

はじめに
こんにちは、タイムレスオークション開発チーム所属の臼井です。 今回はオークションというパフォーマンスが重視されるサービスにおいて、継続的にパフォーマンス改善を行なっていることについてお話しします。 なかなかパフォーマンス改善に着手できていないが、やりたいと考えている方や、実際にどのような手順でパフォーマンス改善をしたらよいかわからない方の参考になれば幸いです。
背景
タイムレスオークションとは
私たちのチームで運用しているタイムレスオークションは年間出品数270,000点以上を誇る、日本最大級のBtoBのオークションサービスです。 オンライン開催オークションと、現地リアルタイムで参加できる平場オークションの2種類があり、毎月決まった日時に開催されています。
システムの説明
オークションはバックエンドをRuby on Rails、フロントエンドをNext.jsで実装しており、今回は主にバックエンドのパフォーマンス改善にフォーカスしています。 インフラはAWSのECS、RDS、S3などを使用しています。
オークションというドメインに関する課題
オークションでは、入札処理はDBトランザクションを厳密に制御する必要があり、コンテナやDBの負荷が高くなりやすいです。 また、入札終了時間の間際に入札が重なるため、リクエスト数が急増します。 そのため、インフラのオートスケーリングがリクエスト数の増加に間に合わず、CPU負荷が高まり、レイテンシが増加することもありました。 スケジュールドスケーリングなどで対応していますが、商品数や入札数などの規模が段々大きくなっており、放っておいたらパフォーマンスがだんだん悪くなるので、継続的なパフォーマンスの改善は必須です。 自分が改善を始めた当初は、ECSやRDSのCPU使用率は限界に近い状態でした。
