
はじめに
こちらは バイセルテクノロジーズ Advent Calendar 2021 の 8日目の記事です。
前日の記事は @taihei618さんの「Elasticsearchの導入にあたって考えたこと」でした。
こんにちは、21年新卒で入社した開発2部の飯島です!
今は主にリユースプラットフォーム内の商品マスタサービスを開発しているのですが、インフラ監視ツールを導入するにあたって調査・検討を行ったので、今回はその内容を共有できればと思います。

前提
インフラ
商品マスタサービスではインフラにGCPを採用しており、主なバックエンドサービスは以下のような構成となっております。
- Google Cloud Run*1(2サービス。以下Cloud Runと表記します。)
- Hasura*2で構築したGraphQLサーバーのサービス
- Hasuraのカスタムロジック用サービス
- Google Kubernetes Engine*3(1クラスタ。以下GKEと表記します。)
- Elasticsearch*4
上記のサービスはリユースプラットフォームの他のプロジェクトから頻繁に呼ばれる想定で、死活監視が必須と判断したので、インフラ監視ツールを入れることになった次第です。
死活監視の項目
死活監視の項目に関しては以下に定めました。設定した基準を一定期間超えたらSlackのチャンネルに通知されるようにしております。
- CPU使用率が高くなりすぎていないか
- メモリ使用率が高くなりすぎていないか
- リクエストレイテンシが閾値を超えていないか
- サービスのコンテナの状態が正常になっているか
Google Cloud Monitoringを導入
Google Cloud Monitoringとは
Google Cloud Monitoring*5(以下Cloud Monitoringと表記します。)とは、GCPで提供されている運用監視のマネージドサービスで、GCP上のサービスやアプリケーションのイベントやログなどをリアルタイムで見ることができます。今回の監視対象であるCloud RunとGKEもこちらで監視ができます。
ただ現状、GKEに関してはデフォルトではCPUやメモリなどといった低レベルのリソースまでしか見れず、podやcontainerのレベルまで詳細に監視するには追加で設定が必要でした。いくつか選択肢があるので、自分が選んだ方法も含めて以下で紹介します。
今回はワークロード指標を利用
GKEクラスタにオプションで有効化できるワークロード指標*6を用いる方法です。要件を満たしており導入も簡単だったので今回はこちらを利用しました。
ワークロード指標を有効化することで、アプリケーションの指標を収集してCloud Monitoringに送信するエージェントが各nodeにデプロイされるので、その指標を構成するPodMonitorを自分でデプロイして指標が収集されるように実装をします。
ちなみに、PodMonitorで参照するリソースは監視対象にPrometheus Exporter*7(以下Exporterと表記します。)が組み込まれていない限りは、監視対象ではなくExporterのpodの方であり、その場合はそのExporterもデプロイする必要があるので注意です。
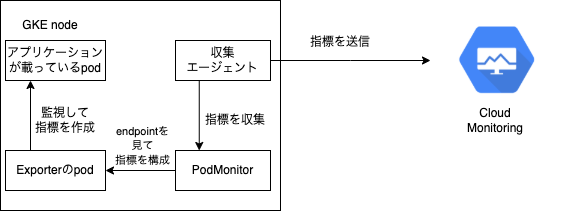
自分はpod内のコンテナの状態が正常になっているか知りたかったので、それらの情報をKubernetesのAPIサーバーからリッスンして指標を作成するkube-state-metrics*8をデプロイしました。
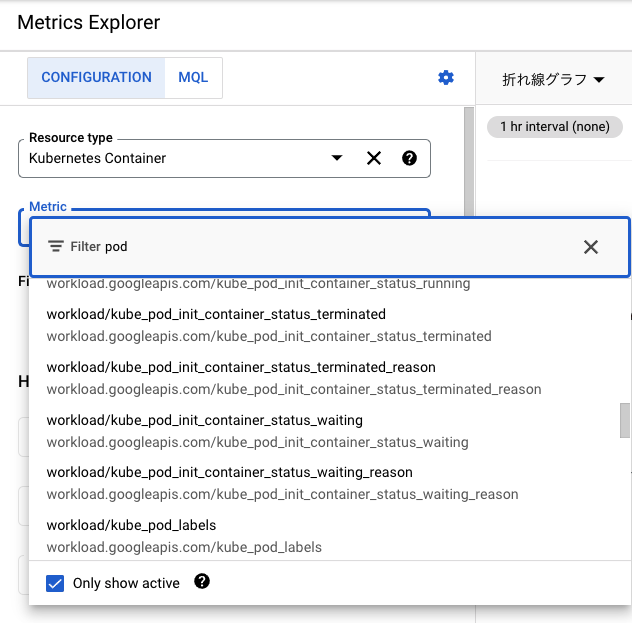
