

注意
- この記事はあくまで私が携わっているプロダクトから得た知見によって生まれた選択肢の提示であり、全てのアプリケーションにおいて最適なアーキテクチャではありません。その点ご理解ください。
- アプリケーション全体のアーキテクチャの話ではなく、
componentsフォルダの内部をどのように責務分割するかのアーキテクチャ設計パターンの話になりますので、その点ご認識ください。
はじめに
この記事を読むメリット
- コンポーネントの責務の分解による疎結合性を意識したコンポーネント設計パターンを知れる
- 実装時に迷わず、AIにも理解しやすい
componentsフォルダを自然に作れるようになる
自己紹介
株式会社BuySell Technologies(以下バイセル)の@ShiShiです。 React/Next.jsを中心にフロントエンド開発をしたり、Golangでバックエンド開発をしたりしています。
業務では、バイセルの基幹システムプラットフォームであるCosmosの中にあるCRMというアプリケーションのフロントエンド開発をメインに行っています。
1. CRMのアーキテクチャとその問題と課題
いかなるアプリケーションにおいても、アーキテクチャは常に重要なテーマとなります。
CRMもその例に漏れず、bulletproof & container/presentationalパターンを掛け合わせたアーキテクチャが採用されています。
そのおかげもあり、上位レイヤーは丁寧に設計されており見通しが良いです。
CRMのsrc/配下の構造のダミー
src/ ├── api/ ├── atoms/ # jotaiを使った状態のインスタンスを管理 ├── constants/ ├── features/ │ └── hogeFeature/ │ │ ├── atoms/ │ │ ├── components/ # featureに紐づいたコンポーネントを管理。コンポーネントをどのように責務分割するかは自由 │ │ │ ├── HogeComponent/ │ │ │ │ ├── container.tsx │ │ │ │ ├── container.test.tsx │ │ │ │ └── container.stories.tsx │ │ │ └── HugaComponent/ │ │ │ ├── HegoComponent/ │ │ │ │ ├── HagiComponent/... │ │ │ │ ├── container.tsx │ │ │ │ ├── container.test.tsx │ │ │ │ └── container.stories.tsx │ │ │ ├── HiguComponent/... │ │ │ ├── container.tsx │ │ │ ├── container.test.tsx │ │ │ └── container.stories.tsx │ │ ├── constants/ │ │ ├── hooks/ │ │ ├── mappers/ │ │ ├── schemas/ │ │ ├── types/ │ │ ├── util/ │ │ ├── container.tsx │ │ ├── container.test.tsx │ │ └── container.stories.tsx │ └── hugaFeature/... ├── hooks/ ├── lib/ # サードパーティ・外部ライブラリのインスタンス処理など ├── mappers/ ├── pages/ # ページごとに条件に従って`screens/`を出し分け ├── schemas/ ├── screens/ # `features/`のコンポーネントをimportしてそのまま表示 ├── types/ ├── ui/ # MUIをラップしたプロダクト独自の純粋UIを管理 │ ├── HogeComponent/ │ │ ├── presenter.tsx or index.tsx(混在) # MUIコンポーネントをStyledでラップした純粋UI表現を担当 │ │ └── presenter.stories.tsx # or index.stories.tsx │ └── HugaComponent/ └── util/
しかしそのドメイン・機能は複雑で、実際にフォルダを潜っていくとその幾重にもなるネスト構造に難易度の高さを感じることになります。 何よりも重要なのはこのシステムが複数人によって数ヶ月で開発されたことであり、スピード開発と引き換えにさまざまなトレードオフがあったことがコードから伺えます。
- 実装方法の統一について
- 「
React-Hook-Form/useReducer/useStateの使い分けや、Orval×Tanstack-Queryの実装方法、コンポーネントの切り出し方はその場その場の判断に委ねる。テストが通っていればOK」
- 「
- 設計パターンのトレードオフ
- 「container/presenterパターンは時間がかかるので、一旦全てcontainerで実装しよう」
- テスト戦略の簡略化
- 「
container.test.tsxでロジックとUIを両方テストしているから、storybookはchromatic向けのdefault表示確認だけでいい」
- 「
- ドキュメント整備の後回し
- 「コードルール改正する暇がないから、一旦チーム内で口頭共有できていればいい」
etc...