具体的な取り組み
パフォーマンスの改善には主にNew Relicを使用しました。 月1で負荷の振り返りをチームで行い、New RelicのAPMのTransactionsを見て、Total timeが大きいものから順に改善していきました。 Total timeは、選択した期間内で平均処理時間に呼ばれた回数をかけたものの、全体に対する割合になります。 Total timeが大きいものは、そのTransactionがサーバーのリソースを多く使っており、ボトルネックになっていると考えられるので、多くの場合、一番上から改善していくことが効率的な方法となります。 以下では、具体的にどのような改善をしたかを紹介します。
1. リクエスト数が意図せず多かったAPIの改善
まず初めに一番Total timeが大きかったものは、QRコードを生成するAPIでした。 こちらのQRコードは、平場に参加する際の参加証として使用されているものです。
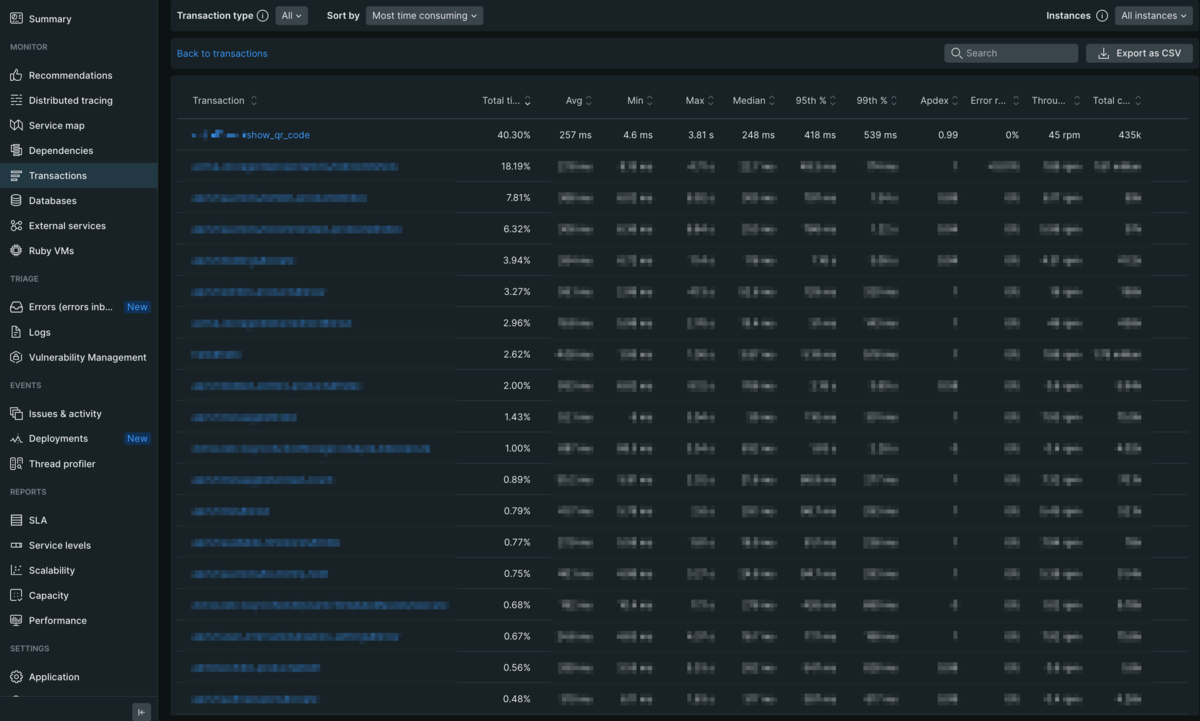
QRコードを生成するのは確かに多少重い処理ですが、このAPIは通常利用していれば1ユーザーにつき1日1回しか呼ばれない想定ですので、そこまでTotal timeが大きくなるとは思えません。 何かおかしいと思いリクエスト数を見ると、想定よりかなり多く呼ばれていることがわかりました。 FE側の呼び出しに問題がありそうだと考え、FEのコードを確認したところ、想定外のタイミングでAPIが呼び出されていることがわかりました。 適切な箇所でAPIを呼ぶようにコードを修正することでリクエスト数を激減させることができ、Total timeが40%以上だったTransactionの負荷をほぼ解消できました。