以上を実装した上で、Cloud MonitoringのMetrics Explorerを開くと、以下のようにResource TypeがKubernetes ContainerのMetricにkube-state-metricsの指標*9が追加されていることがわかります。
尚、これに限らず、収集されたワークロード指標は全てKubernetes Containerに紐づけられて表示される*10ので注意が必要です。
GKE指標収集の他の選択肢
殆どの要件では上記のワークロード指標で対応できますが、GKEからGKEクラスタがあるプロジェクトとは別のGoogle Cloudプロジェクトに指標を送信する必要がある場合など、特殊な要件には対応できない*11ので、その場合はStackdriver Collecterをデプロイする必要があります。この場合少し料金も高くなるので注意が必要です。
今回はワークロード指標でカバーできる範疇の要件だったのでそちらは利用しませんでした。
Slack通知
Slack通知も簡単に実装ができました。
Cloud Monitoringにはアラート機能があり*12、その中で特定の指標や閾値などを定めたアラートポリシーを設定し、閾値を設定した期間超えていたら通知するということができます。
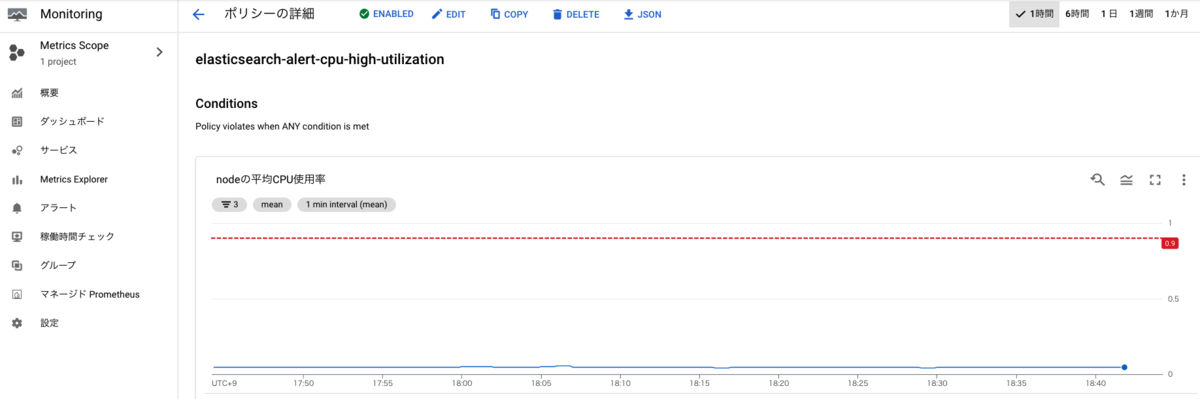
今回はSlack通知を実装しましたが、他にもEmailやPagerDuty、Cloud Pub/Subなど様々な通知先を設定できるのでいろんな要件に柔軟に対応できそうです。
最後に
いかがでしたでしょうか?
GCPでインフラ監視ツールを考える際の参考に少しでもなれば幸いです。
バイセルではエンジニアを募集しています。
明日の バイセルテクノロジーズ Advent Calendar 2021 は小松山さんの「Hasura でプロダクト開発をしてみて感じた良かったところ・辛かったところ」です。
ご覧いただき、ありがとうございました。
*1:https://cloud.google.com/run
*3:https://cloud.google.com/kubernetes-engine
*4:https://www.elastic.co/jp/elasticsearch/
*5:https://cloud.google.com/monitoring
*6:https://cloud.google.com/blog/ja/products/operations/managed-metric-collection-for-google-kubernetes-engine
*7:https://prometheus.io/docs/instrumenting/exporters/
*8:https://github.com/kubernetes/kube-state-metrics
*9:https://github.com/kubernetes/kube-state-metrics/tree/master/docs#exposed-metrics
*10:https://cloud.google.com/stackdriver/docs/solutions/gke/managing-metrics#confirm_metrics_are_collected_from_your_application
*11:https://cloud.google.com/stackdriver/docs/solutions/gke/prometheus?hl=ja
*12:https://cloud.google.com/monitoring/alerts/using-alerting-ui