

- はじめに
- 前提
- 課題
- 解決策
- 具体的な手法の説明
- 実践してみてどうだったか
- 今後の展望
- まとめ
はじめに
こちらはバイセルテクノロジーズ Advent Calendar 2023の19日目の記事です。
前回の記事は、富澤さんのCloud Runを利用したプルリクエストごとの動作確認環境の構築でした。
こんにちは、開発2部の飯島(@kazizi55)です! 普段はリユースプラットフォームの在庫管理SaaSでフロントエンドをメインに開発しています。今年の9月末にMVP(Minimum Viable Product)をリリースしました。現在はビジネスサイドのフィードバックを取り入れながら、全国のグループ企業の店舗への導入を進めています。
在庫管理SaaSはアジャイルで開発しており、ドメインエキスパートやビジネスサイドの方々の意見を取り入れながら、改修を進めています。
そのため、作った機能の組み替え・追加・削除を、柔軟かつ迅速に実施することを通して、より良いプロダクトを作ることが求められます。
そして当然ながら、コードが乱雑になるとその動きは鈍化します。
よって、認知負荷を下げて素早く開発できるように、コード上の変更点を可能な限り明らかにすることが肝要だと思いました。
そこで、今回は「開発者の脳内リソースを食い潰さないような設計」の一例を紹介します。
前提
今回紹介する設計は、以下の技術構成を前提としています。なお、個々のライブラリの説明は省略します。
- 言語・フレームワーク
- React、 TypeScriptを用いたフロントエンドでの設計を想定
- Next.jsは不使用
- ネットワーク層
- バックエンドと通信するための型と
custom hooksを自動生成 - React Routerを使ってルーティング
- バックエンドと通信するための型と
課題
さてみなさん、以下のような特徴のコードに悩まされた経験はありますか?
- APIから自動生成された型と、フロントエンドで定義された型とが混在している
- 親と子の責務がはっきりしていないので、fetchがいろんなファイルに分散している
以下は具体例です。
// App.tsx const BadApp: React.FC = () => { const { data } = useGetUsers(); return ( <BadUserList // APIから自動生成された型のまま子に渡す users={data} /> ) } export default BadApp;
// BadUserList.tsx // フロントエンドで定義された型 type ProcessedUser = { id: number; name: string; } // APIから自動生成された型 type BadUserListProps = { users: ModalUser[]; } export const BadUserList<BadUserListProps> = ({ users, }) => { // ルールをはっきり決めずに、子でもfetchしている const { data } = useGetUserRoles(); // フロントエンドの型のオブジェクトに変換している const processedUsers = useMemo(() => users.map<ProcessedUser>(({ id, name }) => ({ id, name, })), [users]); return ( processedUsers.map((user) => { return ( // APIから自動生成された型のオブジェクトと、フロントエンドで定義された型のオブジェクトの両方を子に渡してしまっている <Row key={user.id} user={user} userRoles={data} /> ) }) ) }
このようなコードが常態化していると、以下の点でコードを読み書きする際に迷いを生み、開発者の脳内リソースを消費します。
- フロントエンドの型か、APIから自動生成された型か
- 一目でどちらの型かわからない
- どちらの型を実装で使えばいいかわからない
- fetchをどの階層に置くか
- どの階層に置いたらいいかわからない
さらに、実際の改修時は、ロジックがあらゆるファイルから参照されている可能性があるので、参照元のリグレッションを気にしながら開発しないといけません。ますます開発者の脳内リソースを消費するでしょう。
この事象を解決するような設計を以下でご紹介します。
解決策
具体的な解決策は以下です。
- 特化1
components・hooksを基本的に作るようにする - ファイルがどこから参照されているかわからない課題に対処
pages層でfetchをしきり、フロントエンド・バックエンド間の型の不整合も解消しきる- 型やロジックの定義場所がわからない課題に対処
これらの解決策を実現するために、在庫管理SaaSではbulletproof-reactのディレクトリ構造とAtomic Designの合わせ技のような構成を採用しています。
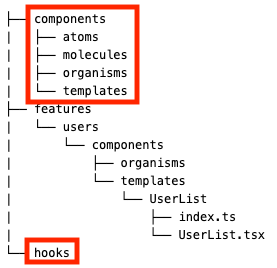
以下は簡潔な例です。
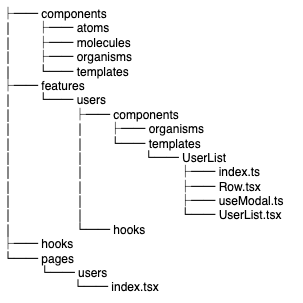
以下のようなルールのもとにファイル分けを行なっています。上のディレクトリ例をもとに説明します。
1. features/components/templates配下でのルール
pageに対応したcomponentsを1つ作って、pages配下のindex.tsxから呼ぶ