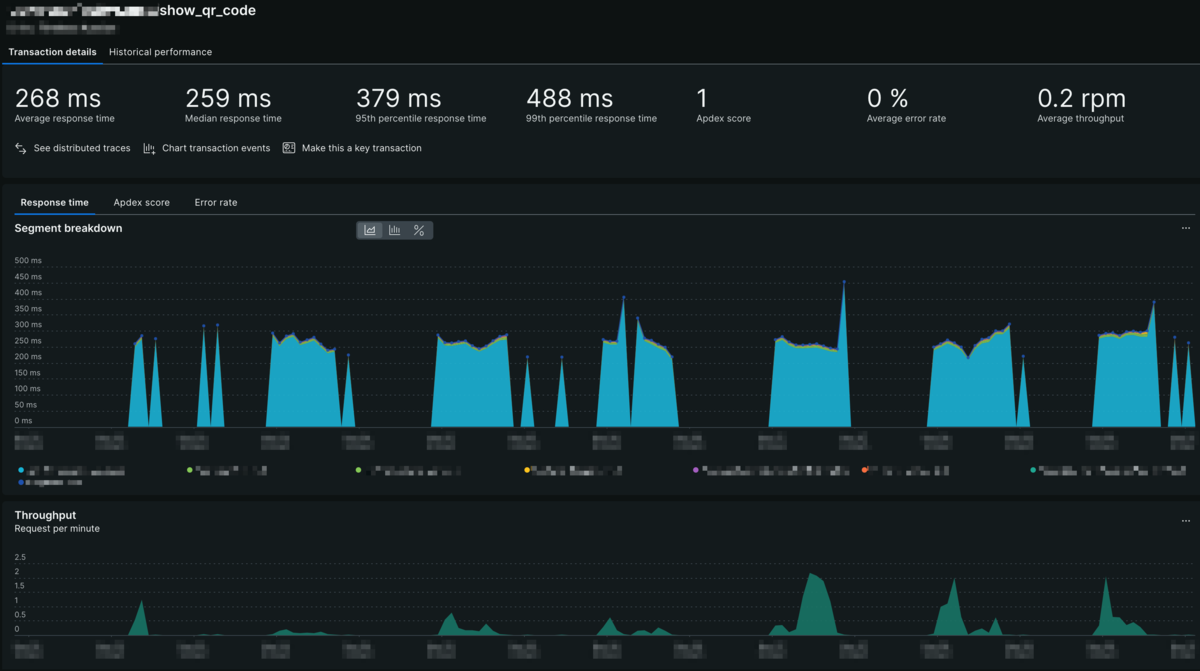
単純計算はできませんが、たったこれだけの調査と実装で元の負荷を4割削減したことになります。 これを見るとかなり簡単に改善できているように見えますが、そもそも計測しなければ気づけないものですので、計測することがいかに重要かがわかります。 計測し、かつ改善しようと取り組めば、意外と簡単に改善できることもあるので、まずは計測してみることが大切です。
2. データベースクエリの最適化
次にTotal timeが大きかったTransactionはいくつかの検索系のAPIです。 Transactionの中身を詳しく見ていくと、同じようなタイプのSQLクエリに非常に時間がかかっていることが分かりました。
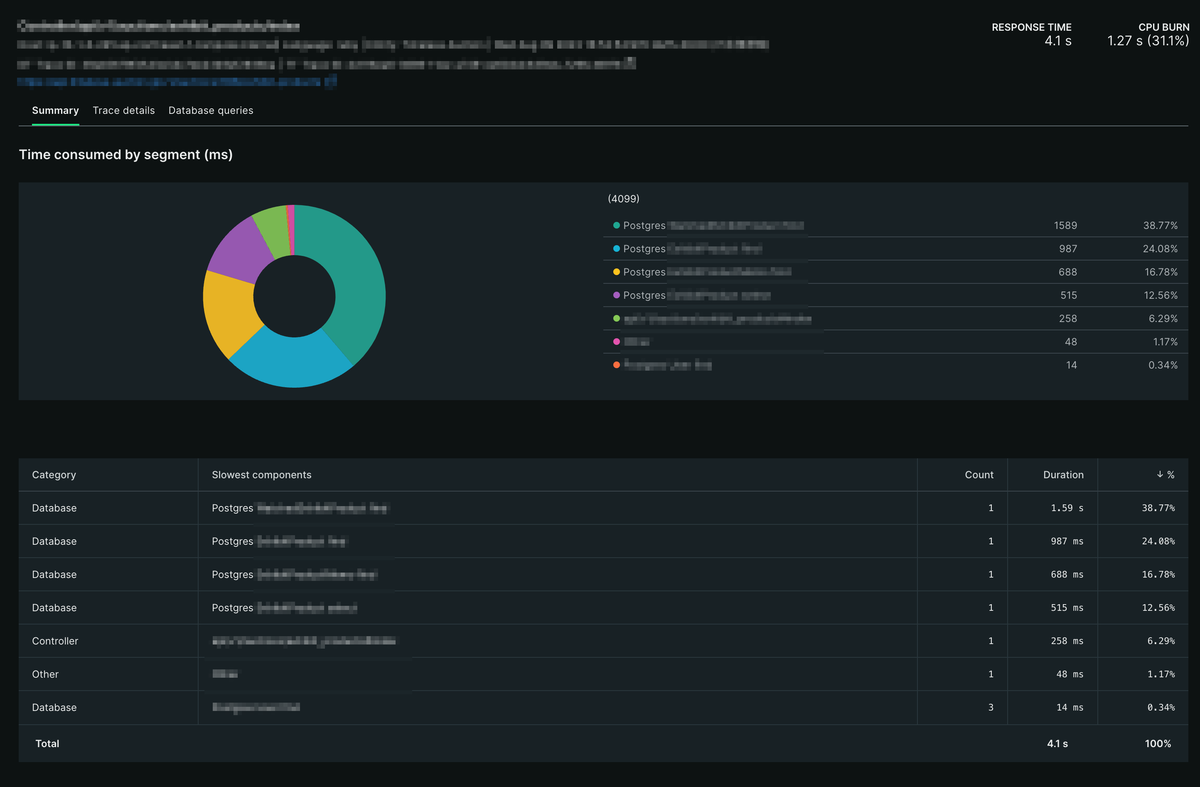
クエリを確認すると、テーブルには適切にインデックスを貼っているのに、そのインデックスを使わないクエリになっていました。 さらにコードを見ていくと、RailsはN+1問題を解決するためにpreloadというメソッドがありますが、それを使用しているためにインデックスが使えなくなっていることがわかりました。
ここで安易にインデックスを追加するのではなく、APIの意図やコードを確認することは大変重要です。 なぜかというと、インデックスを追加するとINSERTやUPDATEの処理の際にインデックスの更新も行われるため、パフォーマンスが悪化することもあるからです。 パフォーマンスチューニングはしばしばこのようなトレードオフが発生するので、トレードオフが発生しないような方法を選択するか、そのバランスを取ることが重要です。
