

はじめに
こんにちは、テクノロジー戦略本部 買取1グループでバックエンドエンジニアをしているメントス (@m_t_tion1) です。
現在は、リユースプラットフォームCosmosの出張訪問買取アプリケーションVisitと、Visitを支える買取基盤バックエンドサービスDealの開発・運用に従事しています。
本記事では、宮川 (@kurogenki0522) が執筆した前編に引き続き、後編として負荷試験の評価部分をAgent Skillsで民主化する試みと、それを通じての学びを紹介します。
以下は本記事では深く触れません。気になった方はぜひ前編をご覧ください!
- 負荷試験の民主化が必要になっている背景
- 計画と評価のアーキテクチャの全体設計
- 計画の詳細設計と成果
今までの負荷試験評価の手順
私たちが実施している評価の手順は、大きく二つで構成されています。
- 負荷試験結果レポート作成
- 計画内容とレポートを元に、結果の妥当性とリリースの可否を判断
Step 1: 負荷試験結果レポート作成
負荷試験では多くの場合、1つのシナリオにつき、複数のメトリクスを各種リソースから取得する必要があります。
メトリクスの詳細を見るために都度リソースにアクセスするのは、実施者とレビュアーの双方に負担がかかるため、
- 全メトリクスを一度に確認できるようにする
- 結果をスナップショットとして残し、将来の計画や、結果の振り返り・比較に活かす
という目的でレポートを作成していました。
レポートの作成は負荷試験実施者が主に行います。
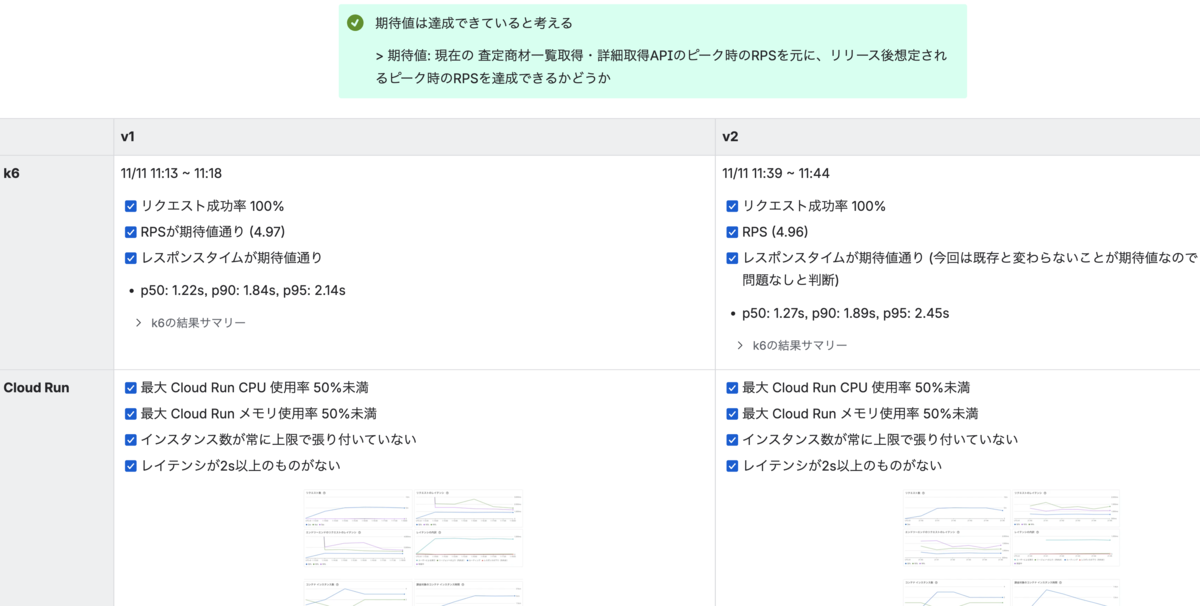
まず、負荷試験の実施後にk6とGoogle Cloudから、以下のメトリクスを取得します。
| リソース | 取得対象 |
|---|---|
| k6 | ・リクエストの成功率 ・RPS ・パーセンタイルごとのレスポンスタイム (p50, p90, p95) |
| Google Cloud | ・インフラのメトリクス (ex. Cloud Run / Cloud SQL の CPU使用率・メモリ使用率・接続数) |
そして、取得したメトリクスをレポートに転記します。中でもインフラのメトリクスは負荷の推移を可視化する目的で、Google Cloudコンソールのスクリーンショットを取得して添付しています。
次に、取得したメトリクスが計画時に決めた期待値を満たしているかを確認します。 もし満たしていない場合は、追加で原因の考察と次回実施に向けた改善のアクションを決めて、レポートに追記します。
Step 2: 結果の妥当性とリリースの可否を判断
Step 1で作成したレポートと元々の計画内容を元に、結果の妥当性、原因の考察、次回実施に向けた改善アクションについてチーム全体で議論します。 そして、最終的にリリースの可否と次のアクションを決定します。
このサイクルをリリース可能な状態になるまで繰り返すことで、システムのパフォーマンスを担保しています。
今までの負荷試験評価の課題
今までの評価の手順では、人依存になっている部分があり、
- レポート作成に必要なデータの手動での取得が手間
- 負荷試験の経験が少ない人の場合、原因の考察と次回実施に向けた改善アクションの策定に時間がかかってしまう
という二つの課題がありました。 特に課題2は、ボトルネックの分析方法とアクションをまとめる粒度がチームでルール化されていなかったことが根本の原因で、経験の少ない人は手探りで進めるため時間がかかっていました。
しかし評価手順には課題があるものの、都度レポートがまとまっているので過去実施のものも含めて見返すことができ、チームでの意思決定の際の判断材料として機能していました。 それに加えて、各担当者が負荷試験の実施だけで終わらず、一貫して結果分析を行うことで、パフォーマンスチューニングに関する知識を実践を通じて学べる機会になっていました。
