

はじめに
こんにちは、バイセル23卒エンジニアの臼井です。
今回はChatGPTに社内の情報を答えてもらうために、テキストのEmbedding APIを使用して、社内情報をRAGで扱う方法について紹介します。
社内の情報には画像データなど、テキスト以外のデータもありますので、それらをどのようにしてEmbeddingするかが論点となります。
対象読者は、自前のデータをChatGPTなどのLLMに組み込みたいと考えている開発者です。
特に、多様なデータ形式(テキスト、画像、スライドなど)を組み込みたい方の参考になれば幸いです。
背景
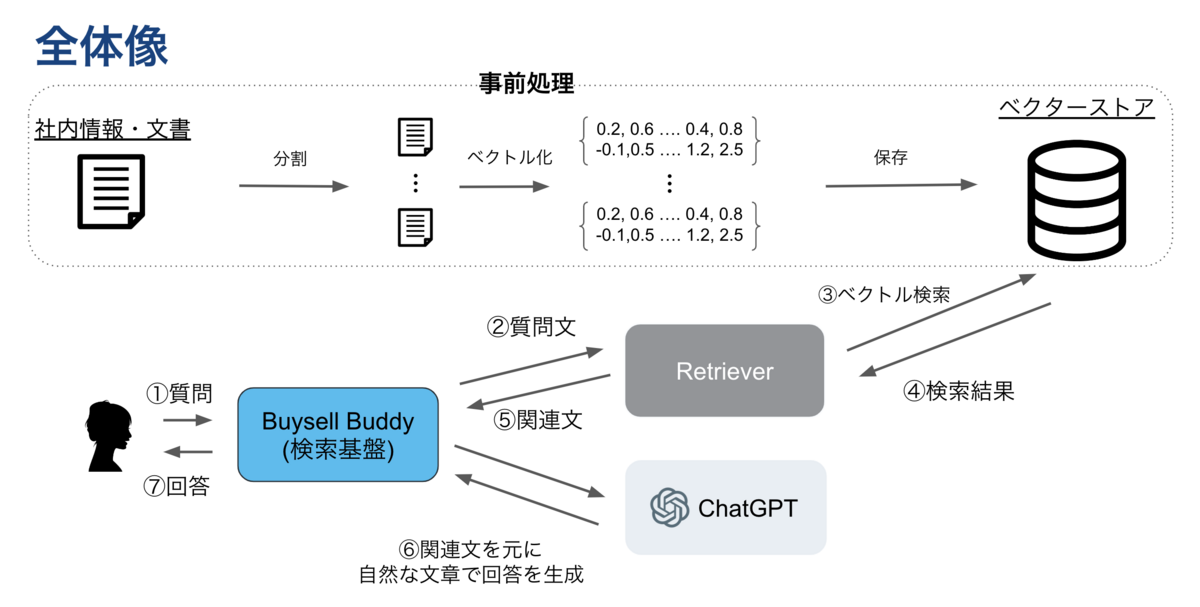
バイセルでは独自にリユースの商品情報や査定情報を持っており、これをChatGPT(BuySell Buddy)に組み込んで、社内で運用したいと考えていました。
つまり、ChatGPTを用いて社員が素早く効率的に社内の情報を取得できるようにしたいということです。
ちなみにBuySell Buddyとは、社内で様々な形式のインタフェースを用いてChatGPTを使用するための基盤です。
詳しくは過去に記事を書いているので、以下のリンク先をご覧ください。
Fine-tuningとRAG
ChatGPTに自前の情報を答えてもらうには、主にFine-tuningとRetrieval Augmented Generation(以下RAG)の2種類の方法があります。
2種類の方法はどちらかを選ばなくてはいけないというわけではなく、両方を組み合わせて使用可能ですが、今回はRAGのみに絞りました。
Fine-tuningは、OpenAIではGPT-3.5 Turboに導入された機能で、ユーザーは自前のデータでモデルをカスタマイズし、特有のニーズに合わせた応答の生成が可能なGPTを作ることができます。
これは、特定業界や専門用語を多用する環境での文書生成などに特に有効です。
しかし、訓練に多くのデータやコストが必要であることや、開発時はGPT-4にまだ対応していなかったこと、精度が未知数であったことから、今回はFine-tuningを使いませんでした。
一方、RAGはあらかじめ保存しておいたデータベース内の情報を検索し、その検索結果をモデルが参照することでより精度の高い回答を生成します。
具体的には、ユーザーの問いに対する回答を生成する際に、RAGは関連する情報をデータベースから検索し、これらの情報を補助的な知識として利用します。
このプロセスにより、モデルは問いに対しより詳細かつ正確な回答を生成できるようになります。
自前の情報はEmbeddingによりベクトル化して、ベクトル計算に特化したデータベースであるVectorStoreへ保存されており、そのベクトルのcos類似度を計算することで文書同士の関連度を出すことができる、という仕組みになっています。
この場合、Fine-tuningのように学習のために大量にデータを用意する必要がなく、コストに関してもEmbeddingには多少かかりますが、モデルをトレーニングするより低くなるという認識です。
今回は、返答精度が求められること、データ量に依存せず開発・検証が楽にできること、GPT-4でも運用できることから、RAGによる方法を採用しました。
また、ベクトル周りの処理は少し難しいですが、以下のサイトが視覚的にわかりやすかったので参考にしてみてください。
その他使用した技術
本題とは外れますが、今回使用した技術やサービスについても簡単に紹介します。