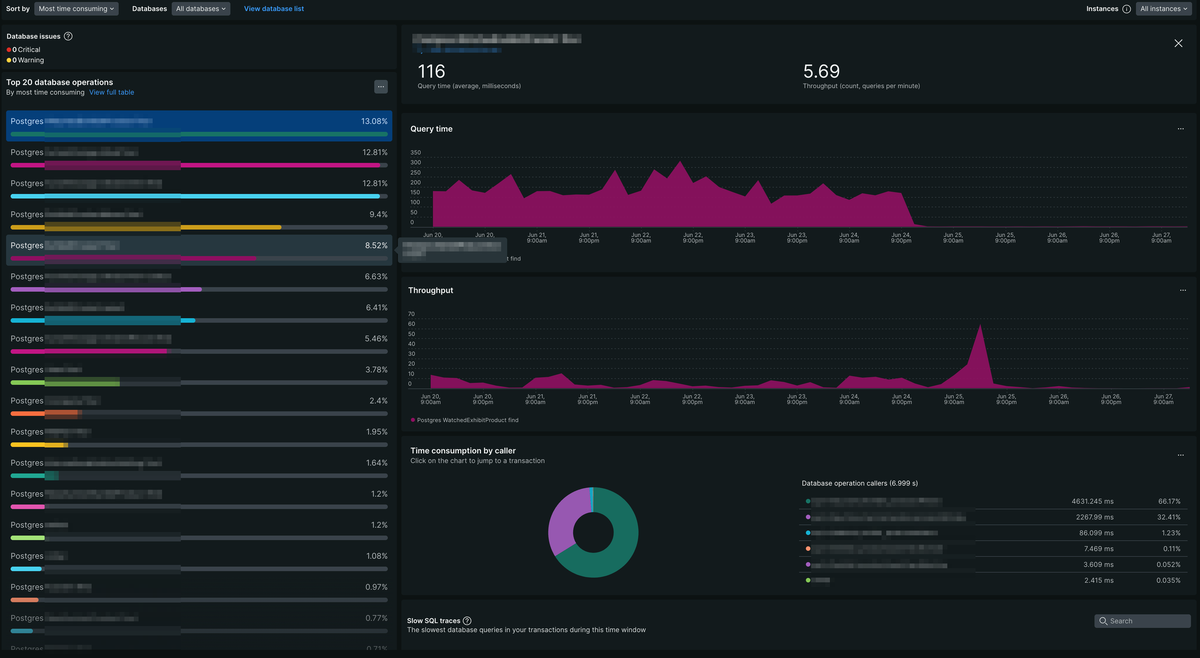
インデックスを使えるようにpreloadを使わないコードへ修正すると、クエリの実行時間は100分の1以下になりました。
items = AuctionItem.where(auction_id: @params[:auction_id])
.order(:line_number)
.page(params[:page]).per(params[:per_page])
.with_attached_images
.preload(bids: :user)
- .preload(:watched_auction_items)
- .preload(:auction_item_memos)
+ # WatchedAuctionItemとAuctionItemMemoはpreloadだとインデックスが使えずパフォーマンスが悪いため、別で取得する
+ watched_auction_items = WatchedAuctionItem.where(auction_item_id: items.map(&:id), user_id: current_user.id)
+ auction_item_memos = AuctionItemMemo.where(auction_item_id: items.map(&:id), user_id: current_user.id)
APMのDatabasesを見ると、クエリの実行時間が大幅に短縮されていることが分かります。
3. CloudFrontの導入