pages配下のusers/index.tsxに対応して、features/components/templates配下でUserList.tsxを作成しています。

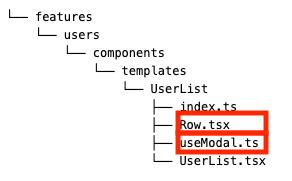
components・hooksを追加する際は、特化components・hooksを基本的に作って、呼び出すcomponentsと同じ階層に配置する
features/components/templates配下のUserList.tsxの特化componentsとして、Row.tsxやuseModal.tsを作成しています。
 )
)
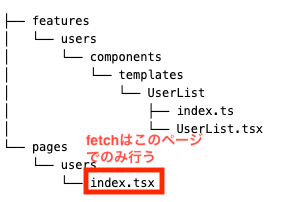
2. pages配下のindex.tsxでのルール
fetchをしきる。これより下のcomponentsではfetchを行わない
pages配下のusers/index.tsxでfetchをしきり、それより下のUserList.tsxやRow.tsxではfetchを行いません。
フロントエンド、バックエンド間の型の不整合を解消しきる
pages配下のusers/index.tsxで、fetchをした後、features/components/templates配下からimportした型のオブジェクトに変換します。

これらのルールによって以下が明確になり、開発者の脳内リソースの消費を抑えることができます。
- どの階層にどのファイルがあるか
- それぞれのファイルの影響範囲はどれくらいか
では、改めて次の章で以下の2点の解決策について深ぼって説明します。
- 特化
components・hooksを基本的に作るようにする pages層でfetchをしきり、フロントエンド・バックエンド間の型の不整合も解消しきる
なお、紹介する手法によってパフォーマンスが落ちることもあります。しかし、プロダクトを早く形にすることを優先した為、今回は許容しました。
具体的な手法の説明
特化 components・hooksを基本的に作るようにする
概要
components・hooksを追加する際は、特化 components・hooksを原則作るように開発ルールを決めました。
既存のファイルを使い回すのではなく、新しくファイルを作っていくことが前提です。
他のファイルでも複数箇所で同じ内容のものが見受けられ、かつ同じような変更をするのが辛くなってきたら、初めて外に切り出して共通化をするという流れです。
なお、切り出す先としては以下の2つの選択肢があります。
features配下のcomponents/organismsやhooksfeatures外のcomponentsやhooks
切り出す対象が同じfeatures内だけでimportされていたら、features配下のcomponents/organismsやhooksに切り出します。
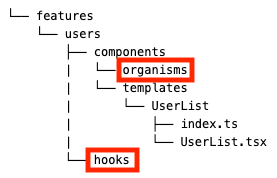
一方で、同じfeatures外でもimportされていたら、features外のcomponentsやhooksに切り出します。
メリット
ディレクトリの全体を把握していなくても迷わずに改修が行える
基本的にfeatures/components/templates配下の対象ページのファイル群だけを気にすれば良いです。
また、共通 components・hooks 2を使うとしても、それらが置かれているディレクトリで影響範囲が明確になっているので、以下の場合は使って問題ないとしました。
同じfeatures内に共通components・hooksがある
同じfeaturesのhooks配下かcomponents/organisms配下に使い回せるファイルがある場合は、それらを使い回すようにします。
以下の例だと、UserList.tsxから共通コンポーネントを使う場合、この2つが使い回せます。
features/users/components/organisms配下のRow.tsxfeatures/users/hooks配下のuseModal.ts
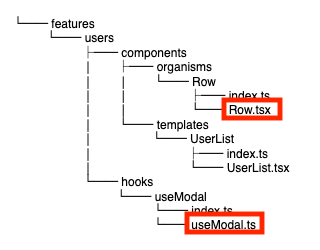
ルートのcomponentsあるいはhooks配下に共通components・hooksがある
ルートのhooks配下かcomponents配下に使い回せるファイルがある場合は、それらを使い回すようにします。
以下の例だと、UserList.tsxから共通コンポーネントを使う場合、この2つが使い回せます。
components/organisms配下のRow.tsxhooks配下のuseModal.ts

上で挙げた条件以外の場合は特化 components・hooksを作る、という形で迷わず開発できるようになっています。
デメリット
共通化の動機が湧きづらい
現状、ファイルの共通化は開発フローから外れており、同じようなファイルが複数あると感じた人が任意で共通化しているというのが現状です。
また、共通化しても要件が変わって共通化をやめることがしばしばあるので、より共通化が遠のいてしまっています。
今は致命的でないですが、今後コードがさらに増えていくにつれて、管理コストも上がっていきます。そのため、将来的に共通化を促す仕組みを導入していきたいと考えています。
pages層でfetchをしきり、フロントエンド・バックエンド間の型の不整合も解消しきる
概要
「データフェッチと、APIから自動生成された型→フロントエンドの型へのマッピングをpages層で完結させる」という開発ルールを定めています。
fetch戦略的にはfetch then renderです。