RAGにおいてテキストなどのデータをベクトル化する処理をEmbeddingと言いますが、そのモデルにはOpenAIのtext-embedding-ada-002を使用しました。
また、VectorStoreにはインメモリで動作の速いRediSearchを採用しました。
VectorStoreのその他の候補は、OpenAIのドキュメントでいくつか紹介されているので参考にしてください。
また、今回は動作確認のために簡単なアプリを作成して検証することが目的だったため、フロントエンド部分にはStreamlitを使用しました。
課題
RAGを用いれば、テキスト形式の社内データは簡単にChatGPTに返答させることができます。
しかし、私たちが組み込みたい情報には、画像付き資料やスライドなど、素直にテキストとしてEmbeddingできないデータが多くありました。
例として、ゴルフクラブの説明のスライドを以下に示します。

これらのようなテキスト以外のデータもテキストのEmbedding APIを使用してベクトル化してVectorStoreに保存し、RAGのフローに含めるため、以下のようなアプローチを取りました。
アプローチ
テキストしかEmbeddingできないのであれば、画像のURLをMarkdown形式でテキストに挿入してEmbeddingすればよいのではないかと考えました。
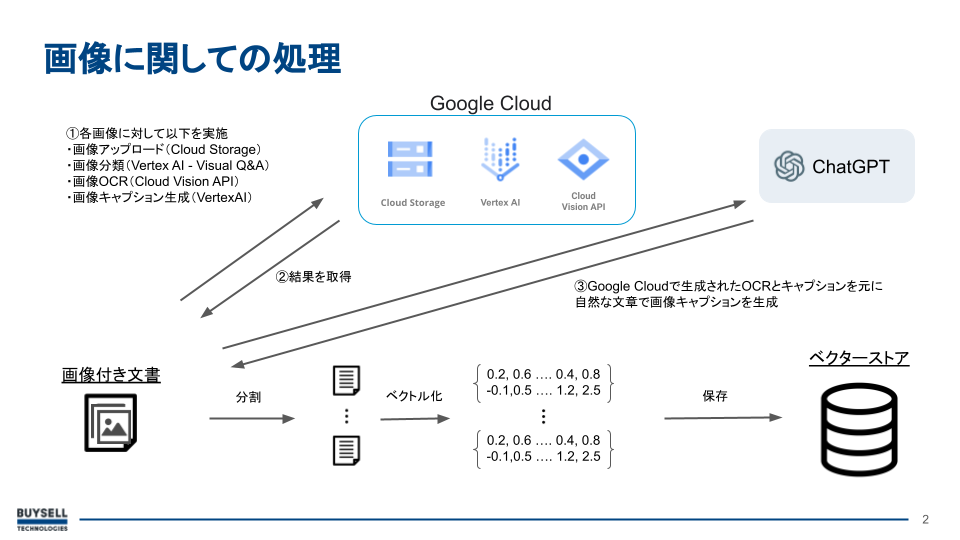
そのためには、画像を説明するテキストが必要になるので、AIベースの画像キャプション生成サービスを使用して説明文を作成します。
画像データには、文字が含まれるものもあるので、それに対してはOCRを使用してテキストを抽出しました。
その後、画像をGoogle Cloud Storage(以下GCS)にアップロードし、その保存先URLとキャプションを[キャプション](URL)のように組み合わせてEmbeddingし、VectorStoreに保存します。
保存した[キャプション](URL)をRetrieveし、ChatGPTに参考情報として渡すことで、返答に画像のURLを含められるようになるはずです。
詳細なフロー図は以下の通りです。 順番に詳しく紹介していきます。
キャプション生成について(フロー図の1に該当)
インフラにGoogle Cloudを使用していたので、AIベースの画像キャプション生成サービスにはVertex AIのImage captionsを使用しました。
open_clipというライブラリを使用すると外部サービスに頼らずキャプション生成できますが、実行してみたところ時間とメモリを多く必要としたため、今回は使用しませんでした。
AIによるキャプション生成では、画像内のオブジェクトやシーンに関する説明を生成してくれます。
Vertex AIは日本語では生成できないので、Embeddingする前に英語から日本語へ翻訳する必要があります。
コードは以下です。
import requests from google.cloud import translate_v2 DEFAULT_BASE_URL = "https://us-central1-aiplatform.googleapis.com/v1/projects/{project_id}/locations/us-central1/publishers/google/models/imagetext:predict" def generate_image_caption(image_content: bytes, google_credentials) -> str: # 画像のキャプションを生成 