まず前提として、限られた期間の中でこれだけの複雑なシステムを作り切った実装者には心から敬意を表します。スピード開発においてトレードオフは避けられないものであり、それを理解した上で「まず動くものを作る」という判断は正しかったと考えています。
その上で、このようなトレードオフの積み重ねによって、運用フェーズに入ってから問題が顕在化していったと考えています。
運用中に顕在化した問題
主に見えてきた問題は4つです。
- ロジックとUIの混在/テスト困難: ドメインロジックと複雑なUI表現の両方を抱えたcontainerの増殖とそれによるテストの複雑化
- 影響不透明: 変更の波及範囲が読みづらい
- 自由という名のカオス: アーキテクチャは設計されていたが、機能責務の定義が不明確であったり、componentsの責務細分化方法がバラバラであったり、container/presentationalパターンの解釈一致が曖昧であったりなどでコンポーネント実装レベルでは自由度が高く、様々なフォルダ構成やコードが生まれてしまっていた
- AIのランダム性の悪夢: AIエージェントは多くの場合近くのコンテキストを拾って実装しがちなため、様々なフォルダ構成やコードが生まれてしまったCRMにおいて場所によってAIの出力が変わる問題が発生していた
問題から見える課題
なぜこのような問題が生まれてしまったのでしょうか。 私は二つあると考えました。
- コンポーネントフォルダの責務の細分化のための明確なルールが決まっていない
- containerからUI責務を担うpresenterを適切に切り出せていない
(先ほどもあったように、
features/components/containerの責務の中に、UIとその表示ロジックが混在してしまっているため、適切にcontainerからUIの責務を剥がさないとこのような負債は溜まる一方。)
つまり、CRMのアーキテクチャの課題は、componentsフォルダ内部の分割方法と、container/presentationalパターンの運用の二点だと言えます。
ちょいつぶやき: 完璧なアプリケーションはない
最初からメンテナンスしやすい設計を丁寧に行うことを否定するわけではありませんが、最初から完璧なアプリケーションはこの世には存在しないと考えています。課題が山積みのアプリケーションはもちろんですが、その時は完璧だったとしても、仕様追加や変更などの時間による変化でアプリケーションの姿は移ろうものです。
だからこそのリファクタであり、運用フェーズであり、開発保守なのだと思います。同時に、私はこのCRMが美しくなるのとともに成長していきたいと思っています。
課題の解決に向けて
では具体的にどのように取り組んでいけば良いのでしょうか。
今回は二つ上がった課題のうちの「componentsフォルダ内部の分割方法」にフォーカスして考えていきたいと思います。
この話はコンポーネントの責務細分化の話になります。いわゆるどのようにコンポーネントを切るかの方法論です。 これを考えるにあたって、色々なアーキテクチャパターンを調べましたが、CRMの既存コードと調和するアーキテクチャは見つけることができませんでした。何日か悩んだ末に既存コードに合った新しい設計パターンを作ろうという思惑が浮かびました。 その中で生まれたのが今回のお話のメインであるDOMAIN-CRUD-IO-LAYOUTパターンになります。(まだ仮称ですが、この記事ではこの名前で呼ばせてください)
2. DOMAIN-CRUD-IO-LAYOUTパターンとは
ここではDOMAIN-CRUD-IO-LAYOUTパターンについて解説していきます。
構成要素
- DOMAIN : アプリケーションの主要な業務領域やビジネス知識(例: Task, User)
- CRUD : データ操作の基本アクション
- C : Create (作成・登録)
- R : Read (参照・検索)
- U : Update (更新・編集)
- D : Delete (削除)
- IO : データフローの方向
- I : Input (入力)
- O : Output (出力)
- LAYOUT : CRUD/IOより先の任意の分解層(ヘッダー、コンテンツ、フッター、フォーム入力要素、テーブルやタブなどの表示部品など)
なぜこの構造なのか
この4つの要素と順序には、それぞれ明確な理由があります。