そのため、評価手順の大枠は変更せず、これらの課題の解決に取り組むのが先決と考え、改善に取り組みました。「誰でも同じ品質で、負荷試験を計画から評価まで実施できる」という民主化された状態を達成するための、最初のスコープに位置づけています。
Agent Skillsによるアプローチ
結論として、計画と同様に評価用のAgent Skills1を作成し解決を試みました。
課題1に関しては、実際の作業は、「関連メトリクスを取得し、それを自然言語とスクリーンショットでまとめる」という定型化した処理として扱うことができます。
また、課題2に関しては、普段実施している分析方法を明文化すると、
- New Relic APMから、リクエスト処理のどこにボトルネックがあるかを特定 (ex. DB/アプリケーションロジック/外部APIコール)
- 特定したボトルネックの処理とインフラメトリクスを確認して、課題を把握し改善策を考える
という流れで実施していました。
つまり、課題2も1同様に定型化した処理として扱えるため、Agent Skillsとして明文化することで二つの課題を解決できると考えました。
負荷試験評価Agent Skillsの処理概要と構成
Agent Skillsの処理の流れを説明します。
はじめに、メインエージェントにユーザーの入力と計画の内容を入力し、k6のCSVからスクリプトでメトリクスを取得します。 その後、複数のサブエージェントを並行起動して以下のデータを取得します。
- Cloud Monitoring API v3からインフラメトリクスを取得
- playwright-cli2を用いてスクリーンショットを取得
両方の取得が完了したら結果のレポートを作成し、sre-reviewerのサブエージェントに、計画で決めた期待値と比較した結果 (Pass/Fail) の判定と、次のアクションを三段階に分類してもらいます。 特にMUST/SHOULDに関しては、リリース判断の際、リリース前に必ず対処しなければいけないかを常に考えていたので、期待値を達成できているか否かで線引きをしました。
| 分類 | 内容 |
|---|---|
| MUST | 期待値を達成できていないため、リリース前に対処必須 |
| SHOULD | 期待値は達成できているが、今後のユーザー数増加で影響しうる (想定トラフィックx2で問題化の可能性があるかを推測) |
| NICE_TO_HAVE | 軽微な改善ポイント (ex. ログ改善) |
そして、MUST/SHOULDと判定された項目がある場合のみ、bottleneck-analyzerのサブエージェントを起動してボトルネック分析を行い、原因と改善アクションを結果レポートに追記します。
そして前編同様、最終的な結果の妥当性は人間が判断する設計にしています。
次に構成に関して説明します。
.claude/
├── agents/
│ ├── load-test-evaluation-bottleneck-analyzer.md # New Relic APMとGoogle Cloudのメトリクスから、ボトルネックがどこにあるかを特定するサブエージェント
│ ├── load-test-evaluation-metrics-collector.md # Google Cloudのインフラメトリクスを取得するサブエージェント
│ ├── load-test-evaluation-screenshot-collector.md # Google Cloudコンソールのスクリーンショットを取得するサブエージェント
│ └── load-test-evaluation-sre-reviewer.md # 結果を Pass/Fail 判定し、次のアクションを三段階(MUST/SHOULD/NICE_TO_HAVE)で提案するサブエージェント
└── skills/
└── load-test-evaluation/
├── SKILL.md # 負荷試験評価のAgent Skillsの中身
├── assets/
│ └── result.md # 結果レポートのテンプレート