base64_image = base64.b64encode(image_content).decode() headers = { "Authorization": f"Bearer {google_credentials.token}", "Content-Type": "application/json; charset=utf-8", } json_data = { "instances": [{"image": {"bytesBase64Encoded": b64_image}}], "parameters": { "sampleCount": 1, "language": "en" }, } response = requests.post( DEFAULT_BASE_URL.format(project_id="YOUR_PROJECT_ID"), headers=headers, json=json_data, ) image_caption_en = response.json()["predictions"][0] # Google翻訳で日本語に翻訳 translate_client = translate_v2.Client() translate_result = translate_client.translate(image_caption_en, target_language="ja") image_caption = translate_result["translatedText"] return image_caption
また、キャプション生成はコンソールからも気軽に試せるので、使用感を確認したい場合はぜひ試してみてください。
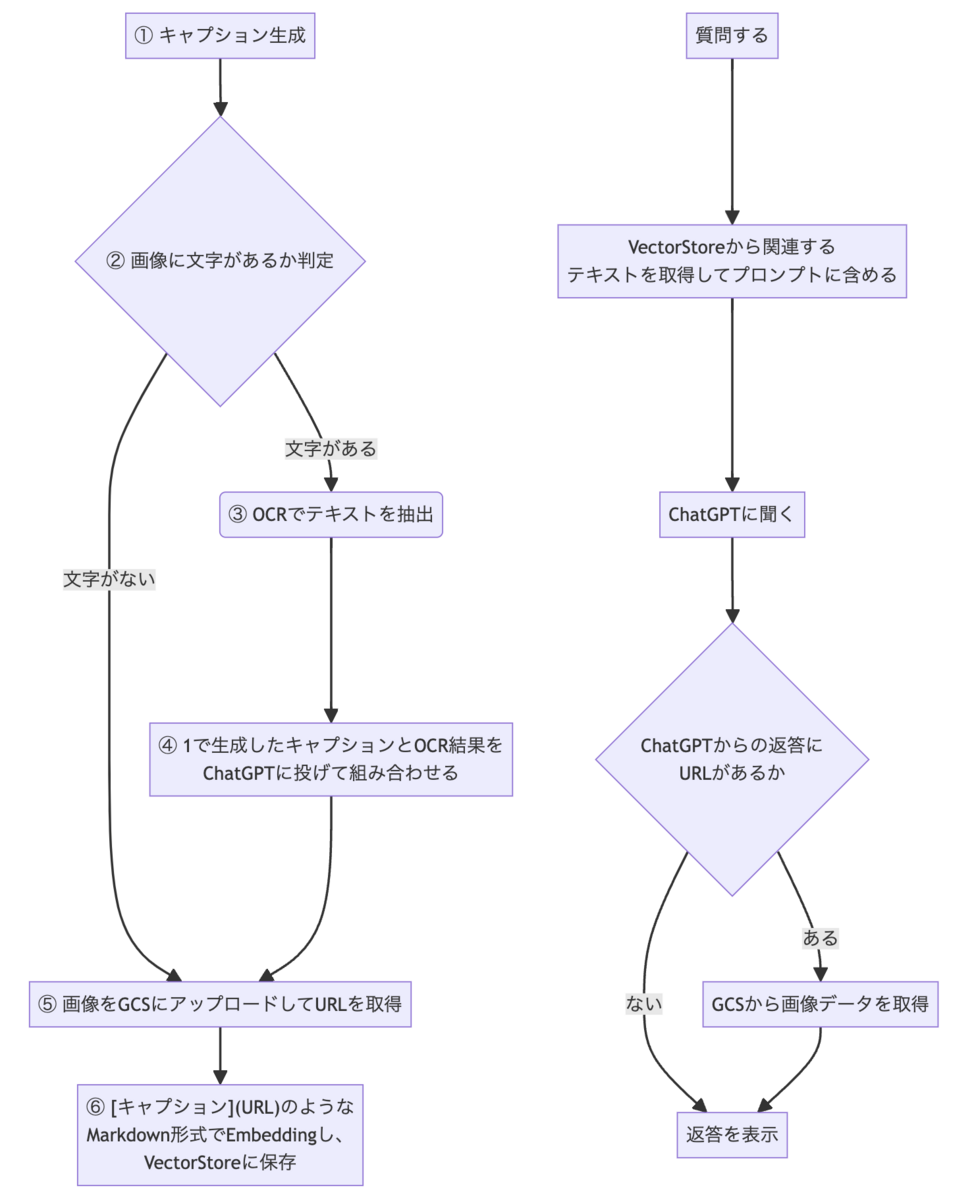
画像に文字があるか判定(フロー図の2に該当)
そもそもなぜ文字あり画像と文字なし画像を条件分岐する必要があるのかというと、文字なし画像にOCRすると不正なテキストが抽出され、最終的な画像キャプションの精度が落ちることがあるからです。
そのため、商品などの何かの物や事柄に関しての説明画像なのか、単なるインゴットや風景の画像なのかをこのステップで判定します。
画像内にテキストが含まれるかどうかはVertex AIのVisual Q&Aを使って実装しています。
エンドポイントはキャプション生成と同じです。
こちらも同じくコンソールで簡単に試せるので、使用感を確認したい場合はぜひ試してみてください。
コードはこちらです。
import requests from google.cloud import translate_v2 DEFAULT_BASE_URL = "https://us-central1-aiplatform.googleapis.com/v1/projects/{project_id}/locations/us-central1/publishers/google/models/imagetext:predict" def visual_qa(uploaded_file, google_credentials): # 画像にテキストが含まれるか判定 base64_image = base64.b64encode(uploaded_file.read()).decode() headers = { "Authorization": f"Bearer {google_credentials.token}", "Content-Type": "application/json; charset=utf-8", } json_data = { "instances": [ { "prompt": "Does this image include a description?", "image": {"bytesBase64Encoded": base64_image} } ], "parameters": { "sampleCount": 1, "language": "en" }, } response = requests.post( DEFAULT_BASE_URL.format(project_id="YOUR_PROJECT_ID"), headers=headers, json=data, ) return response.json()["predictions"][0] # "yes" or "no"
画像に対して、"Does this image include a description?"と質問することで、"yes"か"no"のどちらかの回答を得ることができ、画像内にテキストが含まれるかどうかが判定できます。
課題としては、回答精度は完璧でないことが挙げられます。
古銭などの文字が含まれてしまっている画像に関しては、文字ありと判定されることがありました。
これはプロンプトチューニングで改善が可能だと思われますので、Visual Q&Aへのプロンプトも引き続き最適解を探していきたいです。
文字あり画像のOCRとキャプション生成について(フロー図の3、4に該当)
画像中にテキストが含まれる場合は、OCR(Optical Character Recognition)を用いて取得しました。
OCRには、Google CloudのVision APIを使用しました。
OCRの場合もキャプション生成と同様に、tesseractというOSSを使用すると外部サービスに頼らずに実行できますが、精度や処理速度、インフラのコストを考えて今回は使いませんでした。
OCRで取得したテキストに、Vertex AIのキャプション生成で得た文章を加え、ChatGPTに送って総合的な説明文を作成してもらいます。
コードはこんな感じです。
LangChainを使っていますが、LangChainは更新が早く、バージョンによってはこのコードが動かない可能性もあるので注意してください。
from google.cloud import vision from langchain.llms.base import LLM from langchain.chat_models import ChatOpenAI from langchain.prompts import ChatPromptTemplate def detect_text(image_content): client = vision.ImageAnnotatorClient() image = vision.Image(content=image_content) response = client.document_text_detection( image=image, image_context={"language_hints": ["ja"]} ) ocr_text = response.full_text_annotation.text return ocr_text.strip() def generate_text_image_caption(image_content, google_credentials): vertex_ai_caption_result = generate_image_caption(image_content, google_credentials) vision_ocr_result = detect_text(image_content) template = """ # 命令 あなたは画像キャプションを作成するプロです。 