DOMAIN(最上位): システムは業務領域ごとに責務が分かれます。「何についてのコンポーネントか」を最初に示すことで、コードの居場所が直感的に分かります。bulletproofパターンのfeaturesと同じ思想です。
CRUD(2階層目): 業務システムの機能は、突き詰めればデータの作成・参照・更新・削除に分類できます。「このコンポーネントは何をするのか」を示すことで、責務の境界が明確になります。
IO(3階層目): 同じCRUD操作でも、入力(INPUT)と出力(OUTPUT)では責務が異なります。フォームにはバリデーションやsubmitロジックがあり、表示には整形やフィルタリングがあります。この分離により、テストの焦点も明確になります。
LAYOUT(任意): ここから先は「UIをどう構成するか」の話になります。ヘッダー、テーブル、ボタン群など、プロダクトやチームの文化によって粒度が異なるため、任意の分解層としました。
つまり、DOMAIN > CRUD > IO は「何の」→「どんな操作の」→「入力/出力どちらの」という思考の流れに沿った階層構造になっています。この順序で問いかければ、誰でも迷わずコンポーネントの配置場所を特定できます。
ルール
DOMAIN > CRUD > IO │ LAYOUT ────────────────────┼──────────────── 必須の分解ルール │ 任意の分解
- DOMAIN > CRUD > IO
- 必ずこの順序で階層構造を構成すること
- 必ずこの階層まで分解すること
- LAYOUT
- どの階層にも組み込める
- 必要に応じて追加する(チームで取捨選択)
これにより、最低限の一貫性を保ちつつ、チームの文化やプロダクトの特性に応じた柔軟性も確保できます。
フォルダ構成例
このルールに基づいたタスク管理アプリケーションのコンポーネント構造の例です。
features/
└── taskManagement/
└── components/
└── Task/ <<< DOMAIN(タスクドメイン)
├── TaskHeader/ <<< LAYOUT(ヘッダー部分の構造)
│ └── presenter.tsx
├── TaskDisplay/ <<< CRUD(一覧表示/Read)
├── TaskCreate/ <<< CRUD
├── TaskUpdate/ <<< CRUD
├── TaskDelete/ <<< CRUD
├── TaskSearch/ <<< CRUD(検索ロジック/Read)
│ ├── TaskSearchOutput/ <<< IO(検索結果の表示部分)
│ │ ├── TaskName/ <<< LAYOUT(個別のUI要素)
│ │ │ └── presenter.tsx
│ │ ├── container.tsx
│ │ └── presenter.tsx
│ ├── TaskSearchInput/ <<< IO(検索条件の入力部分)
│ │ ├── TaskName/ <<< LAYOUT(個別のUI要素)
│ │ │ └── presenter.tsx
│ │ ├── container.tsx
│ │ └── presenter.tsx
│ └── container.tsx
├── WeeklyTask/ <<< DOMAIN(タスクドメイン内のサブドメイン)
│ └── container.tsx
└── presenter.tsx
└──userManagement/
└── components/... <<< DOMAIN(ユーザー情報ドメイン)
補足と推奨事項
- DOMAIN の配下に DOMAIN をネストしても良い。
例)Task > WeeklyTask
- コンポーネントの命名: コンポーネントは基本UIなので、UI要素となるように命名しても良い。
例) TaskCreate > TaskCreateDialog
- CRUD/IOの命名の柔軟性: CRUD/IO の命名はアプリの文化に合わせて調整して良い。
例)TaskUpdate > TaskEdit / TaskSearchOutput > TaskSearchResult
- 命名の省略: 上位フォルダで命名を保証しているのであれば、配下フォルダは命名を省略しても良い。
例)Task/TaskCreate > Task/Create / Task/WeeklyTask > Task/Weekly
上記の認識はチームで全て統一することを推奨します。