次にTotal timeが大きかったTransactionは、Controller/active_storage/representations/redirect#showというものでした。
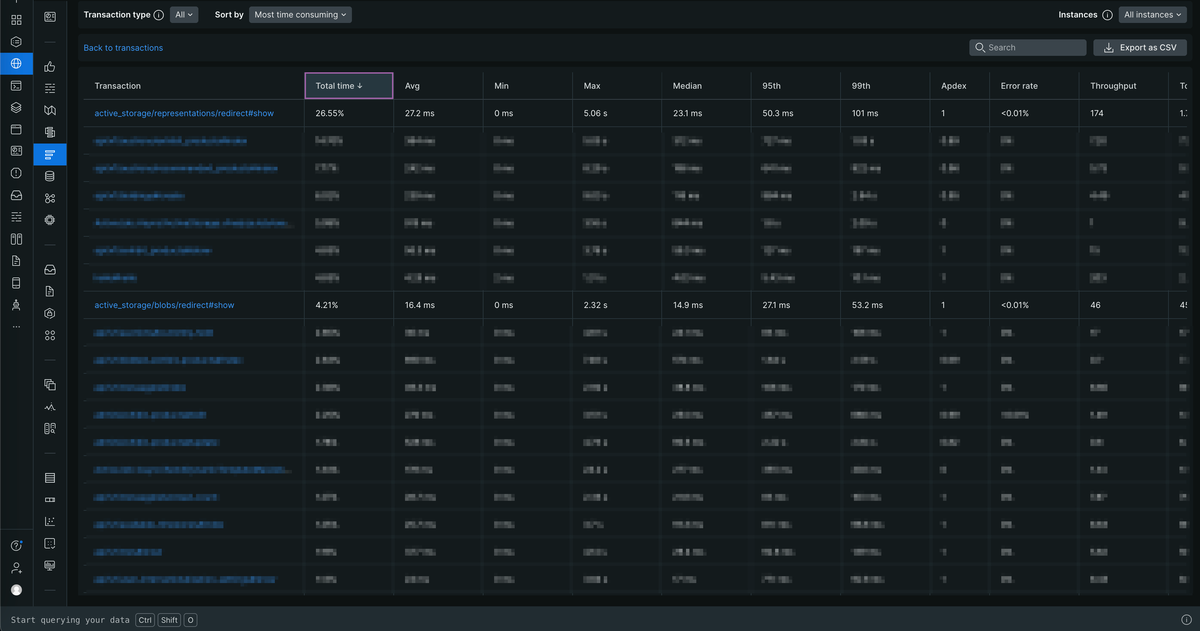
RailsにはActive Storageという、アプリケーション内でファイルアップロードと添付ファイルの管理を簡単に行うためのライブラリがあります。
オークションではActive Storageの機能を使用して、商品画像をAWS S3に保存したりクライアントに表示したりしています。
表示するロジックは、一旦Railsサーバーにリクエストを飛ばし認証した上でS3の署名付きURLにリダイレクトさせるというものです。
そのリダイレクト処理が、Controller/active_storage/blobs/redirect#showも合わせるとTransactions全体の3割近くを占めていました。
ひとつひとつのレスポンスタイムは短かったのですが、リクエスト数が大変多いため、Total timeが大きくなっていました。
CloudFrontを導入し、リダイレクトでの署名付きURL認証ではなく、Cookie認証でクライアントからCloudFrontに直接ファイルを取得しにいくことで、Railsサーバーの負荷軽減に成功しました。
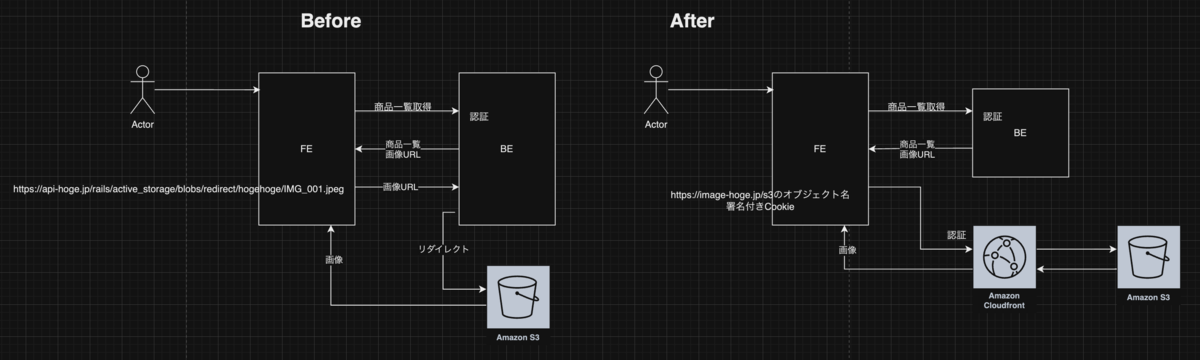
結果、Active Storageのリダイレクトがほぼゼロになることで、3割の負荷が削減され、全体のリクエスト数も4割ほど減りました。
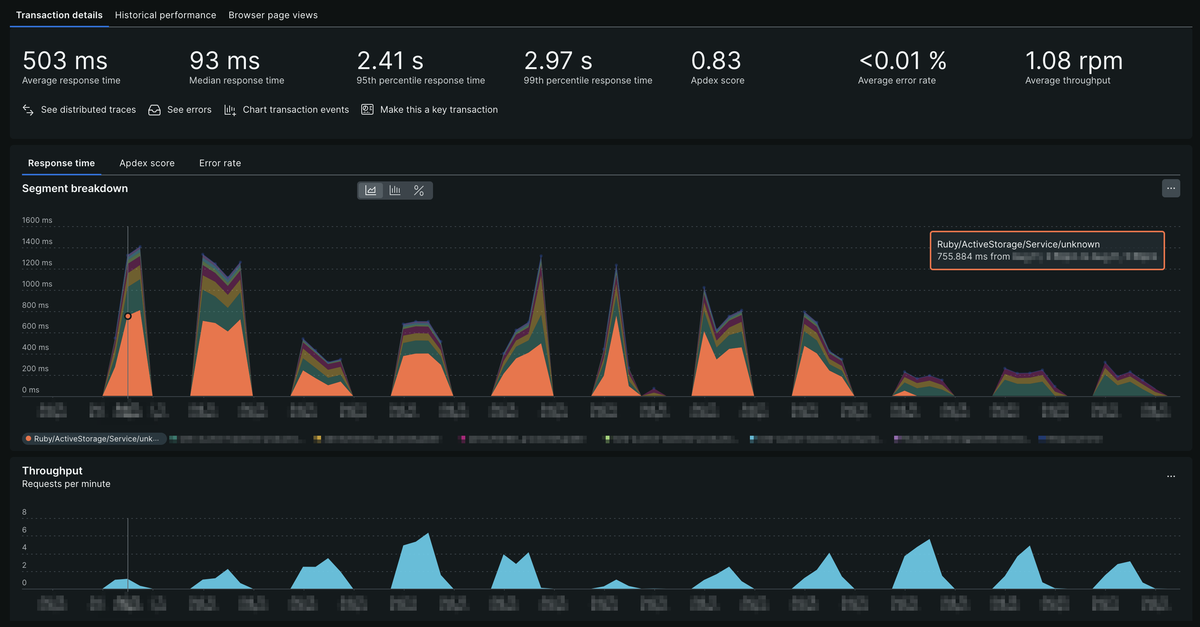
4. 重い処理の非同期化