次の「条件」と「情報」を用いて最適な画像キャプションを作成してください # 条件 - 最適な画像キャプションを1つ考えてください - 画像キャプションは日本語で生成してください - 画像キャプションは詳細に説明してください。無理に1文にまとめる必要はありません。 - なるべくOCRの情報は取りこぼさないようにしてください。特にOCRで一番最初の文章はその画像のタイトルの可能性であることが多いので、その情報はなるべくキャプションに含めてください。 # 情報 ある画像をGCPのvisualQAで画像キャプション生成したところ \``` {vertex_ai_caption_result} \``` という回答が得られました。 全く同じ画像をGCPのVisionAPIでOCRしたところ \``` {vision_ocr_result} \``` という結果が得られました。 """ chat_prompt = ChatPromptTemplate.from_messages([("human", template)]) llm = ChatOpenAI(temperature=0, model="gpt-3.5-turbo-1106", verbose=True) chain = chat_prompt | llm ai_message = chain.invoke({"vertex_ai_caption_result": vertex_ai_caption_result, "vision_ocr_result": vision_ocr_result}) image_caption = ai_message.content return image_caption
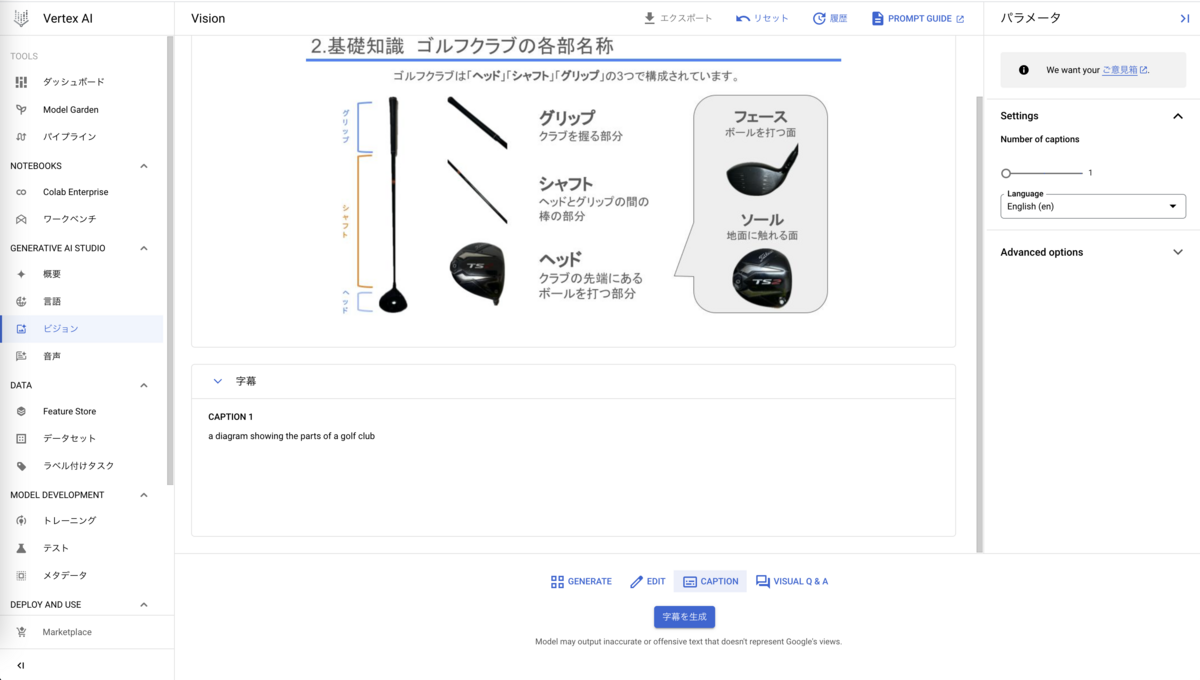
具体的には、上述のゴルフクラブの説明スライドから、以下のような結果が得られました。
- VertexAIのキャプション生成
a diagram showing the parts of a golf club in japanese
- VisionAPIのOCR
2.基礎知識 ゴルフクラブの各部名称 ゴルフクラブは「ヘッド」 「シャフト」 「グリップ」の3つで構成されています。 グリップ シャフト ヘッド XXIO グリップ クラブを握る部分 シャフト ヘッドとグリップの間 の棒の部分 ヘッド クラブの先端にある ボールを打つ部分 フェース ボールを打つ面 ソール 地面に触れる面 B DRAW
- 生成されたキャプションとOCRのテキストをまとめてChatGPTに返答してもらった最終キャプション結果
"2.基礎知識 ゴルフクラブの各部名称"というタイトルの下に、ゴルフクラブが「ヘッド」、「シャフト」、「グリップ」の3つで構成されていることが説明されている図解。 グリップはクラブを握る部分、シャフトはヘッドとグリップの間の棒の部分、ヘッドはクラブの先端にあるボールを打つ部分で、ヘッドはさらにフェース(ボールを打つ面)とソール(地面に触れる面)に分けられている。 また、"XXIO"と"B DRAW"という文字も見受けられる。
Embeddingプロセス(フロー図の5、6に該当)
いい感じにキャプションが生成できましたので、あとはこれをURLと共にEmbeddingするだけです。