DOMAIN-CRUD-IO-LAYOUTパターンの利点
個人開発の範疇で実装したところの所感は以下でした。
- 責務の明確化(最重要): 一番嬉しいのは責務がはっきりすること。各コンポーネントの役割が明確になり、実装に迷いが出にくい。
- テストの効率化 : 責務がはっきりすると、テストしなければならないことが絞れ、メンテナンス性・保守性が向上。
- AIとの親和性 : 階層と命名規則が一貫しているため、AIによる実装やメンテナンス時に精度良くコードを生成してくれる。
- 書き心地と可読性 : 構造が予測しやすいため、設計しやすく書き心地がいい + 可読性もいい。
なぜこの構成がCRMに合っているのか
大きく二つ理由があります。
CRMの業務特性との親和性
- CRMの本質がCRUD操作: CRMではすべてのデータは「作成→参照→更新」のサイクルで回る。CRUD層での分類がそのまま業務に直結。
- 入力と出力が明確に分離: CRMでは検索条件の入力フォームと検索結果の一覧表示など、FormとResultが画面上でも責務上でもはっきり分かれている。IO層での分割が自然に対応。
- ドメインが業務単位で独立: CRMは機能が業務領域ごとにほぼまとまっている。DOMAIN層での分割がそのまま業務の切り口と一致。
- 画面パターンが繰り返される: 「検索条件入力 → 一覧表示 → 詳細 → 編集」という流れがほぼ全機能で共通。命名規則が予測しやすく、開発・保守が効率化。
CRMは「ドメイン別のCRUD × 入出力」という構造が業務にそのまま対応しているため、多くの場合このパターンが自然にフィットします。
既存コードとの親和性
- フォルダ構造: すでに
〜Search、〜Management、〜Result、〜Detailのような命名が使われており、CRUD/IOの概念と自然に対応。 - Container/Presenter: ファイル単位の設計はそのまま活きる。フォルダ構造のルールなので競合しない。
- 導入コスト: 既存の暗黙的な構造を明文化したパターンなので、作り直しではなく整理として機能。
3. 実際のプロダクトへの導入
作ったものも実物で試してみないことにはその実際の効果は分かりません。そこで、当時進行していた開発プロジェクトで試験導入をしました。
導入対象
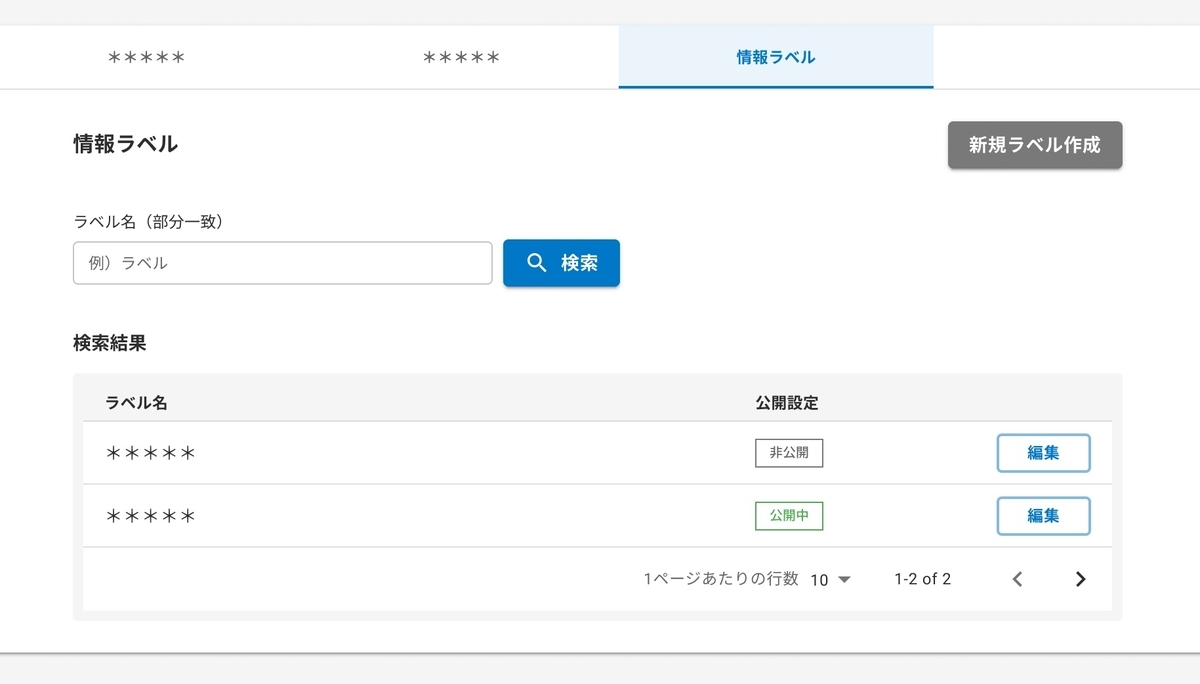
導入は、CRMシステムのマスタデータをビューから登録・更新が行えるマスタメンテナンス機能の中にある、お客様とのコミュニケーション種別を記録する情報ラベル機能について行いました。 情報ラベルは検索・登録・更新することができます。
情報ラベル検索のFigma
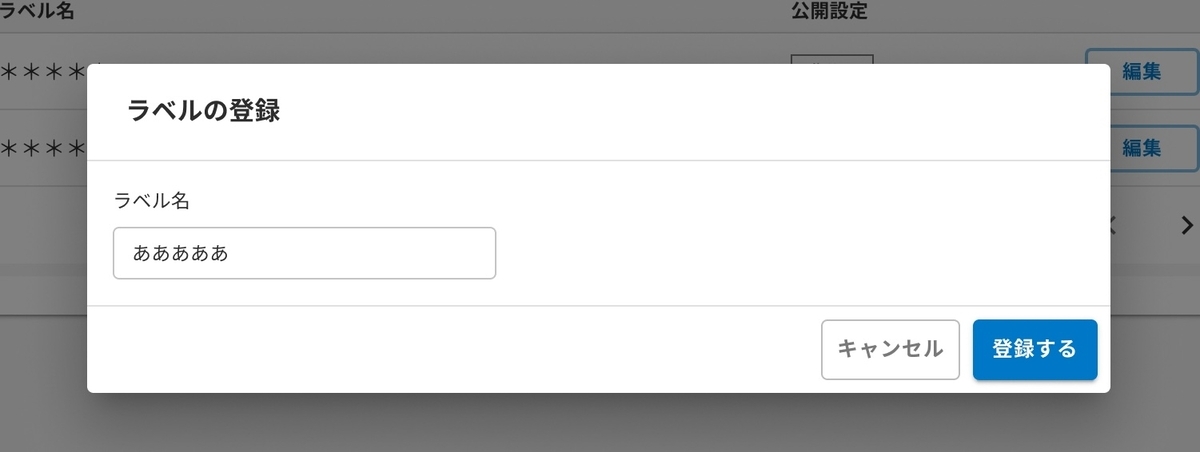
情報ラベル登録のFigma
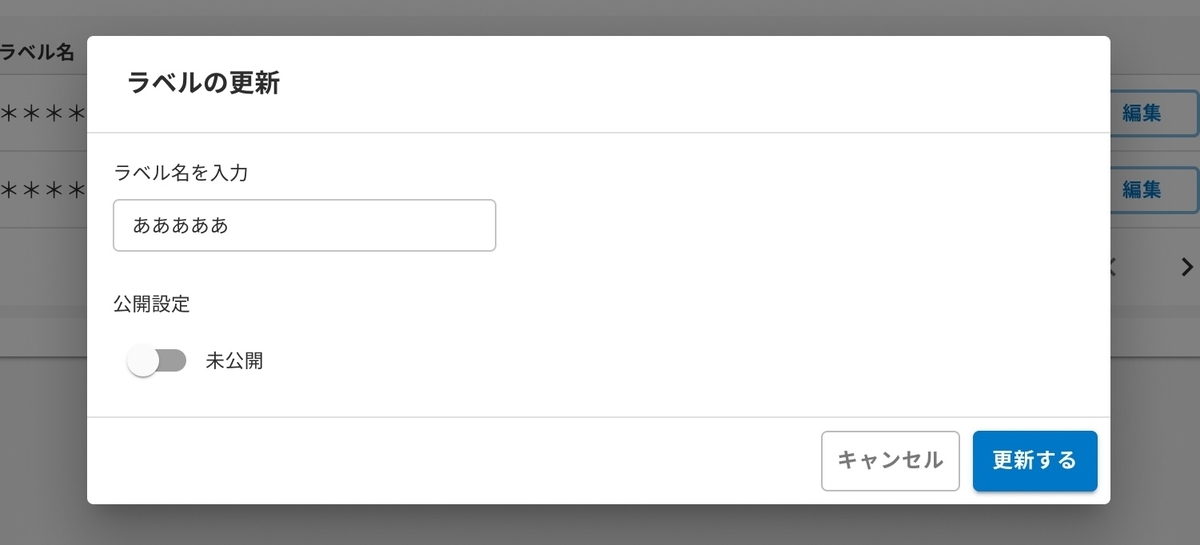
情報ラベル編集のFigma
- 情報ラベルのデータ構造は、ラベル名・公開設定(可視・不可視の真偽値)。
- 要件は情報ラベルのラベル名による部分一致検索機能がファーストビューで行え、上部に新規情報ラベル登録ボタン、検索結果の各項目の編集ボタン、それぞれから登録・更新が行えること。
- 加えて登録時にはラベル名のみ、更新時にはラベル名と公開設定が編集できること。
実装の流れ
前提、以下の点だけご認識ください。 - CRMにはコンポーネントをDOM-Tree形式的にネストしていく文化がある - RHFの処理はロジック・UIどちらの責務も複合的に持つため、CRMではcontainerで実装するように統一
informationLabelというDOMAINフォルダを作成します。
DOMAIN > CRUD なのでこの配下に今回の要件である、CRUDフォルダを作ります。
InformationLabel/ ├── InformationLabelCreateDialog/ <<< 追加(UI要素となるような命名をCRMでは行う) ├── InformationLabelEditDialog/ <<< 追加 └── InformationLabelSearch/ <<< 追加
DOMAIN > CRUD > IO なので、CRUD配下にIOのフォルダを作ります。
InformationLabel/
├── InformationLabelCreateDialog/
│ └── InformationLabelCreateForm/ <<< 追加(CRMではinput系をformと命名する文化があるのでそちらを踏襲)