次にTotal timeが大きかったTransactionを確認すると、Response timeが長くかつ不安定な処理でした。 Transactionを確認してその原因を探ると、画像を登録した後にそのサムネイル画像を生成していることがわかりました。 画像のリサイズは重い処理となることが多いため、非同期化やCDNを使うことで負荷を軽減できます。 RailsにはSidekiqという非同期処理用のバックグラウンドジョブライブラリがあるので、オークションではそれを使用してコンテナを分けて画像のリサイズを非同期化しました。 簡単に処理するコンテナを分けることができるので、実装コストに対して効果が大きかったです。
全体的な効果
これらの改善の結果、ECSやRDSのCPU使用率が大幅に下がり、それぞれのTransactionのレスポンスタイムが向上しました。 また、ECSのコンテナ数やRDSのリードレプリカのインスタンス数を減らすことができ、インフラコストも削減できました。
ビジネス的な側面でも、RDSにかなりの余裕ができたことで検索や入札のリクエストを素早く捌けるようになり、ユーザー体験が向上しました。
個人的な学び
今回の取り組みから、パフォーマンスチューニングは気軽に行うことができるものもあり、その効果も大きいということがわかりました。 また、「推測するな、計測せよ」という言葉の通り、計測することでボトルネックを容易に特定できます。 計測してみたら、意外と簡単に改善できることもあるので、積極的に取り組んでいきたいです。 計測の方法については、New Relicなどのツールを使うと圧倒的に楽になるのでおすすめです。
ボトルネックの解消方法は、いままでに自分の経験してきた範囲だと、以下のようなものが多かったです。
