

はじめに
こちらは バイセルテクノロジーズ Advent Calendar 2022 の 4 日目の記事です。前日の記事は尾沼さんの「リファイメントとプランニングを改善することで、チームの属人化が解消された話」でした。
こんにちは。バイセルテクノロジーズ テクノロジー戦略本部 開発 2 部の小松山です。
私が関わっているプロジェクトでは、一部のバッチ処理の実行環境として Cloud Run ジョブを採用しています。Cloud Run ジョブは2022 年 5 月にリリースされた比較的新しいサービスで、記事執筆時点ではプレビュー版として提供されています。サービスの解説記事や試してみた系の記事は散見されるものの、具体的な採用事例の紹介が少ないです。本記事では Cloud Run ジョブの採用事例として、採用に至った背景やその実装内容を紹介します。
普段から GCP を使う方、特にバッチ処理のアーキテクチャを検討している方の参考になれば幸いです。
背景
実現したいこと
私のチームでは夜間に回すバッチ処理の実装を検討していました。実現したかった要件は下記のとおりです。
- 大量の画像 (数千枚~6 万枚程度) をある GCS バケットから別のバケットへ移動させたい
- 対象となる画像ファイルは 1 週間に一度追加される。増加量は数千〜6 万程度の範囲
- 移動にそこまでパフォーマンスは求められない。夜間〜早朝の間に移動が完了していれば問題ない
- 移動後のバケット内の画像のパスをデータベースに保存したい
Cloud Functions はタイムアウト上限が短い
プロジェクトではすでにバッチ処理がいくつか実装されていましたが、それらはすべて Cloud Functions で実装されていました。ですが、Cloud Functions はタイムアウト時間の上限が短いため、大量のデータを扱いたい今回のユースケースには合わないのではないかという懸念がありました (第 2 世代で HTTP トリガーの関数の場合は上限 60 分、それ以外は 9 分)。 各言語に備わった並行処理機能などを駆使して無理やり Cloud Functions のタイムアウト上限内に収めるやり方も可能かもしれませんが、今回は見送りました。そもそも可能か怪しいという点に加え、処理の複雑度が上がることによるコードの難読化や問題発生時の調査のしづらさ、タイムアウト時間ギリギリになると処理対象のデータ量の増加に耐えられない可能性などを考慮しての判断でした。
他に適したサービスはないものかと調査・検討した結果「Cloud Run ジョブ」が結構使えそうな感じがしたので使ってみることにしました。
Cloud Run ジョブについて
サービス概要
Cloud Run ジョブはサーバレスなコンテナ実行環境です。従来の「Cloud Run サービス」と大きく違う点は処理のトリガーが HTTP リクエストではない点、1 つのジョブを複数のタスクに分割できる点です。ジョブは任意のタイミングでトリガーすることができます。Cloud Scheduler と組み合わせれば定期実行することも可能です。また、Cloud Run サービス同様 VPC コネクタを経由することで VPC 内のリソースにもアクセス可能です。
詳細
実装について紹介するための前提知識として、Cloud Run ジョブについてもう少し詳細な説明をします。
まずは Cloud Run ジョブの「ジョブ」と「タスク」に関してです。「ジョブ」はリージョンに紐付く Cloud Run ジョブのルートリソースです。コンテナイメージ、マシンスペック、環境変数、VPC コネクタの設定など、従来の Cloud Run サービスの「サービス」に対して設定していた項目はだいたい同じように設定ができます。他にもジョブは最大同時並列数、分割するタスク数などが設定可能です。より細かなオプションについてはこちらをご覧ください。
「タスク」は実際に稼働するコンテナインスタンスです。ジョブ : タスク = 1 : N の関係になります。ジョブが実行されるとタスクの分割数にしていした数だけコンテナインスタンスが立ち上がり、処理が行われます。複数のタスクに分割する設定をしている場合、並列数の上限を設定していないと制限なく並列で実行されます。タイムアウト上限はタスクに対して決められており、デフォルトで 10 分、上限は 60 分です。
ジョブに対してのタイムアウトは無いそうです。ジョブのタスク分割数の上限が 10000 なので、タスクのタイムアウト上限と組み合わせて単純計算すると、10000 ☓ 60 = 600000 分 (= 約 1 年) ほどになります。これだけ時間があれば大抵の処理はカバーできそうですね。
サービスに関してのより詳細な点に関してはこちらの記事や公式ドキュメントをご覧ください。