├── InformationLabelEditDialog/
│ └── InformationLabelEditForm/ <<< 追加
└── InformationLabelSearch/
├── InformationLabelSearchForm/ <<< 追加
└── InformationLabelSearchResult/ <<< 追加(CRMではoutput系をresultと命名する文化があるのでそちらを踏襲)
よりComponentのレイアウト責務を分割するために、LAYOUTを追加していきます。
InformationLabel/
├── InformationLabelCreateDialog/
│ └── InformationLabelCreateForm/
│ └── Name/ <<< 追加(CRMにはフォーム要素の命名は要素名だけにする文化があるのでそれを踏襲)
├── InformationLabelEditDialog/
│ └── InformationLabelEditForm/
│ ├── Name/ <<< 追加
│ └── IsUsable/ <<< 追加
├── InformationLabelHeader/ <<< 追加
└── InformationLabelSearch/
├── InformationLabelSearchForm/
│ └── Name/ <<< 追加
└── InformationLabelSearchResult/
├── InformationLabelSearchResultHeader/ <<< 追加
└── InformationLabelSearchResultTable/ <<< 追加
├── InformationLabelSearchResultTableBody/ <<< 追加
└── InformationLabelSearchResultTableHeader/ <<< 追加
└── InformationLabelSearchResultTableRow/ <<< 追加
ここにCRMのcontainer & presentationalパターンでpresenter(UI)を実装します。
InformationLabel/
├── InformationLabelCreateDialog/
│ ├── InformationLabelCreateForm/
│ │ ├── Name/
│ │ │ └── presenter.tsx <<< 実装
│ │ └── presenter.tsx <<< 実装
│ └── presenter.tsx <<< 実装
├── InformationLabelEditDialog/
│ ├── InformationLabelEditForm/
│ │ ├── Name/
│ │ │ └── presenter.tsx <<< 実装
│ │ ├── IsUsable/
│ │ │ └── presenter.tsx <<< 実装
│ │ └── presenter.tsx <<< 実装
│ └── presenter.tsx <<< 実装
├── InformationLabelHeader/
│ └── presenter.tsx <<< 実装
└── InformationLabelSearch/
├── InformationLabelSearchForm/
│ ├── Name/
│ │ └── presenter.tsx <<< 実装
│ └── presenter.tsx <<< 実装
├── InformationLabelSearchResult/
│ ├── InformationLabelSearchResultHeader/
│ │ └── presenter.tsx <<< 実装
│ ├── InformationLabelSearchResultTable/
│ │ ├── InformationLabelSearchResultTableBody/
│ │ │ ├── InformationLabelSearchResultTableRow/
│ │ │ │ └── presenter.tsx <<< 実装
│ │ │ └── presenter.tsx <<< 実装
│ │ └── InformationLabelSearchResultTableHeader/