├── references/
│ ├── bottleneck-analysis.md # DB/アプリケーション/インフラにおけるボトルネック調査手順
│ ├── google-cloud-monitoring-queries.md # Cloud Monitoring APIからメトリクスを取得するためのcurlコマンド一覧
│ └── google-cloud-console-screenshots.md # playwright-cliを用いたブラウザ上でのGoogle Cloudコンソールのスクリーンショット取得の操作手順
└── scripts/
├── fetch_metrics.sh # Google Cloudのインフラメトリクス取得スクリプト
└── summarize_k6_csv.py # k6の実行結果取得スクリプト
計画と評価のAgent Skillsを作成する中で、様々な構成を試した結果、以下の3点を意識した構成が現状では一番安定しています。
- メインエージェントが複数の異なるコンテキストの作業を抱えている場合、専門分野ごとにサブエージェントへ委譲する
- ルールベースで処理できる箇所はエージェントに推論させず、スクリプトで処理する
- 各サブエージェントが必要とするドキュメントを
references/に分け、必要なものだけを読ませる
そこに至るまでの試行錯誤の過程を紹介します。
最初はメインエージェントに一連の作業を任せました。その結果
- playwright-cliを使ったスクリーンショット取得の一連の処理がコンテキストを圧迫し、途中でcompactが走り、後続処理の精度が低下 (特にボトルネック分析が仮説で終わり、実データに当たらないまま結論を出してしまうケースが発生)
- 全て直列で作業をしていたので、人手より速いとはいえ実用上は時間がかかった
- k6のCSVフォーマットは毎回同じはずなのに、都度中身を確認してパース用スクリプトを書き起こしていた
という課題が見つかりました。
課題1, 2に関しては、エージェントの構成の変更とそれに伴う作業ごとのリファレンスの分割、 課題3に関しては、自然言語で指示するのではなく最初からパース用のスクリプトを用意することで対応できると考えました。
その結果、冒頭で説明した通りの構成に落ち着き、課題を解決することができ、出力も安定するようになりました。
よかった点
誰でも手軽に同じ品質で回せる状態に近づいた
現在、今回作成したAgent Skillsを運用しています。 今まで繰り返し行っていた定型的な作業をエージェントに任せられるようになりました。
その結果、本来集中すべき計画の妥当性レビューと、評価結果のレビューに実施者が時間を割けるようになりました。
また、評価結果のレビューに関しては、エージェントがまとめてくれたメトリクスベースの一次分析を起点に、経験の浅いメンバーでも改善アクションをコンスタントに提案できるようになりました。
今後運用していく上で、課題は出てくると思いますが、このように現状の運用では「誰でも同じ品質で、負荷試験を計画から評価まで実施できる」という民主化に一歩近づいたのではないかと考えています。
今後の展望
結果から再計画までのフィードバックループの検討
結果がFailだった場合、計画用のAgent Skillsを再度実行して次の試験計画を立て、期待性能を満たすまで計画-実行-評価を繰り返すフィードバックループを実現できる可能性があります。 しかし今回は、Pass/Failの基準自体が妥当かの判断は人間がすべきとし、フィードバックループの作成は見送りました。
今後、評価の妥当性がモデルの性能向上や構成の見直しによって検証できた場合は、ぜひ検討しようと考えています。
組織全体に展開する方式の検討
現時点では、全サービスが使えるようにAgent Skillsを拡張するのではなく、必要最小限の構成だけ用意して、各チームに配布しあとは自由にカスタマイズする方法のほうが、運用面でメリットが多いと考えています。
