリースしました。
またCRMでは、DBにAlloyDB for PostgreSQL(以下、AlloyDB)を採用しています。
AlloyDBを採用した詳細な背景や、その他の技術的な側面については、以前執筆したブログで掘り下げています。
興味のある方は、以下のリンクからご覧ください。
データ分析やレポート作成といった業務向けの機能を担保する必要がある
上記のブログでも触れていますが、AlloyDBを採用するうえでの課題のひとつに「業務向けの機能の互換性を担保する必要がある」という点がありました。
具体的には、既存のデータ基盤のアーキテクチャを維持しつつ、データ分析やレポート作成等の業務向けの機能を担保する必要がありました。
既存のアーキテクチャ
Cosmosではデータ基盤を運用しており、蓄積されたデータを元に、様々な業務向けの機能を提供しています。
また要件に応じて、主にBigQueryとRedashを使い分けています。
BigQueryでは、稼働しているシステムのデータを一元管理し、分析やレポートの作成に利用しています。
既存システムの大半は、DBにCloud SQL for PostgreSQL(以下、Cloud SQL)を採用しており、Cloud SQL federated queriesを利用し、BigQueryから直接Cloud SQLに保存されているデータを照会しています。
データ基盤のBigQueryからは、Scheduling queriesを利用して、定期的に既存システムのBigQueryへクエリを実行し、必要なデータを参照できる設計になっています。
またRedashでは、リアルタイムに知りたいデータを参照するため利用しています。
既存システムではCloud SQLのリードレプリカを作成し、データ基盤のRedashから参照できるようにしています。

AlloyDBを採用したことによる課題
今回CRMで採用したAlloyDBでは、今までと同様のアーキテクチャを採用することができませんでした。
理由としては大きく2つあります。
1つは、AlloyDBではCloud SQL federated queriesを利用することができず、BigQueryから直接AlloyDBに保存されているデータを照会することができないためです。
もう1つは、AlloyDBではパブリックIPでの接続をサポートしておらず、プライベートIPのみでの接続が必要なためです。
その結果、Redash等の外部ツールからAlloyDBに直接接続することができません。
要件を満たすためにDatastreamを採用
こういった技術的な課題を解決するために、私たちはDatastream for BigQuery(以下、Datastream)を採用しました。
Datastreamは、BigQueryのChange Data Capture(CDC)機能とStorage Write APIを使用して、ソースシステムからの更新をニアリアルタイムで効率的にレプリケートできます。
従来のバッチ処理では、定期的に全データを転送する必要があり、これは大量のリソースを必要とすることがあります。特に、大規模なテーブルを扱う際には、この問題は顕著になります。
しかし、CDCを用いたDatastreamでは、変更されたデータのみを処理します。そのため大規模なデータセットに対しても効率的な差分更新を実現できます。
アーキテクチャは以下の通りです。
プライベート接続を用いたDatastreamの設定では、Virtual Private Cloud(VPC)ネットワーク間で専用の接続が確立され、プライベートIPアドレスを使用してリソースと通信します。
しかし、DatastreamとAlloyDBのネットワーク間で直接ピアリングができないため、AlloyDBにアクセスするにはプロキシサーバーが必要になります。このセットアップにより、VPCネットワーク間での安全なデータ転送を実現できます。

こうすることで、AlloyDBのデータをBigQueryにレプリケートし、データ基盤のアーキテクチャを維持しつつ、業務向けの機能を提供することができるようになりました。
Datastreamを採用する際の注意点
Datastreamを採用するにあたって、いくつか考慮するべき点があります。
※こちらではソース PostgreSQL データベース(AlloyDB for PostgreSQL を含む)について記載していますので、MySQLやOracle等の他のソースを使用する場合は、公式ドキュメントを参照してください。
設計面
PostgreSQLのDBをソースとして使用する場合にはいくつか制限があります。