│ │ └── presenter.tsx <<< 実装
│ └── presenter.tsx <<< 実装
└── presenter.tsx <<< 実装
ロジックを実装します
InformationLabel/ ├── InformationLabelCreateDialog/ │ ├── InformationLabelCreateForm/ │ │ ├── Name/ │ │ │ ├── presenter.tsx │ │ │ └── container.tsx <<< 実装(ReactHookForm) │ │ ├── presenter.tsx │ │ └── container.tsx <<< 実装(ReactHookForm) │ ├── presenter.tsx │ └── container.tsx <<< 実装(TanstackQuery) ├── InformationLabelEditDialog/ │ ├── InformationLabelEditForm/ │ │ ├── Name/ │ │ │ ├── presenter.tsx │ │ │ └── container.tsx <<< 実装(ReactHookForm) │ │ ├── IsUsable/ │ │ │ ├── presenter.tsx │ │ │ └── container.tsx <<< 実装(ReactHookForm) │ │ ├── presenter.tsx │ │ └── container.tsx <<< 実装(ReactHookForm) │ ├── presenter.tsx │ └── container.tsx <<< 実装(TanstackQuery) ├── InformationLabelHeader/ │ └── presenter.tsx └── InformationLabelSearch/ ├── InformationLabelSearchForm/ │ ├── Name/ │ │ ├── presenter.tsx │ │ └── container.tsx <<< 実装(ReactHookForm) │ ├── presenter.tsx │ └── container.tsx <<< 実装(ReactHookForm) ├── InformationLabelSearchResult/ │ ├── InformationLabelSearchResultHeader/ │ │ └── presenter.tsx │ ├── InformationLabelSearchResultTable/ │ │ ├── InformationLabelSearchResultTableBody/ │ │ │ ├── InformationLabelSearchResultTableRow/ │ │ │ │ └── presenter.tsx │ │ │ └── presenter.tsx │ │ └── InformationLabelSearchResultTableHeader/ │ │ └── presenter.tsx │ └── presenter.tsx ├── presenter.tsx └── container.tsx <<< 実装(TanstackQuery)
実装完了です。
その後、CRMのテストルールに従い、presenterにはstorybookを、containerにはjestのテストを実装します。
プロダクトへの試験導入から見えた効果
- 実装時の迷いが減少
- やはり、CRMの既存のコードと調和を保ちつつ、責務分割が一定のルールのもとに理路整然と行われていると実感しました。特にテストを実装する際、テストケースを洗い出すときにこのテストで何を保証するべきかというスコープが決まっているため迷わずに実装を進められました。これは自由という名のカオスが一定解決したと言えます。
- AIの出力向上
- また何よりも嬉しかったのはAIがどこに何を書いてあるのかを高精度で判断してくれたことです。例として、containerにロジックが書かれている&CRUDでフォルダ管理されているため、「情報ラベルの検索ロジックはどこに書いてある?」と質問すると、一発目から的確にフォルダを認識してくれました。これはAIのランダム性の悪夢が一定解決したと言えます。
claude-codeとの実際の会話
> 情報ラベルの検索ロジックはどこに書いてある?