※ 本記事の執筆時点での仕様です。現状プレビュー版での提供のため、仕様の変更が加わる可能性があります。
実装
上記で紹介した Cloud Run ジョブの特性が今回やりたいバッチ処理を実装するのに適していそうだと判断し、Cloud Run ジョブの採用を決めました。ここではその実装内容を軽く紹介したいと思います。
インフラ
まずはインフラレベルでの紹介です。簡易的なシステム構成は下図の通りです。
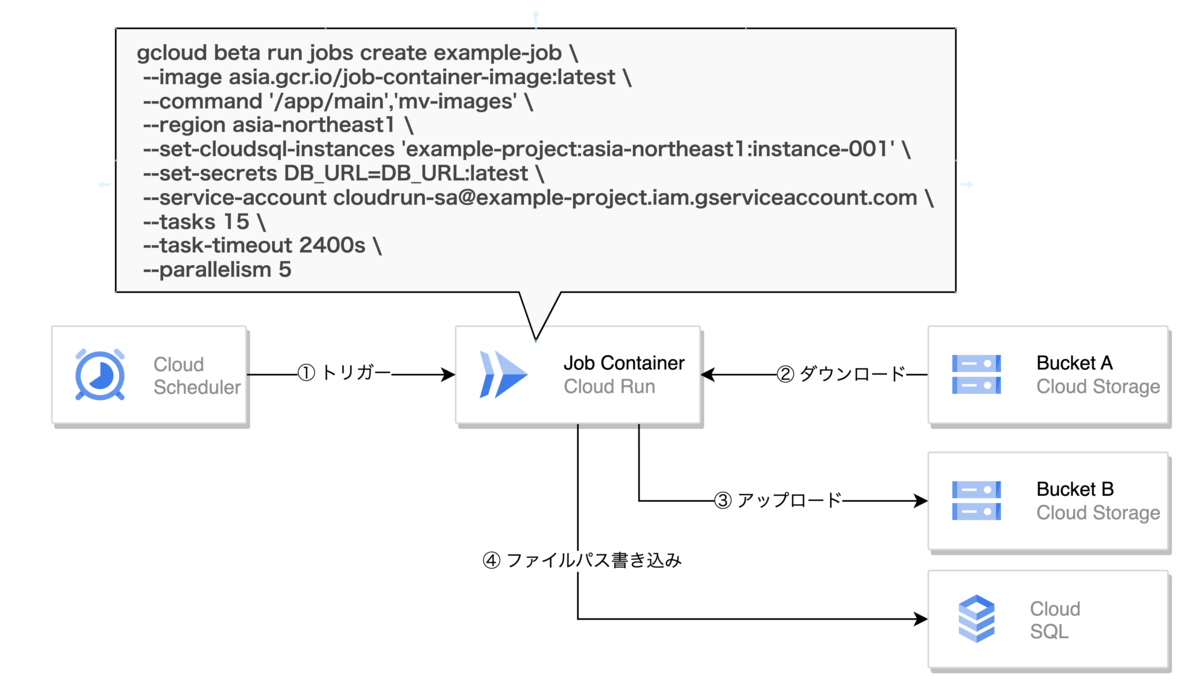
Cloud Scheduler を Cloud Run ジョブのトリガーとします。負荷時を避けるために実行時間は夜間にしました。ジョブ内では GCS バケット A にある画像をパスなどを加工してバケット B へ移動させます。画像を移動させた後は、移動後のバケット B 内の画像のパスを Cloud SQL へ保存します。
ジョブを分割しないとデータ量的に タイムアウト上限の 60 分を越してしまうため、タスクを 15 分割しました。また、ジョブコンテナが Cloud SQL への接続数を逼迫しないよう、並列数の上限値を設定しました。
アプリケーション
次にアプリケーションレベルでのバッチ処理の実装の紹介をします。
私のプロジェクトではバックエンドの使用言語はほとんどが Go のため、そのまま Go を採用しました。バッチ処理本体は CLI アプリケーションとして実装しました。CLI とすることで後々別のバッチ処理を Cloud Run ジョブで実装する場合に、今回実装したコードを再利用しやすいというメリットがあるためです。
簡易的なディレクトリ構成を下記に示します。実際はテストファイルやモックがあったり、internal/ 配下にもっとファイルがあったりしますがわかりやすさのために省略しました。
$ tree . ├── commands # コマンドの実装 │ ├── mv_images.go │ └── root.go ├── Dockerfile ├── go.mod ├── go.sum ├── internal # ビジネスロジック │ └── services │ └── move_images.go ├── main.go ├── pkg │ ├── gcs # GCS クライアントライブラリのラップ │ │ └── gcs.go │ └── postgres # DB 接続処理 │ └── postgres.go
CLI の実装には spf13/cobra を使用しています。
commands パッケージでサブコマンドを実装するようにしています。今回実装したバッチ処理は commands/mv_images.go に書かれたサブコマンドの処理として実装しています。
package commands // commands/mv_images.go import ( "batch-job/internal/services" "batch-job/pkg/env" "batch-job/pkg/gcs" "batch-job/pkg/postgres" "github.com/spf13/cobra" ) var mvImagesCmd = &cobra.Command{ Use: "move-images", RunE: func(cmd *cobra.Command, args []string) error { // エラーハンドリングは省略 db, _ := postgres.Open() defer postgres.Close() gcsC, _ := gcs.NewGCSClient() service := services.NewMoveImageService( db, gcsC, "bucketA", "bucketB", // これらの値を使ってよしなに処理を分割する os.Getenv("CLOUD_RUN_TASK_INDEX"), os.Getenv("CLOUD_RUN_TASK_COUNT"), ) return service.Run() }, }
各タスクのコンテナインスタンスには、タスクのインデックス番号とジョブが実行するタスクの数が環境変数として展開されています (参考)。それが CLOUD_RUN_TASK_INDEX と CLOUD_RUN_TASK_COUNT です。これらの値を読み取って、処理対象のデータをよしなに分割するように実装することでジョブが担う処理をタスク内で分割することができます。
別のバッチ処理を作る際は新たに commands 配下にサブコマンドを実装します。複数のバッチ処理をサブコマンドを分けて実装することで汎用処理や共通のロジックを使い回せるようになっています。