一部を挙げると、主キーのないテーブルではREPLICA IDENTITYが必要であり、ない場合はINSERTイベントのみが移行先に複製されます。
またgeometric型やrange型等といったデータ型はサポートされていません。
CRMでは2023年5月頃にDBスキーマの設計をしており、一部のカラムでEnum型やArray型を検討しておりましたが、当時はサポートされていなかったため設計を見直しました。
※2023年12月現在、Enum型とArray型はサポートされています。
またストリームの同時実行についても考慮する必要があります。
DatastreamにはCDCと、全てのデータを一括で同期するバックフィルの2つの動作があります。
PostgreSQLの場合、バックフィルタスクの最大数のみ調整することができます。
バックフィルタスクの最大数を調整することで、スループット(データ移行の速度)を管理できます。
最大数を増やすとバックフィルのスピードは上がりますが、それに伴いDBへの負荷も増大します。
最大数を減らすと、バックフィルによるDBへの負荷は軽減されますが、その分データ移行にかかる時間が長くなる可能性があります。
バックフィルタスクの設定は、Datastreamの効率とDBへの影響のバランスを取る上で重要になります。
CRMでは、10月の初回リリース時にはテーブル数やデータ量が比較的少なかったため、バックフィルタスクの最大数をデフォルトの15に設定して運用を開始しました。
将来的にはテーブル数やデータ量の増加が見込まれるため、バックフィルタスクの適切な設定値を検討しています。
したがってDBスキーマの設計後やアーキテクチャ設計後にDatastreamの採用を決めると、設計の見直しやアーキテクチャの変更が必要になる可能性があります。
運用面
また運用時にも注意点があります。
システムを運用していると、DBスキーマの変更(カラムの追加や削除等)が必要になることがあります。
Datastreamでは変更されたカラムの位置(テーブルの中央なのか最後尾なのか等)によって、BigQueryへのデータ移行時の挙動が異なります。
実際にCRMでは、運用中にDBにある一部テーブルの最後尾のカラムを削除したところ、以下のような挙動になりました。
- 該当のカラムを削除した後も、BigQueryに連携されているカラムは残留する。
- 新規のレコードをインサートした場合、BigQueryに連携されている該当のカラムは
NULLとなる(他レコードのデータに影響はなし) - 既存のレコードを更新した場合、BigQueryに連携されている該当のカラムも
NULLとなる(同じく他レコードのデータに影響はなし)
こういった側面があるため、DBスキーマの変更を行う際にはDatastreamの挙動を十分に検証してからproductionにリリースする必要があると考えています。
また運用中に非本番環境にてDatastreamのストリームが停止したことがありました。
先に添付したアーキテクチャにある通り、DatastreamとAlloyDBの接続をプロキシするためにCompute Engineでプロキシサーバーを立てています。
停止した際、DatastreamとAlloyDBには特に問題がなかったのですが、途中のCompute Engineでの通信に問題が発生しているように見受けられ、Compute Engineの再起動で解決しました。
こういった事象が発生したため、Datastreamだけでなく、Compute Engineの運用や監視も必要になります。
最後に
本記事ではDBにAlloyDBを採用した際、Cloud SQLとの機能差分を埋めるためにDatastreamを採用したことについてまとめました。
CDCを用いたデータのレプリケーションをゼロから構築する際には、考慮すべき要素が多く、その開発にはかなりの工数が必要だと考えています。
しかしDatastreamの採用により、この複雑なプロセスを大幅に簡素化し、効率的に開発することが可能になりました。
また運用面では多くの注意点が存在するため、継続的な監視と調整が必要となりますが、上記のメリットを考えるとDatastreamの採用は良い選択だったと考えています。
バイセルではエンジニアを募集しています、一緒に働きたい方は、以下よりご応募ください。
明日のバイセルテクノロジーズ Advent Calendar 2023 は大木さんの「Google Analytics 4活用方法見直し:システムの主要クリックイベントが半自動で収集できるようになるまで」です。
お楽しみに。