⏺ 情報ラベルの検索ロジックを探してみます。
⏺ Search(pattern:
"情報ラベル|InformationLabel|label.*search|ラベル.*検索")
⎿ Found 85 files (ctrl+r to expand)
⏺ 情報ラベルの検索ロジックに関連するファイルが見つかりました。メインの
検索ロジックが含まれていそうなファイルを確認してみます。
⏺ Read(src/features/itemRegistration/components/MasterMaintenance/Info
rmationLabel/InformationLabelSearch/container.tsx)
⎿ Read 111 lines (ctrl+r to expand)
⏺ 情報ラベルの検索ロジックが見つかりました!メインの検索ロジックは以下
の場所にあります:
情報ラベル検索の主要ファイル:
1. メインコンテナ:
src/features/itemRegistration/components/MasterMaintenance/Informati
onLabel/InformationLabelSearch/container.tsx
4. チームへの導入
プロダクトに試験的に導入したとしてもチームに納得してもらわないことには、アプリケーション全体へ適応する作業をチームのリソースを割いてリファクタすることはできません。プロダクトのアーキテクチャを変更する説明責任を果たす必要があります。CRMのフロントエンドチームでは毎週水曜にリファクタデイが設けられ、負債解決に向け取り組みを進めていたため、その時間を利用してチームに共有を行いました。
課題感の確認と解決策の提案
記事の冒頭にあった課題をチームに共有し、問題点を提示してその解決策の一つがDOMAIN-CRUD-IO-LAYOUTパターンであることを試験導入を例に伝えました。
みなさん快く受け入れてくださり、まずはitemRegistrationの配下全体への適用に向けてリファクタを進めることにしました。
CRMと調和を取るための認識合わせ
新しいパターンを導入する際、既存のCRMの文化・慣習を無視してはいけません。チームで以下の点について認識合わせを行いました。
- 命名規則の統一
- Input →
〇〇Form(CRMの既存慣習を踏襲) - Output →
〇〇Result(CRMの既存慣習を踏襲) - Update →
〇〇Edit(CRMの既存慣習を踏襲) - コンポーネントフォルダはPascalCase
- Input →
- ネスト構造の方針
- CRMにはDOM-Tree形式的にネストする文化があるため、同様に全てネストする方針を採用
- ただし、特定の階層下で共通化できるLAYOUTがある場合はその階層直下で共通LAYOUTとして定義しても良い
InformationLabel/ ├── InformationLabelHeader/ │ └── presenter.tsx ├── Name/ <<< 共通レイアウト │ ├── presenter.tsx │ └── container.tsx ├── IsUsable/ <<< 共通レイアウト │ ├── presenter.tsx │ └── container.tsx ├── InformationLabelCreateDialog/... ├── InformationLabelEditDialog/... └── InformationLabelSearch/...
- ロジックの配置ルール
- ReactHookFormのロジックはForm系のcontainerに配置
- TanstackQueryのロジックはCRUD層(Dialog/Search)のcontainerに配置
- LAYOUTの分解基準
- 再利用性が高い、または責務を明確に分けたい場合にのみ切り出す(必須ではない。レビュー時に過剰な分解でないか判断する)
これらをドキュメント化し、チーム全員が参照できる状態にしました。
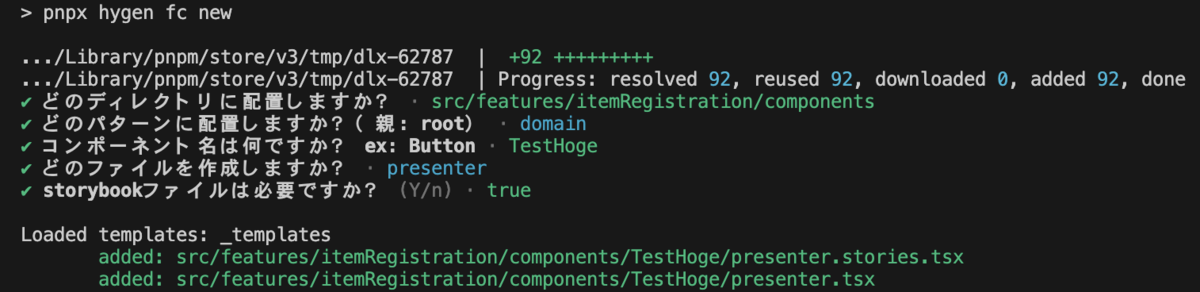
scriptを使ったフォルダ作成機能の実装
hygenというパッケージを使用して、コマンドを叩いてDOMAIN-CRUD-IO-LAYOUTルールに基づいてコンポーネントを作成できるscriptを作成しました。これによって誰でも再現性高く実装できるようになりました。
チームに導入した効果
チーム全員で取り組むことで見えてきた効果や声、再確認できた効果もありました。
- 構造の美しさと理解の深化
- 完成形が見えた時に「綺麗だな」と感じられる構造になった。コンポーネント責務分解への理解が深まったという声も。
- レビュー効率化
- PRが何のドメインの何の機能を開発、ないしはメンテナンスしているのか認識しやすくなった(可読性が上がった)。アバウトな言葉で機能の説明をしなくて良い、かつチームで開発知識やドメインの認識が揃うのも魅力。(責務逸脱の検知が容易)
- 実装とテストの一貫性
- ある程度決まったコンポーネント責務分解の指標があることで、ロジック実装やテストに一貫性が生まれ、作業しやすくなった。
- テスト容易性の向上
- 責務が細分化されたため、テストケースの作成がやりやすくなった。実際にテストを書いていて、ここは編集機能だから参照のテストはいらない。と判断できたりなど。
- 実装時の迷いが減少
- 一定のルールが明確にあるため、そのルールの中での実装を意識することになる。それが最初の設計の簡易化に大きく貢献してくれている。
- AIの出力向上
- 特にテスト実装をAIに任せるのが容易になった。また、責務が限られているのでAIの出力をレビューすることへのハードルも下がった。
5. よくある疑問と回答(Q&A)