画像データはGCSにアップロードし、そのURLと生成したキャプションをMarkdown形式で組み合わせることで、Embeddingするテキストが作成できました。
得られたテキストをEmbeddingするために、OpenAIのtext-embedding-ada-002モデルを使用してテキストをベクトル形式に変換します。
このベクトルはテキストの意味内容を数値的に表現しており、生成されたベクトルを高速な検索と効率的なデータ管理が可能なデータベースであるVectorStoreに保存します。
これで、[キャプション](URL)のテキストをRAGによって扱えるようになりました。
結果
以上のアプローチにより、画像データをテキストで説明し、その説明文をベクトル検索で取得できるようになりました。
実際に質問して、返答を表示している様子は以下のようになります。

文字でも十分に説明してくれていますが、画像も表示することでよりわかりやすくなっています。
画像URLはStreamlitで表示する際にGCSからデータを取得することで、あたかもChatGPTが画像を返答しているように見せることができました。
これは、DALL·E 3のようなAIによる画像生成とは根本的に仕組みが異なるので注意してください。
また、今回画像データをEmbeddingする処理のフローを作ったことで、画像付きのサイトをクローリングして得たデータなど、様々なデータをEmbeddingしてVectorStoreへ追加できるようになりました。
今後の課題
今回作ったこのシステムにおいては、Embedding以外の箇所でいくつかの問題が発生しました。
- VectorStoreに保存したデータが多くなってくると、Retrieveの精度が落ちて必要な情報を取得できない場合がある
- 質問の仕方によってはChatGPTが画像のURLを返答してくれず、画像を表示できない場合がある
これらの問題は、プロンプトエンジニアリングや、Retrieveの最適化、Agentの導入によって解決できる可能性があります。
今後の展望
現状ではまだユーザーに使ってもらえる状態ではないので、上記の課題を解決し、リリースする予定です。 また、Slack Buddyにもこの機能を組み込み、Slack上で簡単に査定情報や商品情報を取得できるようにもする予定です。
おわりに
今回はChatGPTに社内の情報を答えてもらうために、テキストのEmbedding APIを使用して、テキスト以外の社内情報をEmbeddingする方法について紹介しました。
LLMは人間の仕事量を大きく減らしてくれますが、実際に実務で使いこなすためには多くの課題があると感じました。
また、最近ではOpenAI DevDayが開催され、わくわくするような新しい機能がたくさん発表されました。
GPT-4 Turboでは画像を入力できるようになったので、今回Vertex AIを使用して画像のキャプションを生成した部分は、GPT-4 Turboに置き換えることでもしかすると精度が改善するかもしれません。
さらに、GPT-4でもFine-tuningが可能となったので、RAGと組み合わせて更なる精度改善につながる可能性があります。
このように、LLMは日々進化しており、その可能性は無限大なので、これからも様々なことに挑戦していきたいと考えています。
最後に、バイセルでは新卒エンジニアを随時募集しています。
新卒でもこのような挑戦的なプロジェクトに取り組むことができるバイセルに興味がある方は、ぜひ以下の採用サイトをご覧ください。