なお、pages層で行う処理の具体例は以下です。(importは省略しています。)
const UserListPage: React.FC = () => { const { data } = useGetUsers(); // features/templatesからimportしたpropsの型であるRowのオブジェクトに代入 const users = useMemo(() => data.map<Row>(({ id, name }) => { return { id, name, }}), [data]); // features/templatesからimportしたcomponentにpropsを渡す return ( <UserList users={users} /> ) } export default UserListPage;
メリット
fetchをする場所に迷いがなくなる
pages層で一括してfetchすると決めているので、fetchする処理を新たに追加する際やコードレビューの際に迷いがなくなります。
なお、複数のfetch処理を記述することによって、pages層のコード量が肥大化する場合もあります。しかし、適宜custom hooks として別ファイルに切り出せばコードの見通しの良さは維持できるので、あまり問題ではないと考えています。
pages層より下はフロントエンドで定義した型しか存在しない
pages層でAPIから自動生成された型のオブジェクトからフロントエンド側の型のオブジェクトに変換しきります。それにより、下の階層では全てフロントエンド側の型とみなすことができて認知負荷を下げることができます。
APIから自動生成された型にpages層までしか依存しないので、APIから自動生成された型に変更があっても修正するのはpages層のみで済みます。
APIをモックしないでstorybookが書ける
pages層より下のcomponentsではfetchが呼ばれないので、API処理部分をモック化しなくても、storybookを作成して画像回帰テストやインタラクションテストが可能になります。
storybookを書く際にAPIモック作成が不要となるため、テスト作成の工数を削減できます。
デメリット
fetchのパフォーマンスは低下する
pages層で一括してfetchするfeatures/components/templatesからimportしたpropsの型のオブジェクトに代入する
という前提があるため、propsによっては複数のAPIレスポンスをもとに1つのオブジェクトに代入することもあります。
その場合、いずれかのAPIレスポンスの中身が変わるたびに、オブジェクト全体が作り替えられて再レンダリングが発生することになるのでパフォーマンスは低下します。
以下がpages層での具体例です。
const { data: userData } = useGetUsers(); const { data: roleData } = useGetRoles(); /** * userDataとroleDataをjoinして1つのオブジェクトにしている。 * いずれかの内容が変更されると作り替えられる。 */ const rows = useMemo(() => userData.map<Row>((user) => { const roles = roleData.filter((role) => role.userId === user.id) return { id: user.id, name: user.name, roles: roles.map((role) => ({ id: role.id, name: role.name })) }}), [userData, roleData]); return ( <UserList rows={rows} /> )
バックエンドエンジニアと会話してAPIレスポンスのインタフェースを決める際に、このようなパフォーマンス低下を避けることも話しあっているので、こういったケースはあまりないです。しかし、バックエンドエンジニアでの実装コストや納期などの兼ね合いから起こりえます。
実践してみてどうだったか
今年の3月に開発がスタートしてから9ヶ月経ちますが、紹介した手法を導入しているため、以前参画していたプロダクトと比べても、より認知負荷が少なく、スピード感を維持して開発できています。
在庫管理SaaSのフロントエンド開発に慣れてないメンバーでも、慣れているメンバーと同程度にアウトプットを出すことができるようになっています。
また、ディレクトリ構成は決められた内容に沿っているかどうかを気にすれば良く、見る観点を絞れるので、レビューの工数も減らせています。
今後の展望
開発ルールを守ってもらうための静的解析ツールを入れようと考えています。異なるfeaturesのcomponentsやhooksをimportした場合や、pages層以外でfetchしようとした場合にlint errorを起こすことで、ルールを強制します。
まとめ
今回は、「開発者の脳内リソースを食い潰さないために、フロントエンドでどう設計していくか」というテーマで執筆しました。
まだまだ在庫管理SaaSの設計に関して伸び代はあるので、これからより良い形でどんどんブラッシュアップしていきたいです。
最後にBuySell Technologiesではフロントエンドエンジニアを募集しています。興味がある方はぜひご応募ください!
明日のバイセルテクノロジーズAdvent Calendar 2023は今井さんによるDatastreamによるCRMのデータ同期とアーキテクチャの最適化です。お楽しみに。