Dockerfile に指定したコンテナ実行のエントリポイントはジョブの作成時に上書きすることができます。Dockerfile には下記のように CMD に記述しておき、
FROM golang:1.19-buster as builder
WORKDIR /app
COPY . ./
RUN go mod download
RUN go build -v -o main
FROM debian:buster-slim
RUN set -x && apt-get update && DEBIAN_FRONTEND=noninteractive apt-get install -y \
ca-certificates && \
rm -rf /var/lib/apt/lists/*
COPY --from=builder /app/main /app/main
CMD ["/app/main", "--help"]
ジョブの作成時に --command オプションでエントリポイントを上書きすることで Dockerfile も複数ジョブで使い回すことができます。
$ gcloud beta run jobs create example-job \ --image asia.gcr.io/job-container-image:latest \ --command '/app/main','mv-images' \ --region asia-northeast1 \ --set-cloudsql-instances 'example-project:asia-northeast1:instance-001' \ --set-secrets DB_URL=DB_URL:latest \ --service-account cloudrun-sa@example-project.iam.gserviceaccount.com \ --tasks 15 \ --task-timeout 2400s \ --parallelism 5
実装してみて
良いと思った点
基本的なところは従来の Cloud Run サービスと使い心地は変わらないため、Cloud Run にある程度精通している人であればすぐに使いこなせそうな印象でした。
これまでバッチ処理の実行環境としていた Cloud Functions より、タイムアウト上限が長いという点で Cloud Run ジョブが優位なことは前述のとおりですが、実装してみて感じたのは実装の自由度の高さです。Cloud Functions ではサポートされたランタイムしか選択することができませんが、Cloud Run にはその制限がありません。手元で作ったコンテナをそのままデプロイして動かせる Cloud Run の手軽さを残しつつ、タスクの分割や並列実行など、ジョブらしい機能が加わった素晴らしいサービスだと思いました!
惜しいと思った点
また、Cloud Functions と比べてちょっと惜しいなと思った点も 2 つほど挙げておきます。
1 つ目はトリガーオプションの少なさです。記事執筆時点で提供されている Cloud Run ジョブの実行方法は「コンソールからの実行」「gcloud beta jobs execute の実行」「REST API を叩く」の 3 通りのみです。それに対して Cloud Functions では Cloud Storage トリガー、Pub/Sub トリガー、Firestore トリガー、Eventarc トリガーなど豊富なオプションがサポートされています。個人的には Cloud Run ジョブも Pub/Sub トリガーをサポートしてくれると嬉しいなと思ってます。
2 つ目は Terraform に書き起こせないことです。terraform-provider-google にサポートリクエストが上がっているものの、対応はまだのようです。これは対応されるのを願って待つのみですね。
上記で挙げたポイント以外にもコールドスタート時間や料金の差なども他のサービスとの比較の材料になるかと思います。
まとめ
これまでは「GCP でバッチ処理を動かすならこれ!」みたいなサービスが少なく、私たちのチームのように Cloud Functions をバッチ的に使っているケースは少なくないと思っています。Cloud Run ジョブがバッチ処理に適した実行環境を提供してくれるようになったことで技術選定の幅が広がりました。技術選定の際には選択肢の 1 つとして挙げていただければ嬉しいです。
バイセルテクノロジーズではエンジニアを募集しています。
明日の バイセルテクノロジーズ Advent Calendar 2022 は玉利さんによる「Reactのchildrenを使用してコンポーネントを拡張した話」です。