チームで実装する中や、他チームのフロントエンドエンジニアが集まる機会に共有したりする中で、やはり課題・疑問は上がりました。それぞれについて回答していきます。
Q. 初見だと責務分解されすぎに感じる。学習コストが高いのでは?
A. 確かに初見では学習コストがあります。ただ、一度理解すれば構造が予測可能になり、むしろレビューしやすくなります。最初の導入時にはペアプロやモブプロで認識を揃えることをお勧めします。
Q. LAYOUTの責務分解の基準がわからない。over-engineeringにならない?
A. LAYOUTは任意の分解層です。必須ではありません。再利用性が高い部品や、責務を明確に分けたい場合にのみ切り出してください。迷ったら切り出さない選択も正解です。over-engineeringを避けるため、「本当に必要か?」を常にレビューで問いかけましょう。
Q. LAYOUTは一括フォルダ管理でも良いのでは?
A. 良いと感じました。CRMはDOM-Tree形式的にネストする文化があるのでやりませんでしたが、layoutフォルダを作って一括管理しても良いと思います。むしろこの方がDOMAINのトップレイヤーは見やすいかも?チームの文化に合わせていただければ!
MasterMaintenance/
└── InformationLabel/
├── Layout/
│ ├── InformationLabelHeader/
│ │ └── presenter.tsx
│ ├── Name/
│ │ ├── presenter.tsx
│ │ └── container.tsx
│ └── IsUsable/
│ ├── presenter.tsx
│ └── container.tsx
├── InformationLabelCreateDialog/...
├── InformationLabelEditDialog/...
└── InformationLabelSearch/...
Q. upsertはどのように分割する?
A. upsertというCRUDフォルダを作って良いと思います。また、場合によってはその配下にIOとしてCreateInputとUpdateInputのpresenterをそれぞれ実装するなどの工夫もできるかと思います。
Q. 検索結果の詳細カードをそのまま編集フォームに切り替える要件の場合は?
A. 色々方法はあると思います。チームで最適なものを選んでみてください。
- Updateの配下にOutputも作成し、Read配下のOutputにimportする
- Read配下のOutputがクリックされたら、Updateの配下Inputに表示切り替えする
いずれにせよまだまだ改善が必要なため、引き続きDOMAIN-CRUD-IO-LAYOUTパターンのメンテナンスは続けていきます。 (lint等の静的解析の導入や、細かいルールの変更・拡張を現在検討中です)
最後にはなりますが、導入時の注意点とまとめを書かせていただきこの記事を閉じたいと思います。
6. 導入時のポイントと注意点
もし今回のDOMAIN-CRUD-IO-LAYOUTを導入したい場合は、CRMでの導入でも実施された・実施予定の以下の点を整備することをお勧めします。
段階的な導入
メンテナンスしやすい機能を選んでリファクタすることをお勧めします。特に複雑なロジックがある機能ではなく、まずは単純なCRUD操作しかない機能で導入してみてください。
チーム内の認識合わせ
DOMAIN-CRUD-IO-LAYOUTパターンの認識合わせを行いチームで目線を揃えると良いと思います。- 何を解決するためのコンポーネントアーキテクチャなのかの共有
- 補足と推奨事項を参照し、チームのローカルルールを規定・共有
ドキュメントと言語化
- この記事の
**DOMAIN-CRUD-IO-LAYOUTパターン**とはの章と、チーム内の認識合わせの結果をガイドラインとして文章化し、AIルールにも明記しましょう。
プロダクト特有の事情
- 例外要件はローカルルールに落とし、逸脱を明示しましょう。
まとめ
DOMAIN-CRUD-IO-LAYOUTパターンの本質
このパターンは、システムと実装のギャップを埋めるために生まれた実用的なコンポーネント設計パターンです。これにより、実装者は明快な判断基準で迷わずコンポーネントを配置できるようになります。
パターンが適用できる場面
- ドメイン知識が厚く、変更頻度が高いCRMのようなシステム
- 複数人での開発でコンポーネントフォルダの責務分割に一貫性を保ちたいプロジェクト
- AI支援開発を積極的に取り入れたい組織
- コンポーネント設計で迷いが多く、レビューコストが高い現場
AI時代のフロントエンド開発
AIが開発に参加する時代において、コンポーネントの構造的な明確さはこれまで以上に重要になります。AIは近くのコンテキストから推論するため、責務が曖昧なコードベースでは出力がブレてしまいます。責務の分解の追求は、人間とAIの両方にとって理解しやすいコードを生み出す鍵となると考えます。
このパターンは完璧な解ではありませんが、実装の現場で迷わず判断できるという実用性を重視した設計です。皆さんのプロジェクトでも、実装レベルの課題を解決するヒントになれば幸いです。
ここまで長く読んでいただきありがとうございました!
バイセルではエンジニアを募集しています。少しでも気になった方はぜひご応募お待ちしています。