例えば今の構成だと、複数のサービスで使おうとすると、サービス固有のインフラ情報やそれに伴うインフラメトリクスの取得方法を追加する必要があります。 このように、利用するサービスが今後増え続けると、機能面ならびに運用面で考慮することが増え、全サービスが使えるように拡張を続けていくのは負荷が高いと考えています。
この点に関してはまだ正解が見つかっていないので、今後も模索していきます。
今回の取り組みを経て学んだこと
「実際に作って学ぶ」という価値
ここまで読んで気づかれた方もいるかもしれませんが、最終的には計画・評価ともに、Anthropic公式が示すAgent Skillsのベストプラクティスの考え方に準拠した構成になりました。
しかし、自分の手で試行錯誤する中で、なぜこれがベストプラクティスなのかを身をもって知ることができました。 そして、今後のエージェント開発で幅広く活かせる視点を獲得できたので、非常に価値がありました。
エージェントを作業に組み込めるようになった今だからこそ、改めて「とにかくまず触って動かしてみる」ことを大切にしたいと感じています。 自ら実践する時間を今後も意図的に確保し続け、知識をアップデートし続けることが重要です。
オブザーバビリティエンジニアリングの重要性
今回エージェントによるボトルネック分析にNew Relic APMを活用しましたが、 それができたのは今までプロダクトにAPMを導入し計装されていたからに他なりません。
もし今回APMが導入されていなければ、Google Cloudのインフラメトリクスから分析するしかない状況でした。 そのため、DB/アプリケーションロジック/外部APIコールなど、様々なレイヤーを跨ぐ分析時には、エージェントの仮説による推論に依存してしまい、精度に影響することが考えられます。
今回のAgent Skillsで作成した計画と評価レポートでも、エージェントがNew Relic APMから取得したメトリクスとGoogle Cloudから取得したインフラメトリクスを組み合わせて、妥当性のある判断をしていることが確認できました。
今までの監視やパフォーマンスチューニングの用途でもAPMは重宝してきましたが、作業をエージェントに委譲することを考えると、導入の重要性がもう一段高くなったと感じています。
ドキュメンテーションに向き合う
これまでの開発現場でも、体系化されたルールや手順がドキュメント化されていて、それを最新の状態に保つことは、開発組織にとって有益であると考えられてきました。
振り返ってみると、実際は「書き忘れた」「ドキュメントが散在しておりどこにあるかわからない」「最新の状態に追従するのが面倒」などの理由で、達成できていないことは多くあります。 また、プロジェクトなどに比べると優先度が上がりにくく、先送りにされるケースも少なくありません。
しかし今は、今回のように「Agent Skillsを通じてエージェントに作業を任せ、成果物が出る」というわかりやすく目に見える形で、ドキュメントの効果が現れるようになりました。
だからこそ、先送りせず一歩立ち止まってチーム・組織でのドキュメンテーションのあり方について向き合う必要があると感じました。
最後に
以上、Agent Skillsによる負荷試験の民主化への歩みと学びということで、前編・後編でお送りしました。
Agent Skillsの実運用の話に加えて、「これまで重要と言われてきたことに、AI時代になって明確に向き合う価値がより生まれた」ことを実感した話として読んでいただけたら嬉しいです。
バイセルでは、一緒に働くエンジニアを募集しています。興味がある方は、以下よりご応募ください。
- 実行環境はClaude Codeを前提としています。↩
- playwright-mcp, agent-browserも候補に上がったが、組織がE2EテストでメインにPlaywrightを採用しているのに加え、トークン量は可能な限り削減したかったこともあり、playwright-cliを採用しました。↩