- リクエスト数が多いAPIの削減
- SQLクエリの最適化
- インデックスの追加
- インデックスの使われ方の最適化
- CDNなどのキャッシュ機能の導入
- 重い処理の非同期化
これらの方法は、しばしばトレードオフが発生するので、そのバランスを取ることが重要であることも学びました。
今後の課題
現状では、DBのロック待ちが発生しているので、その解消が課題です。 オークションでは一部に悲観ロックを使用しているため、トランザクションが長くなるとロック待ちが発生しやすくなっています。 そのため、トランザクションを短くするためのリファクタリングや、ロックの範囲を狭めるなどの対応が必要です。 これは間違えてしまうとデータの整合性が取れなくなるため、特に慎重に対応していく必要があります。
まとめ
パフォーマンス改善は継続して行っていく必要があり終わりはありませんが、仕組みや目標を作るとやりやすくなります。 オークションチームでの仕組みは、月に1度負荷の振り返りをチームで行い、New RelicのAPM、主にTransactionsを見てTotal timeが大きいものから順に改善していくというものです。 また目標として、同じインフラ構成でCPU使用率を30%まで抑えることなどが考えられます。 New RelicはAPMのTransactionsを見るとボトルネックがよくわかり、そのTransactionを深掘りしていくことで改善方針も簡単に立てられるのでおすすめです。 パフォーマンス改善は、ユーザー体験の向上やインフラコストの削減につながるので、これからも取り組んでいきます。
最後に、バイセルではエンジニアを随時募集しています。 興味のある方はぜひ以下の採用サイトをご覧ください。